Cachitos. Segunda parte
Nada, esto es sólo para leernos con R los subtítulos del post anterior.
library(tidyverse)
root_directory = "/media/hd1/canadasreche@gmail.com/public/proyecto_cachitos/"
anno <- "2021"
# Construims un data frame con los nombrs de los ficheros
nombre_ficheros <- list.files(path = str_glue("{root_directory}{anno}_txt/")) %>%
enframe() %>%
rename(n_fichero = value)
nombre_ficheros
#> # A tibble: 1,384 × 2
#> name n_fichero
#> <int> <chr>
#> 1 1 00000001.jpg.subtitulo.tif.txt
#> 2 2 00000002.jpg.subtitulo.tif.txt
#> 3 3 00000003.jpg.subtitulo.tif.txt
#> 4 4 00000004.jpg.subtitulo.tif.txt
#> 5 5 00000005.jpg.subtitulo.tif.txt
#> 6 6 00000006.jpg.subtitulo.tif.txt
#> 7 7 00000007.jpg.subtitulo.tif.txt
#> 8 8 00000008.jpg.subtitulo.tif.txt
#> 9 9 00000009.jpg.subtitulo.tif.txt
#> 10 10 00000010.jpg.subtitulo.tif.txt
#> # … with 1,374 more rowsAhora los podemos leer en orden
subtitulos <- list.files(path = str_glue("{root_directory}{anno}_txt/"),
pattern = "*.txt", full.names = TRUE) %>%
map(~read_file(.)) %>%
enframe() %>%
# hacemos el join con el dataframe anterior para tener el nombre del fichero original
left_join(nombre_ficheros)
glimpse(subtitulos)
#> Rows: 1,384
#> Columns: 3
#> $ name <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…
#> $ value <list> "\f", "\f", "FUN MÚSICA Y CINTAS DE VÍDEO\n\f", " \n\f", "\…
#> $ n_fichero <chr> "00000001.jpg.subtitulo.tif.txt", "00000002.jpg.subtitulo.ti…
subtitulos
#> # A tibble: 1,384 × 3
#> name value n_fichero
#> <int> <list> <chr>
#> 1 1 <chr [1]> 00000001.jpg.subtitulo.tif.txt
#> 2 2 <chr [1]> 00000002.jpg.subtitulo.tif.txt
#> 3 3 <chr [1]> 00000003.jpg.subtitulo.tif.txt
#> 4 4 <chr [1]> 00000004.jpg.subtitulo.tif.txt
#> 5 5 <chr [1]> 00000005.jpg.subtitulo.tif.txt
#> 6 6 <chr [1]> 00000006.jpg.subtitulo.tif.txt
#> 7 7 <chr [1]> 00000007.jpg.subtitulo.tif.txt
#> 8 8 <chr [1]> 00000008.jpg.subtitulo.tif.txt
#> 9 9 <chr [1]> 00000009.jpg.subtitulo.tif.txt
#> 10 10 <chr [1]> 00000010.jpg.subtitulo.tif.txt
#> # … with 1,374 more rowsen n_fichero tenemos el nombre y en value el texto
subtitulos %>%
pull(value) %>%
## usamos `[[` que es el operador para acceder a la lista el que normalemente se usa [[nombre_elemento]]
`[[`(16)
#> [1] "Ella resume a la perfección la filosofía de Cachitos:\nmontar “La fiesta” “Buscando en el baúl de los recuerdos”.\n\n \n\f"
# equivalentemente
# subtitulos %>%
# pull(value) %>%
# pluck(16)Como sabemos que hay muchos ficheros sin texto podemos contar letras.
subtitulos <- subtitulos %>%
mutate(n_caracteres = nchar(value))
subtitulos %>%
group_by(n_caracteres) %>%
count()
#> # A tibble: 128 × 2
#> # Groups: n_caracteres [128]
#> n_caracteres n
#> <int> <int>
#> 1 1 428
#> 2 3 97
#> 3 4 19
#> 4 5 13
#> 5 6 15
#> 6 7 8
#> 7 8 6
#> 8 9 3
#> 9 10 3
#> 10 11 2
#> # … with 118 more rows
subtitulos %>%
group_by(n_caracteres) %>%
count() %>%
ggplot(aes(x = n_caracteres, y = n)) +
geom_col()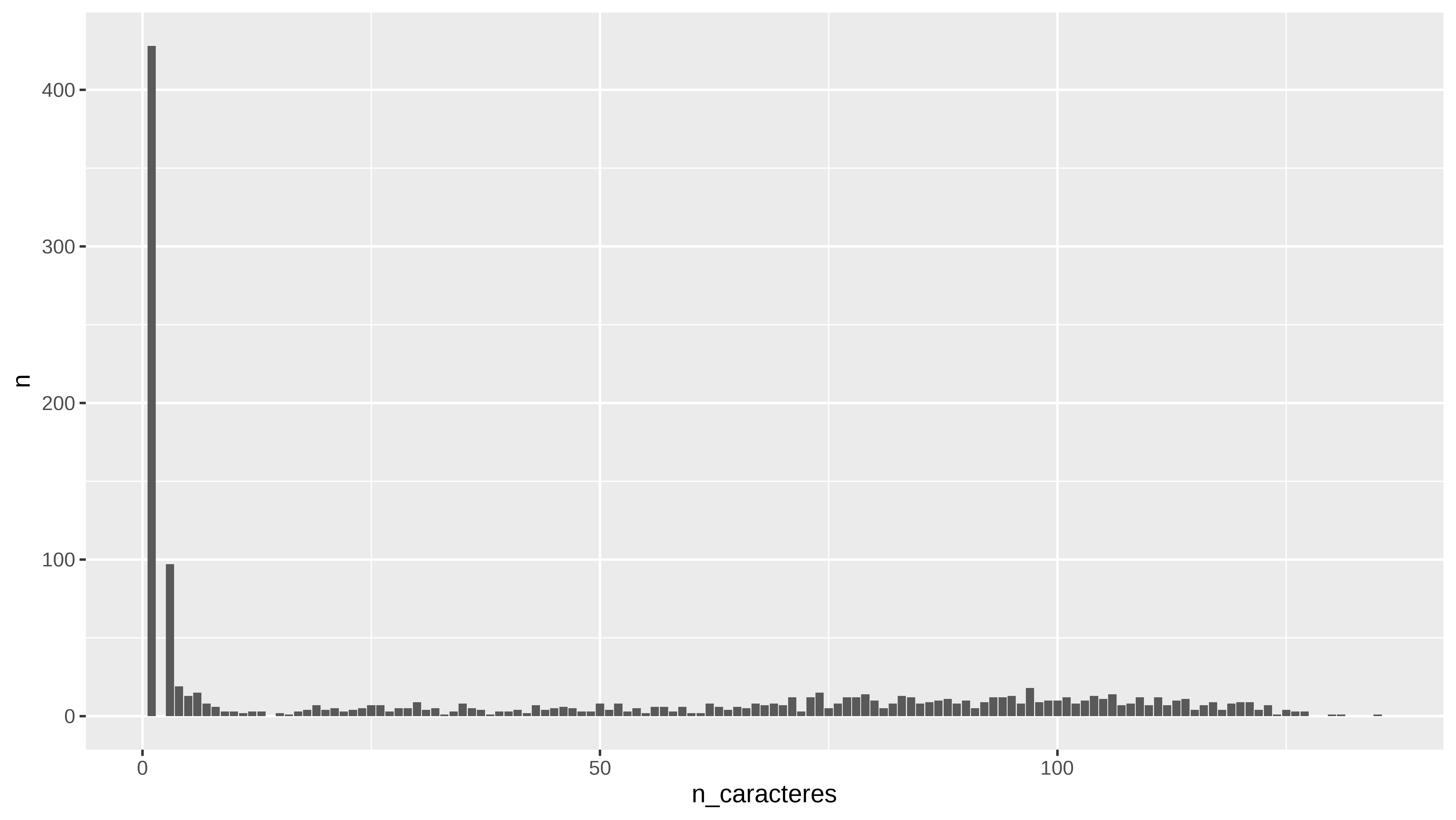
Y vemos que hay muchos subtitulos con pocos caracteres. Si vemos por ejemplo los que tienen menos de 12 caracteres
subtitulos %>%
filter(n_caracteres <12) %>%
pull(value) %>%
head(10)
#> [[1]]
#> [1] "\f"
#>
#> [[2]]
#> [1] "\f"
#>
#> [[3]]
#> [1] " \n\f"
#>
#> [[4]]
#> [1] "\f"
#>
#> [[5]]
#> [1] " \n\f"
#>
#> [[6]]
#> [1] " \n\f"
#>
#> [[7]]
#> [1] "\f"
#>
#> [[8]]
#> [1] "\f"
#>
#> [[9]]
#> [1] "\f"
#>
#> [[10]]
#> [1] "\f"Que se corresponden con haber pillado parte no del subtítulo sino del nombre de la actuación
subtitulos %>%
filter(n_caracteres ==15)
#> # A tibble: 2 × 4
#> name value n_fichero n_caracteres
#> <int> <list> <chr> <int>
#> 1 571 <chr [1]> 00000571.jpg.subtitulo.tif.txt 15
#> 2 1361 <chr [1]> 00001361.jpg.subtitulo.tif.txt 15Usando la librería magick en R que permite usar imagemagick en R, ver post de Raúl Vaquerizo y su homenaje a Sean Connery, podemos ver el fotgrama correspondiente
library(magick)
(directorio_imagenes <- str_glue("{root_directory}video/{anno}_jpg/"))
#> /media/hd1/canadasreche@gmail.com/public/proyecto_cachitos/video/2021_jpg/
image_read(str_glue("{directorio_imagenes}00000018.jpg"))
También podemos ver hasta cuando pasa eso, por ejemplo si vemos subtítulos con 18 caracteres
subtitulos %>%
filter(n_caracteres ==18) %>%
pull(value)
#> [[1]]
#> [1] " \n\nJ0 EN EL AMOR\n\f"
#>
#> [[2]]
#> [1] "¿EDITH BROOKS\nch\n\f"
#>
#> [[3]]
#> [1] " \n\nmme Tha Power\n\f"
#>
#> [[4]]
#> [1] " \n\n\"RONTERA\n\n \n\f"subtitulos <- subtitulos %>%
filter(n_caracteres > 17)
glimpse(subtitulos)
#> Rows: 778
#> Columns: 4
#> $ name <int> 3, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 27, 28, 29, 30…
#> $ value <list> "FUN MÚSICA Y CINTAS DE VÍDEO\n\f", "El servicio meteoro…
#> $ n_fichero <chr> "00000003.jpg.subtitulo.tif.txt", "00000014.jpg.subtitulo…
#> $ n_caracteres <int> 30, 118, 82, 117, 117, 25, 100, 97, 86, 88, 84, 43, 52, 8…Con el fin de detectar cuáles están duplicados y aprovechando que están en orden de aparición, podemos hacer utilizar distancias de texto para calcular la distancia de cada subtítulo con el anterior, y si la distancia es pequeña es que es el mismo rótulo.
Primero hacemos una mini-limpieza.
string_mini_clean <- function(string){
string <- gsub("?\n|\n", " ", string)
string <- gsub("\r|?\f|=", " ", string)
string <- gsub('“|”|—|>'," ", string)
string <- gsub("[[:punct:][:blank:]]+", " ", string)
string <- tolower(string)
string <- gsub(" ", " ", string)
return(string)
}
# Haciendo uso de programacion funciona con purrr es muy fácil pasar esta función a cada elemento. y decirle que # el reultado es string con map_chr
subtitulos_proces <- subtitulos %>%
mutate(texto = map_chr(value, string_mini_clean)) %>%
select(-value)
subtitulos_proces %>%
select(texto)
#> # A tibble: 778 × 1
#> texto
#> <chr>
#> 1 "fun música y cintas de vídeo "
#> 2 "el servicio meteorológico de cachitos informa se prevén vientos de fiesta m…
#> 3 "no es para menos llevamos dos años conformándonos solo con aires de siesta "
#> 4 "ella resume a la perfección la filosofía de cachitos montar la fiesta busca…
#> 5 " ella resume a la perfección la filosofía de cachitos montar la fiesta busc…
#> 6 " oncé a2y in love "
#> 7 "esperamos que tengáis una tele bien grande no sabemos si cabrá tanto flow e…
#> 8 "liberté egalité fraternité vacunaté y beyoncé la lola flores negra ejercien…
#> 9 "mirad su pelo ya os dijimos que el aire de fiesta iba a soplar fuerte esta …
#> 10 "mirad su pelo ya os dijimos que el aire de fiesta iba a soplar fuerte esta …
#> # … with 768 more rowsY ya vemos a simple vista que hay algun duplicado. Calculemos ahora la distancia de strings, utilizando la función stringdist de la librería del mismo nombre.
subtitulos_proces %>%
mutate(texto_anterior = lag(texto)) %>%
# calculamos distancias con método lcs (que no me he leído que hace exactamente)
mutate(distancia = stringdist::stringdist(texto, texto_anterior, method = "lcs")) %>%
# veamos algunos elementos
filter(distancia < 19) %>%
arrange(desc(distancia) ) %>%
select(texto, texto_anterior, distancia)
#> # A tibble: 89 × 3
#> texto texto…¹ dista…²
#> <chr> <chr> <dbl>
#> 1 " la rosalía emérita " " alía… 18
#> 2 "chango llegó a españa como aspirante a estrella del rock y … "chang… 15
#> 3 "leonard cohen y el pitufo gruñón en el cuerpo de un italian… "leona… 13
#> 4 " el stress del año 2000 nos llegó con casi 20 os de retraso… " el s… 7
#> 5 "aquí ya llevaba cuatro años de carrera luis miguel tiene má… "aquí … 7
#> 6 "imborrable siempre la sonrisa de jerry aunque un poco incóm… "la im… 6
#> 7 "7 literalmente significa puedes tocarme la campanita funcio… "liter… 6
#> 8 " las palabras no vienen fácilmente paradójicamente no fue e… " las … 5
#> 9 "en españa el g arm nació ya vintage porque el británico nos… "en es… 5
#> 10 "nosotros también lo sentimos si alguien se ofende y en nues… " 4 no… 5
#> # … with 79 more rows, and abbreviated variable names ¹texto_anterior,
#> # ²distanciaY parece que funciona. Así que decido quitar las filas dónde la distancia sea menos que 19 y así eliminar muchos de los duplicados.
subtitulos_proces <- subtitulos_proces %>%
mutate(texto_anterior = lag(texto)) %>%
mutate(distancia = stringdist::stringdist(texto, texto_anterior, method = "lcs")) %>%
filter(distancia > 19) %>%
select(-texto_anterior)
subtitulos_proces %>%
head()
#> # A tibble: 6 × 5
#> name n_fichero n_caracteres texto dista…¹
#> <int> <chr> <int> <chr> <dbl>
#> 1 14 00000014.jpg.subtitulo.tif.txt 118 "el servicio meteor… 106
#> 2 15 00000015.jpg.subtitulo.tif.txt 82 "no es para menos l… 110
#> 3 16 00000016.jpg.subtitulo.tif.txt 117 "ella resume a la p… 102
#> 4 18 00000018.jpg.subtitulo.tif.txt 25 " oncé a2y in love " 100
#> 5 19 00000019.jpg.subtitulo.tif.txt 100 "esperamos que teng… 92
#> 6 20 00000020.jpg.subtitulo.tif.txt 97 "liberté egalité fr… 105
#> # … with abbreviated variable name ¹distanciawrite_csv(subtitulos_proces,
file = str_glue("{root_directory}{anno}_txt_unido.csv"))