Esta entrada es una fe de erratas de esta de hace casi dos años.
Lo de la colina viene porque Carlos me comentaba el otro día, que en mi entrada había algo raro, ya que era muy extraño que al resumir información el modelo fuera peor. Y efectivamente, había algo raro, cuándo se lo comenté y que me tocaba hacer una fe de erratas, me dijo que si no lo hacía ya tenía una “colina dónde morir”, lo cual no está mal del todo. Le conminé a que se explicara, en torno burlón evidentemente.
El tema es que hay gente que se aferra a una idea aunque luego se demuestre que estaban equivocados o que cometieron un error y muere en su pequeña colina defendiendo esa idea. No es mi costumbre aferrarme a mis ideas una vez se demuestran equivocadas (no, no pienso hablar de mis ideas políticas, porque para eso debería abrirme otro blog). Y bueno, hace poco alguien a quien aprecio me dijo que era muy borde, pero que no era cabezón, así que voy a comentar un poco los errores de la entrada de la codificación de variables categóricas.
El primer gran error en el post es, cómo no podía ser de otra, usar info del futuro para evaluar como de buenas eran las codificaciones mediante MCA o con embedding respecto a la codificación parcial (one-hot para los de la logse).
El tema es que construyo los modelos de MCA y de embedding usando el conjunto de datos completos, pero luego evalúo como de bien funcionan en un modelo en el que parto en entrenamiento y test. Así que en el entrenamiento estoy usando info del futuro, ya que parte de la estructura factorial (o los embeddings) se ha obtenido utilizando la información del test. Así que toca cambiar la función testRun para que tanto el MCA como el embedding se calculen sólo con los datos de entrenamiento.
Mostrar / ocultar código
testRun <-function(x) { sample <- caret::createDataPartition(df$weekDayF, list =FALSE, p =0.8) train <- df[sample,] test <- df[-sample,]#TODO El MCA y el embedding deben calcularse en train# y obtener las proeyecciones en test fit1 <-lm(Manhattan.Bridge ~ weekDayF, data = train) fit2 <-lm(Manhattan.Bridge ~ X1 + X2 + X3, data = train) fit3 <-lm(Manhattan.Bridge ~ MCA_1 + MCA_2 + MCA_3, data = train)data.frame(run = x,Categ =sqrt(mean((predict(fit1, test) - test$Manhattan.Bridge) ^2)),Embedding =sqrt(mean((predict(fit2, test) - test$Manhattan.Bridge) ^2)),Corresp =sqrt(mean((predict(fit3, test) - test$Manhattan.Bridge) ^2)) )}
No maltratemos al modelo base
El segundo gran error tiene que ver con una trampa que le hacemos al modelo base. Para el modelo base la única info que usamos para modelar la variable de usuarios de bici que cruzan el puente de Manhattan es el día de la semana. En cambio para el MCA y para el embedding usamos la relación que hay entre los usuarios que pasan por el puente de Brooklyn y el día de la semana.
Para ser justos, debería haber utilizado la relación de los usuarios con el puente de Manhattan o bien haber añadido la variable de los usuarios del puente de Brooklyn al modelo base.
Mostrar / ocultar código
testRun <-function(x) { sample <- caret::createDataPartition(df$weekDayF, list =FALSE, p =0.8) train <- df[sample,] test <- df[-sample,]#TODO El MCA y el embedding deben calcularse en train# y obtener las proeyecciones en test# Seamos justos con el modelo base, añadiendo la variable del puente de Brooklyn a # los 3 modelos fit1 <-lm(Manhattan.Bridge ~ weekDayF + Brooklyn.Bridge, data = train) fit2 <-lm(Manhattan.Bridge ~ X1 + X2 + X3 + Brooklyn.Bridge, data = train) fit3 <-lm(Manhattan.Bridge ~ MCA_1 + MCA_2 + MCA_3 + Brooklyn.Bridge, data = train)data.frame(run = x,Categ =sqrt(mean((predict(fit1, test) - test$Manhattan.Bridge) ^2)),Embedding =sqrt(mean((predict(fit2, test) - test$Manhattan.Bridge) ^2)),Corresp =sqrt(mean((predict(fit3, test) - test$Manhattan.Bridge) ^2)) )}
Detallitos
Y como tercer error, un pequeño detalle. Las variables obtenidas en el MCA no son las coordenadas obtenidas de la variable weekday en la estructura factorial, sino la predicción de nuevas filas, que tienen tanto weekday como los usuarios del puente de Manhattan (categorizado). Esto en principio no es ningún problema, pero estaría bien probar asignando sólo el valor del día de la semana proyectado en las componentes, sobre todo porque puede que en el test no tenga todas las combinaciones de día de la semana y los usuarios del puente de Manhattan categorizado que tenga en el train. Esta apreciación se la debo a Diego Serrano, ex compañero de curro y sin embargo amigo, que me la hizo en su día y tenía pendiente ponerlo.
Total, que en un próximo post pondré el código para corregir esto, que es domingo y lo que me toca es corregir ejercicios de alumnos. Ya no tengo colina dónde morir y toca abordar otros cerros.
PD
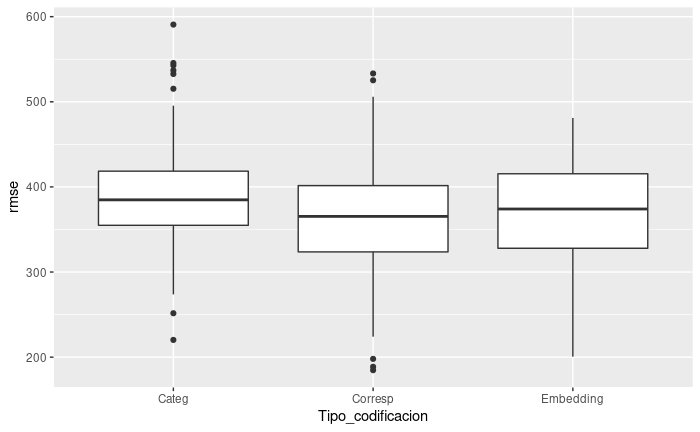
Por el momento dejo la comparación con parte de los errores corregidos. El MCA si que se obtiene sólo en train, pero el embedding aún está entrenado con todo, y se ha añadido la variable Manhattan.Bridge en la comparación de los 3 modelos.