library(tidyverse)
root_directory = "/media/hd1/canadasreche@gmail.com/public/proyecto_cachitos/"
anno <- "2022"
nombre_ficheros <- list.files(path = str_glue("{root_directory}{anno}_txt/")) %>%
enframe() %>%
rename(n_fichero = value)
nombre_ficheros
#> # A tibble: 1,302 × 2
#> name n_fichero
#> <int> <chr>
#> 1 1 00000001.jpg.subtitulo.tif.txt
#> 2 2 00000002.jpg.subtitulo.tif.txt
#> 3 3 00000003.jpg.subtitulo.tif.txt
#> 4 4 00000004.jpg.subtitulo.tif.txt
#> 5 5 00000005.jpg.subtitulo.tif.txt
#> 6 6 00000006.jpg.subtitulo.tif.txt
#> 7 7 00000007.jpg.subtitulo.tif.txt
#> 8 8 00000008.jpg.subtitulo.tif.txt
#> 9 9 00000009.jpg.subtitulo.tif.txt
#> 10 10 00000010.jpg.subtitulo.tif.txt
#> # … with 1,292 more rowsCachitos 2022. Segunda parte
estadística
polémica
2023
textmining
ocr
linux
cachitos
Una vez que ya hemos visto en la entrada anterior como extraer los rótulos, vamos a juntarlos todos en un sólo csv y hacer algo de limpieza.
Dejo el enlace a los ficheros de texto construidos por tesseract enlace directorio
Lectura rótulos
Ahora los podemos leer en orden
subtitulos <- list.files(path = str_glue("{root_directory}{anno}_txt/"),
pattern = "*.txt", full.names = TRUE) %>%
map(~read_file(.)) %>%
enframe() %>%
left_join(nombre_ficheros)
glimpse(subtitulos)
#> Rows: 1,302
#> Columns: 3
#> $ name <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…
#> $ value <list> "\f", "\f", " \n\f", "\f", " \n\f", " \n\f", "\f", "\f", …
#> $ n_fichero <chr> "00000001.jpg.subtitulo.tif.txt", "00000002.jpg.subtitulo.ti…
subtitulos
#> # A tibble: 1,302 × 3
#> name value n_fichero
#> <int> <list> <chr>
#> 1 1 <chr [1]> 00000001.jpg.subtitulo.tif.txt
#> 2 2 <chr [1]> 00000002.jpg.subtitulo.tif.txt
#> 3 3 <chr [1]> 00000003.jpg.subtitulo.tif.txt
#> 4 4 <chr [1]> 00000004.jpg.subtitulo.tif.txt
#> 5 5 <chr [1]> 00000005.jpg.subtitulo.tif.txt
#> 6 6 <chr [1]> 00000006.jpg.subtitulo.tif.txt
#> 7 7 <chr [1]> 00000007.jpg.subtitulo.tif.txt
#> 8 8 <chr [1]> 00000008.jpg.subtitulo.tif.txt
#> 9 9 <chr [1]> 00000009.jpg.subtitulo.tif.txt
#> 10 10 <chr [1]> 00000010.jpg.subtitulo.tif.txt
#> # … with 1,292 more rowsTenemos 1302 rótulos de los cuales la mayoría estarán vacíos
Contando letras
En n_fichero tenemos el nombre y en value el texto. Si vemos alguno de los subtítulos.
subtitulos %>%
pull(value) %>%
pluck(946)
#> [1] "Izquierda... Derecha... Como veis, tienen la postura tan\nsólidamente definida como el gobierno respecto al Sahara.\n\n \n\f"Muchos de los ficheros no tienen texto (son fotogramas sin rótulos). Contemos letras.
subtitulos <- subtitulos %>%
mutate(n_caracteres = nchar(value))
subtitulos %>%
group_by(n_caracteres) %>%
count()
#> # A tibble: 131 × 2
#> # Groups: n_caracteres [131]
#> n_caracteres n
#> <int> <int>
#> 1 1 487
#> 2 3 118
#> 3 4 12
#> 4 5 14
#> 5 6 6
#> 6 7 4
#> 7 8 5
#> 8 9 3
#> 9 10 3
#> 10 11 4
#> # … with 121 more rows
subtitulos %>%
group_by(n_caracteres) %>%
count() %>%
ggplot(aes(x = n_caracteres, y = n)) +
geom_col()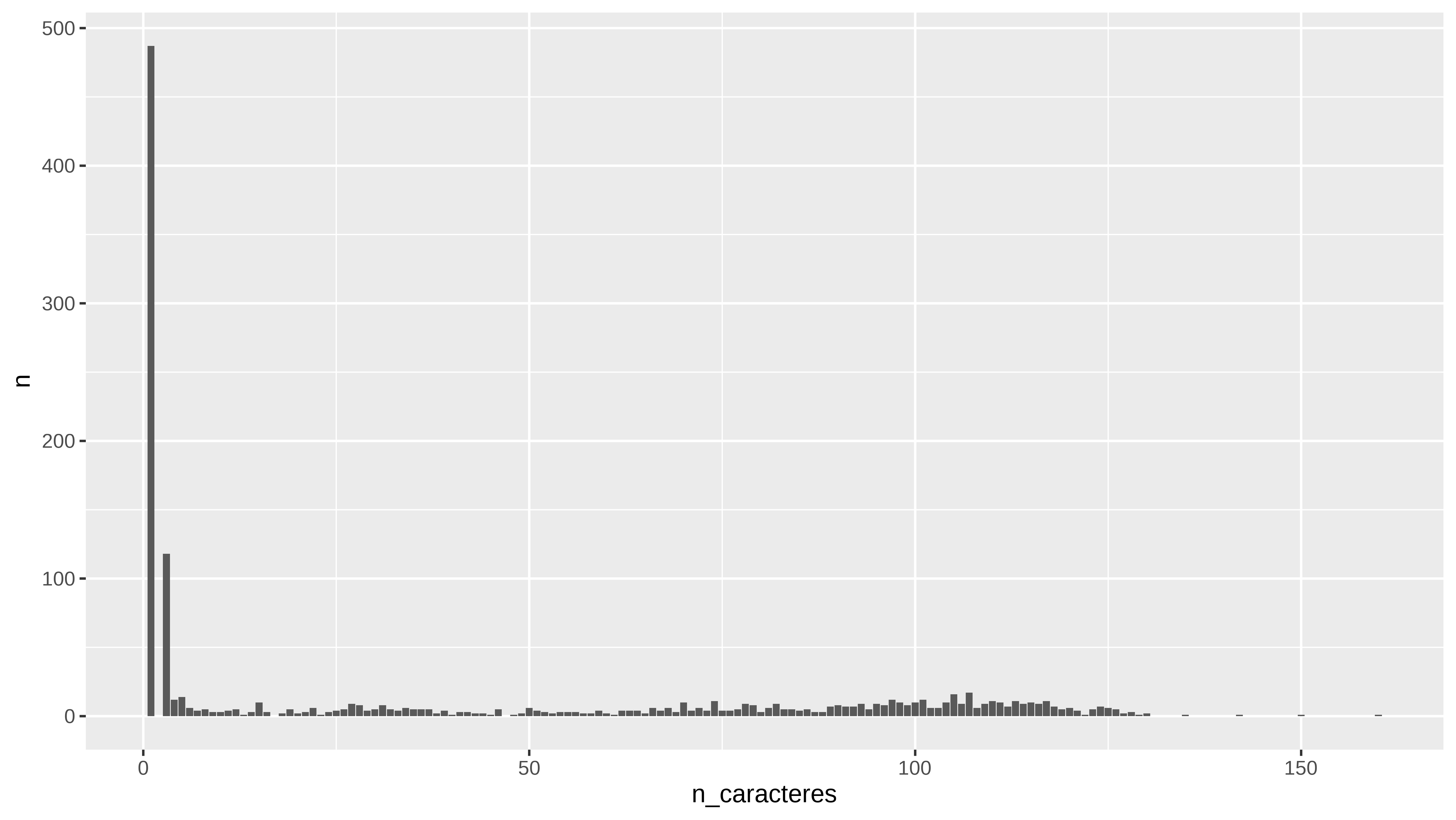
Y viendo el conteo podríamos ver cómo son los rótulos con menos de 25 caracteres. Y suele ser por haber pillado el nombre de la canción en vez del rótulo
subtitulos %>%
filter(n_caracteres <= 25, n_caracteres > 0 ) %>%
arrange(desc(n_caracteres)) %>%
head(40) %>%
pull(value)
#> [[1]]
#> [1] " \n\nMÁRQUEZ PIQUER YN\n\nY\n\f"
#>
#> [[2]]
#> [1] "DRES DO BARRO\n\n¡deirada\n\f"
#>
#> [[3]]
#> [1] " \n\n¡A DORTA e\nna O” A —\n\f"
#>
#> [[4]]
#> [1] "MBERROS UNIDOS\n\nIderete\n\f"
#>
#> [[5]]
#> [1] "LIE IMBRUGLIA Lp]\n-n ]\n\f"
#>
#> [[6]]
#> [1] "E? EPR ENOAMADO\nENCADo\n\f"
#>
#> [[7]]
#> [1] "IO DALLA\n\na La Vita\n\n \n\f"
#>
#> [[8]]
#> [1] "O VENENO\n\n10 de menos\n\f"
#>
#> [[9]]
#> [1] "IL MCCARTNEY\n\nis One\n\f"
#>
#> [[10]]
#> [1] "'HAEL\n\n1é sabe nadie\n\f"
#>
#> [[11]]
#> [1] " \n\nGEES ca z a\njan\n\f"
#>
#> [[12]]
#> [1] " \n\nk\nA BELÉN [\napimó\n\f"
#>
#> [[13]]
#> [1] "RIGO CUEVAS\n\nbrujada\n\f"
#>
#> [[14]]
#> [1] "LETS\n\neased Lighting\n\f"
#>
#> [[15]]
#> [1] "3EL PANTOJA\n\nrlochí\n\f"
#>
#> [[16]]
#> [1] " \n\nMR banda LL Ú\n\n \n\f"
#>
#> [[17]]
#> [1] "ANDA LEAR\n\nrfomania\n\f"
#>
#> [[18]]
#> [1] " \n\nOCOLATE\n\nyonesa\n\f"
#>
#> [[19]]
#> [1] "IS\nFrom Désire\n\n \n\f"
#>
#> [[20]]
#> [1] ": ENEMIGOS\n1 Vane\n\f"
#>
#> [[21]]
#> [1] "RAN DURAN\nld Boys\n\f"
#>
#> [[22]]
#> [1] "SHOP BOYS\n\nsurbia\n\f"
#>
#> [[23]]
#> [1] "Sería el momen\n\n \n\f"
#>
#> [[24]]
#> [1] "Boney M y Tigrete\n\f"
#>
#> [[25]]
#> [1] "IO FUTURA\nGrados\n\f"
#>
#> [[26]]
#> [1] " \n\nSSIEL\n\nrinero\n\f"
#>
#> [[27]]
#> [1] "ACIA MONTES\n\n \n\f"
#>
#> [[28]]
#> [1] " \n\n) SUAVES\n\n \n\f"
#>
#> [[29]]
#> [1] " \n\nhe Ye ke\n\n \n\f"
#>
#> [[30]]
#> [1] "UCambDatlacne\n\f"
#>
#> [[31]]
#> [1] "1,0616 EDAD |\n\f"
#>
#> [[32]]
#> [1] "¡GE URE\n\nathe\n\f"
#>
#> [[33]]
#> [1] "NA\nMustafá\n\n \n\f"
#>
#> [[34]]
#> [1] "AGO\n\nmbamanía\n\f"
#>
#> [[35]]
#> [1] ",\nLuftballons\n\f"
#>
#> [[36]]
#> [1] "SURE\n\nmetimes\n\f"
#>
#> [[37]]
#> [1] " \n\nDMA\n\nnbada\n\f"
#>
#> [[38]]
#> [1] "ENDI\nEDI O\n\n \n\f"
#>
#> [[39]]
#> [1] "oo “Brisp\n\nyr\n\f"
#>
#> [[40]]
#> [1] " \n\nPEEBLES\nn\n\f"subtitulos %>%
filter(n_caracteres == 30)
#> # A tibble: 5 × 4
#> name value n_fichero n_caracteres
#> <int> <list> <chr> <int>
#> 1 98 <chr [1]> 00000098.jpg.subtitulo.tif.txt 30
#> 2 409 <chr [1]> 00000409.jpg.subtitulo.tif.txt 30
#> 3 882 <chr [1]> 00000882.jpg.subtitulo.tif.txt 30
#> 4 1018 <chr [1]> 00001018.jpg.subtitulo.tif.txt 30
#> 5 1258 <chr [1]> 00001258.jpg.subtitulo.tif.txt 30Usando la librería magick en R que permite usar imagemagick en R, ver post de Raúl Vaquerizo y su homenaje a Sean Connery, podemos ver el fotgrama correspondiente
library(magick)
(directorio_imagenes <- str_glue("{root_directory}video/{anno}_jpg/"))
#> /media/hd1/canadasreche@gmail.com/public/proyecto_cachitos/video/2022_jpg/
image_read(str_glue("{directorio_imagenes}00001258.jpg"))
Así que nos quedamos con los rótulos con más de 30 caracteres
subtitulos <- subtitulos %>%
filter(n_caracteres > 30)
dim(subtitulos)
#> [1] 567 4Detección duplicados
Mini limpieza de caracteres extraños y puntuación
string_mini_clean <- function(string){
string <- gsub("?\n|\n", " ", string)
string <- gsub("\r|?\f|=", " ", string)
string <- gsub('“|”|—|>'," ", string)
string <- gsub("[[:punct:][:blank:]]+", " ", string)
string <- tolower(string)
string <- gsub(" ", " ", string)
return(string)
}
# Haciendo uso de programación funciona con purrr es muy fácil pasar esta función a cada elemento. y decirle que
# el resultado es string con map_chr
subtitulos_proces <- subtitulos %>%
mutate(texto = map_chr(value, string_mini_clean)) %>%
select(-value)
subtitulos_proces %>%
select(texto)
#> # A tibble: 567 × 1
#> texto
#> <chr>
#> 1 "3 pues te vas a reír cuando sepas an lo que pasa en el xxi "
#> 2 " bienvenidos si estáis todos es porque habéis recordado que tras los cuarto…
#> 3 "bueno si eres colchonero al menos estás acostumbrado a los disgustos "
#> 4 " faella carrá jn e el amor todo es empezar 3 "
#> 5 "en cachitos como en el amor y en el rascar todo es empezar os quedan tres h…
#> 6 "esta actuación contiene más latigazos cervicales 32 que una colisión en cad…
#> 7 "la oración pagana que todos hemos rezado mucha ms "
#> 8 "la oración pagana que todos hemos rezado muchas más veces de las que nos gu…
#> 9 "aquel año el cádiz descendió a 2 b y creemos que bisbal no tuvo nada que ve…
#> 10 " ha llegado ya el momento de abrir el melón de que este muchacho canta raro…
#> # … with 557 more rowsDistancia de texto entre rótulos consecutivos
subtitulos_proces <- subtitulos_proces %>%
mutate(texto_anterior = lag(texto)) %>%
mutate(distancia = stringdist::stringdist(texto, texto_anterior, method = "lcs"))
subtitulos_proces %>%
filter(!is.na(distancia)) %>%
select(name,texto,distancia, texto_anterior, everything()) %>%
arrange(distancia) %>%
DT::datatable()Decidimos eliminar texto cuya distancia sea menor de 36
subtitulos_proces <- subtitulos_proces %>%
filter(distancia > 36) %>%
select(-texto_anterior)
subtitulos_proces %>%
select(name,texto, everything()) %>%
DT::datatable()No nos hemos quitado todos los duplicados pero sí algunos de ellos.
dim(subtitulos_proces)
#> [1] 488 5Guardamos el fichero unido
write_csv(subtitulos_proces,
file = str_glue("{root_directory}{anno}_txt_unido.csv"))Y aquí os dejo el enlace con los rótulos definitivos