Mostrar / ocultar código
library(tidyverse)
library(ranger)
# ya veremos para que usamos furrr y FactoMineR
library(furrr)
library(FactoMineR)
library(factoextra)Buscando en el portátil sobre otras cosas me he encontrado un pequeño ejercicio para implementar la idea que se comenta aquí
La idea es muy sencilla, tal y como comenta Carlos. Si tengo un modelo que sea tipo randomForest
Antes de nada, sí, ya sé que existen cosas como los shap values y que a partir de ellos se puede hacer algo parecido. Pero no está de más de vez en cuando buscarse uno las habichueleas de forma más artesanal..
Pues ale, vamos a hacerlo con iris, tan denostado hoy en día. Pobre Fisher o Anderson si levantaran la cabeza.
library(tidyverse)
library(ranger)
# ya veremos para que usamos furrr y FactoMineR
library(furrr)
library(FactoMineR)
library(factoextra)
# 5 arbolitos tiene mi..
set.seed(47)
rg_iris <- ranger(Species ~ . , data = iris, num.trees = 5)Info del árbol 3
(arbol3 <- treeInfo(rg_iris, tree = 3))
#> nodeID leftChild rightChild splitvarID splitvarName splitval terminal
#> 1 0 1 2 0 Sepal.Length 5.55 FALSE
#> 2 1 3 4 2 Petal.Length 2.45 FALSE
#> 3 2 5 6 3 Petal.Width 1.70 FALSE
#> 4 3 NA NA NA <NA> NA TRUE
#> 5 4 7 8 2 Petal.Length 4.25 FALSE
#> 6 5 9 10 1 Sepal.Width 3.60 FALSE
#> 7 6 11 12 0 Sepal.Length 6.00 FALSE
#> 8 7 NA NA NA <NA> NA TRUE
#> 9 8 NA NA NA <NA> NA TRUE
#> 10 9 13 14 2 Petal.Length 4.95 FALSE
#> 11 10 NA NA NA <NA> NA TRUE
#> 12 11 15 16 2 Petal.Length 4.85 FALSE
#> 13 12 NA NA NA <NA> NA TRUE
#> 14 13 NA NA NA <NA> NA TRUE
#> 15 14 17 18 3 Petal.Width 1.55 FALSE
#> 16 15 NA NA NA <NA> NA TRUE
#> 17 16 NA NA NA <NA> NA TRUE
#> 18 17 NA NA NA <NA> NA TRUE
#> 19 18 19 20 2 Petal.Length 5.45 FALSE
#> 20 19 NA NA NA <NA> NA TRUE
#> 21 20 NA NA NA <NA> NA TRUE
#> prediction
#> 1 <NA>
#> 2 <NA>
#> 3 <NA>
#> 4 setosa
#> 5 <NA>
#> 6 <NA>
#> 7 <NA>
#> 8 versicolor
#> 9 virginica
#> 10 <NA>
#> 11 setosa
#> 12 <NA>
#> 13 virginica
#> 14 versicolor
#> 15 <NA>
#> 16 versicolor
#> 17 virginica
#> 18 virginica
#> 19 <NA>
#> 20 versicolor
#> 21 virginicaAnalizando un poco, vemos que el nodo raíz (0) se parte por la variable Sepal.Length. Luego el nodo 1 se bifurca a la izquierda hacia el 3 y a la derecha hacia el 4, siendo Petal.Length la variable que decide esa partición.
La idea sería recorrer el árbol partiendo de un nodo terminal y ver qué camino ha seguido. Para eso hacemos el siguiente código
Hacemos un ejemplo, partiendo del nodo terminal 8
Camino del Nodo 8
nodo_terminal <- 8
nodos <- nodo_terminal # vamos a ir sobreescribiendo la variable nodos hasta llegar al nodo raíz 0
variables <- vector() # guardamos el nombre de las variables de split
while (!0 %in% nodos) {
tmp <- arbol3 %>%
filter(leftChild %in% nodos |
rightChild %in% nodos)
print(str_glue("Nodo hijo: {nodos}"))
nodos <- unique(tmp$nodeID)
print(str_glue("Nodo padre: {nodos}"))
print(str_glue("variable de split en nodo padre: {tmp$splitvarName}"))
variables <- c(variables, unique(tmp$splitvarName)) # la última variable de este vector es la que está más arriba en el árbol
}
#> Nodo hijo: 8
#> Nodo padre: 4
#> variable de split en nodo padre: Petal.Length
#> Nodo hijo: 4
#> Nodo padre: 1
#> variable de split en nodo padre: Petal.Length
#> Nodo hijo: 1
#> Nodo padre: 0
#> variable de split en nodo padre: Sepal.LengthY vemos que para llegar al nodo terminal 8 ha utilizado dos veces la variable Petal.Length y una la variable Sepal.Length
Nos creamos una funcioncita para esto, donde al final construyo un data.frame donde guardo eel nodo terminal que estamos investigando, las variables que se han usado para llegar a ese nodo y una variable peso que se calcula asignando un peso igual 1 a la variable que está más alta en el árbol y menos a las demás. Si hay 4 variables se crea un vector c(4,3,2,1) en orden de más alta en el árbol a más baja y se divide por el número de variables. así se tendrían estos pesos 1, 0.75, 0.5, 0.25
extraerVariables_nodos <- function(nodo_terminal, info_arbol) {
nodos <- nodo_terminal
variables <- vector()
while (!0 %in% nodos) {
tmp <- info_arbol %>%
filter(leftChild %in% nodos |
rightChild %in% nodos)
variables <- c(variables, unique(tmp$splitvarName))
nodos <- unique(tmp$nodeID)
}
return(
data.frame(
nodo_terminal = nodo_terminal,
variables = variables,
peso = seq_along(variables) / sum(length(variables))
)
)
}Comprobamos
extraerVariables_nodos(nodo_terminal = 8, info_arbol = arbol3)
#> nodo_terminal variables peso
#> 1 8 Petal.Length 0.3333333
#> 2 8 Petal.Length 0.6666667
#> 3 8 Sepal.Length 1.0000000Ok. Lo suyo sería extraer la misma info pero para cada nodo terminal del árbol que estamos considerando. Pues nos creamos la funcioncita, que dado un modelo y un número de árbol, saque la info anterior para todos los nodos terminales
extraerVariablePorArbol <- function(modelo, arbol, verbose = FALSE) {
info_arbol <- treeInfo(modelo, arbol)
nodos_terminales <- treeInfo(modelo, arbol) %>%
filter(terminal == TRUE) %>%
pull(nodeID) %>%
unique()
if(verbose) print(nodos_terminales)
variables_por_arbol <- map_df(
nodos_terminales,
function(nodos) {
extraerVariables_nodos(nodos, info_arbol)
}
)
variables_por_arbol$arbol <- arbol
variables_por_arbol
}Comprobemos
# arbol 3
(importancia_individual_arbol3 <- extraerVariablePorArbol(rg_iris, 3))
#> nodo_terminal variables peso arbol
#> 1 3 Petal.Length 0.5000000 3
#> 2 3 Sepal.Length 1.0000000 3
#> 3 7 Petal.Length 0.3333333 3
#> 4 7 Petal.Length 0.6666667 3
#> 5 7 Sepal.Length 1.0000000 3
#> 6 8 Petal.Length 0.3333333 3
#> 7 8 Petal.Length 0.6666667 3
#> 8 8 Sepal.Length 1.0000000 3
#> 9 10 Sepal.Width 0.3333333 3
#> 10 10 Petal.Width 0.6666667 3
#> 11 10 Sepal.Length 1.0000000 3
#> 12 12 Sepal.Length 0.3333333 3
#> 13 12 Petal.Width 0.6666667 3
#> 14 12 Sepal.Length 1.0000000 3
#> 15 13 Petal.Length 0.2500000 3
#> 16 13 Sepal.Width 0.5000000 3
#> 17 13 Petal.Width 0.7500000 3
#> 18 13 Sepal.Length 1.0000000 3
#> 19 15 Petal.Length 0.2500000 3
#> 20 15 Sepal.Length 0.5000000 3
#> 21 15 Petal.Width 0.7500000 3
#> 22 15 Sepal.Length 1.0000000 3
#> 23 16 Petal.Length 0.2500000 3
#> 24 16 Sepal.Length 0.5000000 3
#> 25 16 Petal.Width 0.7500000 3
#> 26 16 Sepal.Length 1.0000000 3
#> 27 17 Petal.Width 0.2000000 3
#> 28 17 Petal.Length 0.4000000 3
#> 29 17 Sepal.Width 0.6000000 3
#> 30 17 Petal.Width 0.8000000 3
#> 31 17 Sepal.Length 1.0000000 3
#> 32 19 Petal.Length 0.1666667 3
#> 33 19 Petal.Width 0.3333333 3
#> 34 19 Petal.Length 0.5000000 3
#> 35 19 Sepal.Width 0.6666667 3
#> 36 19 Petal.Width 0.8333333 3
#> 37 19 Sepal.Length 1.0000000 3
#> 38 20 Petal.Length 0.1666667 3
#> 39 20 Petal.Width 0.3333333 3
#> 40 20 Petal.Length 0.5000000 3
#> 41 20 Sepal.Width 0.6666667 3
#> 42 20 Petal.Width 0.8333333 3
#> 43 20 Sepal.Length 1.0000000 3Solo queda extraer lo mismo pero para cada arbolito
extraerVariablesPorModelo <- function(modelo, parallel = TRUE) {
arboles <- modelo$num.trees
if (parallel) {
# Si hay muchos árboles usamos procesamiento en paralelo
future::plan(multisession)
furrr::future_map_dfr(
seq_len(arboles),
function(arbol) {
extraerVariablePorArbol(modelo, arbol = arbol)
}
)
} else{
map_df(
seq_len(arboles),
function(arbol) {
extraerVariablePorArbol(modelo, arbol = arbol)
}
)
}
}(importancia_individual_todos_arboles <- extraerVariablesPorModelo(rg_iris, parallel = FALSE))
#> nodo_terminal variables peso arbol
#> 1 1 Petal.Width 1.0000000 1
#> 2 5 Petal.Length 0.3333333 1
#> 3 5 Petal.Width 0.6666667 1
#> 4 5 Petal.Width 1.0000000 1
#> 5 8 Petal.Width 0.3333333 1
#> 6 8 Petal.Width 0.6666667 1
#> 7 8 Petal.Width 1.0000000 1
#> 8 9 Petal.Width 0.2500000 1
#> 9 9 Petal.Length 0.5000000 1
#> 10 9 Petal.Width 0.7500000 1
#> 11 9 Petal.Width 1.0000000 1
#> 12 10 Petal.Width 0.2500000 1
#> 13 10 Petal.Length 0.5000000 1
#> 14 10 Petal.Width 0.7500000 1
#> 15 10 Petal.Width 1.0000000 1
#> 16 11 Petal.Length 0.2500000 1
#> 17 11 Petal.Width 0.5000000 1
#> 18 11 Petal.Width 0.7500000 1
#> 19 11 Petal.Width 1.0000000 1
#> 20 12 Petal.Length 0.2500000 1
#> 21 12 Petal.Width 0.5000000 1
#> 22 12 Petal.Width 0.7500000 1
#> 23 12 Petal.Width 1.0000000 1
#> 24 3 Petal.Width 0.5000000 2
#> 25 3 Sepal.Length 1.0000000 2
#> 26 4 Petal.Width 0.5000000 2
#> 27 4 Sepal.Length 1.0000000 2
#> 28 8 Sepal.Width 0.3333333 2
#> 29 8 Petal.Width 0.6666667 2
#> 30 8 Sepal.Length 1.0000000 2
#> 31 10 Sepal.Length 0.3333333 2
#> 32 10 Petal.Width 0.6666667 2
#> 33 10 Sepal.Length 1.0000000 2
#> 34 11 Petal.Length 0.2500000 2
#> 35 11 Sepal.Width 0.5000000 2
#> 36 11 Petal.Width 0.7500000 2
#> 37 11 Sepal.Length 1.0000000 2
#> 38 13 Sepal.Width 0.2500000 2
#> 39 13 Sepal.Length 0.5000000 2
#> 40 13 Petal.Width 0.7500000 2
#> 41 13 Sepal.Length 1.0000000 2
#> 42 14 Sepal.Width 0.2500000 2
#> 43 14 Sepal.Length 0.5000000 2
#> 44 14 Petal.Width 0.7500000 2
#> 45 14 Sepal.Length 1.0000000 2
#> 46 15 Sepal.Width 0.2000000 2
#> 47 15 Petal.Length 0.4000000 2
#> 48 15 Sepal.Width 0.6000000 2
#> 49 15 Petal.Width 0.8000000 2
#> 50 15 Sepal.Length 1.0000000 2
#> 51 17 Sepal.Width 0.1666667 2
#> 52 17 Sepal.Width 0.3333333 2
#> 53 17 Petal.Length 0.5000000 2
#> 54 17 Sepal.Width 0.6666667 2
#> 55 17 Petal.Width 0.8333333 2
#> 56 17 Sepal.Length 1.0000000 2
#> 57 18 Sepal.Width 0.1666667 2
#> 58 18 Sepal.Width 0.3333333 2
#> 59 18 Petal.Length 0.5000000 2
#> 60 18 Sepal.Width 0.6666667 2
#> 61 18 Petal.Width 0.8333333 2
#> 62 18 Sepal.Length 1.0000000 2
#> 63 3 Petal.Length 0.5000000 3
#> 64 3 Sepal.Length 1.0000000 3
#> 65 7 Petal.Length 0.3333333 3
#> 66 7 Petal.Length 0.6666667 3
#> 67 7 Sepal.Length 1.0000000 3
#> 68 8 Petal.Length 0.3333333 3
#> 69 8 Petal.Length 0.6666667 3
#> 70 8 Sepal.Length 1.0000000 3
#> 71 10 Sepal.Width 0.3333333 3
#> 72 10 Petal.Width 0.6666667 3
#> 73 10 Sepal.Length 1.0000000 3
#> 74 12 Sepal.Length 0.3333333 3
#> 75 12 Petal.Width 0.6666667 3
#> 76 12 Sepal.Length 1.0000000 3
#> 77 13 Petal.Length 0.2500000 3
#> 78 13 Sepal.Width 0.5000000 3
#> 79 13 Petal.Width 0.7500000 3
#> 80 13 Sepal.Length 1.0000000 3
#> 81 15 Petal.Length 0.2500000 3
#> 82 15 Sepal.Length 0.5000000 3
#> 83 15 Petal.Width 0.7500000 3
#> 84 15 Sepal.Length 1.0000000 3
#> 85 16 Petal.Length 0.2500000 3
#> 86 16 Sepal.Length 0.5000000 3
#> 87 16 Petal.Width 0.7500000 3
#> 88 16 Sepal.Length 1.0000000 3
#> 89 17 Petal.Width 0.2000000 3
#> 90 17 Petal.Length 0.4000000 3
#> 91 17 Sepal.Width 0.6000000 3
#> 92 17 Petal.Width 0.8000000 3
#> 93 17 Sepal.Length 1.0000000 3
#> 94 19 Petal.Length 0.1666667 3
#> 95 19 Petal.Width 0.3333333 3
#> 96 19 Petal.Length 0.5000000 3
#> 97 19 Sepal.Width 0.6666667 3
#> 98 19 Petal.Width 0.8333333 3
#> 99 19 Sepal.Length 1.0000000 3
#> 100 20 Petal.Length 0.1666667 3
#> 101 20 Petal.Width 0.3333333 3
#> 102 20 Petal.Length 0.5000000 3
#> 103 20 Sepal.Width 0.6666667 3
#> 104 20 Petal.Width 0.8333333 3
#> 105 20 Sepal.Length 1.0000000 3
#> 106 1 Petal.Width 1.0000000 4
#> 107 5 Petal.Width 0.3333333 4
#> 108 5 Petal.Length 0.6666667 4
#> 109 5 Petal.Width 1.0000000 4
#> 110 6 Petal.Width 0.3333333 4
#> 111 6 Petal.Length 0.6666667 4
#> 112 6 Petal.Width 1.0000000 4
#> 113 9 Sepal.Length 0.2500000 4
#> 114 9 Petal.Length 0.5000000 4
#> 115 9 Petal.Length 0.7500000 4
#> 116 9 Petal.Width 1.0000000 4
#> 117 10 Sepal.Length 0.2500000 4
#> 118 10 Petal.Length 0.5000000 4
#> 119 10 Petal.Length 0.7500000 4
#> 120 10 Petal.Width 1.0000000 4
#> 121 12 Petal.Width 0.2500000 4
#> 122 12 Petal.Length 0.5000000 4
#> 123 12 Petal.Length 0.7500000 4
#> 124 12 Petal.Width 1.0000000 4
#> 125 13 Sepal.Length 0.2000000 4
#> 126 13 Petal.Width 0.4000000 4
#> 127 13 Petal.Length 0.6000000 4
#> 128 13 Petal.Length 0.8000000 4
#> 129 13 Petal.Width 1.0000000 4
#> 130 14 Sepal.Length 0.2000000 4
#> 131 14 Petal.Width 0.4000000 4
#> 132 14 Petal.Length 0.6000000 4
#> 133 14 Petal.Length 0.8000000 4
#> 134 14 Petal.Width 1.0000000 4
#> 135 1 Petal.Length 1.0000000 5
#> 136 6 Sepal.Width 0.3333333 5
#> 137 6 Petal.Width 0.6666667 5
#> 138 6 Petal.Length 1.0000000 5
#> 139 8 Petal.Length 0.3333333 5
#> 140 8 Petal.Width 0.6666667 5
#> 141 8 Petal.Length 1.0000000 5
#> 142 10 Petal.Length 0.2500000 5
#> 143 10 Sepal.Width 0.5000000 5
#> 144 10 Petal.Width 0.7500000 5
#> 145 10 Petal.Length 1.0000000 5
#> 146 11 Sepal.Length 0.2500000 5
#> 147 11 Petal.Length 0.5000000 5
#> 148 11 Petal.Width 0.7500000 5
#> 149 11 Petal.Length 1.0000000 5
#> 150 12 Sepal.Length 0.2500000 5
#> 151 12 Petal.Length 0.5000000 5
#> 152 12 Petal.Width 0.7500000 5
#> 153 12 Petal.Length 1.0000000 5
#> 154 14 Sepal.Length 0.2000000 5
#> 155 14 Petal.Length 0.4000000 5
#> 156 14 Sepal.Width 0.6000000 5
#> 157 14 Petal.Width 0.8000000 5
#> 158 14 Petal.Length 1.0000000 5
#> 159 15 Petal.Length 0.1666667 5
#> 160 15 Sepal.Length 0.3333333 5
#> 161 15 Petal.Length 0.5000000 5
#> 162 15 Sepal.Width 0.6666667 5
#> 163 15 Petal.Width 0.8333333 5
#> 164 15 Petal.Length 1.0000000 5
#> 165 16 Petal.Length 0.1666667 5
#> 166 16 Sepal.Length 0.3333333 5
#> 167 16 Petal.Length 0.5000000 5
#> 168 16 Sepal.Width 0.6666667 5
#> 169 16 Petal.Width 0.8333333 5
#> 170 16 Petal.Length 1.0000000 5Ahora ya tenemos qué variables llevan a cada nodo terminal en cada árbol e incluso un peso que vale 1 si la variable es la primera en el “camino” hacia el nodo
Pero lo que nosotros queremos es para cada observación que predecimos, ver su nodo terminal en cada árbol y pegarle las variables importantes en cada nodo.
Sería algo así.
# lo hacems de momento con todo iris, en la realidad serían los datos de test o el conjunto de datos a predecir.
nodos_terminales <- predict(rg_iris, iris, type = "terminalNodes")$predictions
# cada fila corresponde a una observación y cada columna al nodo terminal en cada árbol
head(nodos_terminales, 10 )
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 1 3 3 1 1
#> [2,] 1 3 3 1 1
#> [3,] 1 3 3 1 1
#> [4,] 1 3 3 1 1
#> [5,] 1 3 3 1 1
#> [6,] 1 3 3 1 1
#> [7,] 1 3 3 1 1
#> [8,] 1 3 3 1 1
#> [9,] 1 3 3 1 1
#> [10,] 1 3 3 1 1Lo ponemos de otra forma.
# añadimos el id de la fila
nodos_terminales_df <- nodos_terminales %>%
as.data.frame() %>%
rownames_to_column(var = "id")
colnames(nodos_terminales_df)[-1] <- 1:(ncol(nodos_terminales_df)-1)
head(nodos_terminales_df)
#> id 1 2 3 4 5
#> 1 1 1 3 3 1 1
#> 2 2 1 3 3 1 1
#> 3 3 1 3 3 1 1
#> 4 4 1 3 3 1 1
#> 5 5 1 3 3 1 1
#> 6 6 1 3 3 1 1Pivotamos para facilitar luego las agregaciones por observaciones
nodos_terminales_df <- nodos_terminales_df %>%
tidyr::pivot_longer( colnames(nodos_terminales_df)[-1], names_to = "arbol", values_to = "nodo_terminal")
head(nodos_terminales_df)
#> # A tibble: 6 × 3
#> id arbol nodo_terminal
#> <chr> <chr> <dbl>
#> 1 1 1 1
#> 2 1 2 3
#> 3 1 3 3
#> 4 1 4 1
#> 5 1 5 1
#> 6 2 1 1a la importancia en todos los árboles lo llamo info_modelo
info_modelo <- importancia_individual_todos_arboles
info_modelo$arbol <- as.character(info_modelo$arbol)
head(info_modelo)
#> nodo_terminal variables peso arbol
#> 1 1 Petal.Width 1.0000000 1
#> 2 5 Petal.Length 0.3333333 1
#> 3 5 Petal.Width 0.6666667 1
#> 4 5 Petal.Width 1.0000000 1
#> 5 8 Petal.Width 0.3333333 1
#> 6 8 Petal.Width 0.6666667 1Hacemos el join con la info de cada nodo terminal para cada observación con las variables que llevan a cada nodo terminal (en cada árbol)
final <- nodos_terminales_df %>%
left_join(info_modelo, by = c("nodo_terminal", "arbol"))
# para el individuo 30
final %>%
filter(id == 30)
#> # A tibble: 7 × 5
#> id arbol nodo_terminal variables peso
#> <chr> <chr> <dbl> <chr> <dbl>
#> 1 30 1 1 Petal.Width 1
#> 2 30 2 3 Petal.Width 0.5
#> 3 30 2 3 Sepal.Length 1
#> 4 30 3 3 Petal.Length 0.5
#> 5 30 3 3 Sepal.Length 1
#> 6 30 4 1 Petal.Width 1
#> 7 30 5 1 Petal.Length 1Agregamos la info para cada individuo, de forma que contemos cuántas veces aparece cada variable, sumamos los pesos y ordenamos
res <- final %>%
group_by(id, variables) %>%
summarise(
total = n(),
ponderado = sum(peso)) %>%
group_by(id) %>%
mutate(
importancia_caso = total / sum(total),
importancia_ponderada = ponderado / sum(ponderado)
) %>%
top_n(10, importancia_ponderada) %>%
ungroup() %>%
arrange(as.numeric(id), desc(importancia_ponderada))res %>%
filter(id == 30)
#> # A tibble: 3 × 6
#> id variables total ponderado importancia_caso importancia_ponderada
#> <chr> <chr> <int> <dbl> <dbl> <dbl>
#> 1 30 Petal.Width 3 2.5 0.429 0.417
#> 2 30 Sepal.Length 2 2 0.286 0.333
#> 3 30 Petal.Length 2 1.5 0.286 0.25Y esa sería la importancia de las variables específica para la observación 30
Nos podemos crear una funcioncita que lo haga todo.
getIndividualImportance <- function(modelo, data, top = modelo$num.independent.variables, ...){
params_ellipsis <- list(...)
# get terminalNodes
nodos_terminales <- predict(modelo, data, type = "terminalNodes")$predictions
nodos_terminales_df <- nodos_terminales %>%
as.data.frame()
nodos_terminales_df$id <- rownames(data)
nodos_terminales_df <- nodos_terminales_df %>%
dplyr::select(id, everything())
colnames(nodos_terminales_df)[-1] <- 1:(ncol(nodos_terminales_df)-1)
nodos_terminales_df <- nodos_terminales_df %>%
tidyr::pivot_longer( colnames(nodos_terminales_df)[-1], names_to = "arbol", values_to = "nodo_terminal")
# get variables_path for each tree and terminal node
info_modelo <- extraerVariablesPorModelo(modelo, parallel = params_ellipsis$parallel)
info_modelo$arbol <- as.character(info_modelo$arbol)
# join both
final <- nodos_terminales_df %>%
left_join(info_modelo, by = c("nodo_terminal", "arbol"))
res <- final %>%
group_by(id, variables) %>%
summarise(
total = n(),
ponderado = sum(peso)) %>%
group_by(id) %>%
# para poder comparar luego observaciones, para cadda individuo, divido las veces qeu
# aparece una variable por el total de veces que han aparecido todas sus variables
mutate(
importancia_caso = total / sum(total),
importancia_ponderada = ponderado / sum(ponderado)
) %>%
top_n(top, importancia_ponderada) %>%
ungroup() %>%
arrange(as.numeric(id), desc(importancia_ponderada))
}Y comprobamos
explicatividad_iris <- getIndividualImportance(rg_iris, iris, parallel = TRUE)DT::datatable(explicatividad_iris)Podríamos hacer ahora un PCA pero yo voy a utilizar un CA usando la importancia_ponderada
tabla_para_diagonalizar <- xtabs(ponderado ~ id+ variables, data= explicatividad_iris)
tabla_para_diagonalizar
#> variables
#> id Petal.Length Petal.Width Sepal.Length Sepal.Width
#> 1 1.5000000 2.5000000 2.0000000 0.0000000
#> 10 1.5000000 2.5000000 2.0000000 0.0000000
#> 100 2.5000000 5.1666667 2.0000000 1.3333333
#> 101 2.5833333 5.2500000 2.6666667 0.0000000
#> 102 2.8333333 5.4166667 3.0000000 0.2500000
#> 103 2.5833333 5.2500000 2.6666667 0.0000000
#> 104 2.8333333 5.5000000 2.6666667 0.0000000
#> 105 2.5833333 5.2500000 2.6666667 0.0000000
#> 106 2.5833333 5.2500000 2.6666667 0.0000000
#> 107 3.6666667 4.3333333 2.3333333 0.6666667
#> 108 2.8333333 5.5000000 2.6666667 0.0000000
#> 109 2.8333333 5.5000000 2.6666667 0.0000000
#> 11 1.5000000 2.5000000 2.0000000 0.0000000
#> 110 2.5833333 5.2500000 2.6666667 0.0000000
#> 111 2.5833333 5.2500000 2.6666667 0.0000000
#> 112 2.5833333 5.2500000 2.6666667 0.0000000
#> 113 2.5833333 5.2500000 2.6666667 0.0000000
#> 114 2.8333333 5.1666667 3.2500000 0.2500000
#> 115 2.8333333 5.4166667 3.0000000 0.2500000
#> 116 2.5833333 5.2500000 2.6666667 0.0000000
#> 117 2.8333333 5.5000000 2.6666667 0.0000000
#> 118 2.5833333 5.2500000 2.6666667 0.0000000
#> 119 2.5833333 5.2500000 2.6666667 0.0000000
#> 12 1.5000000 2.5000000 2.0000000 0.0000000
#> 120 3.8000000 5.5500000 2.2500000 1.9000000
#> 121 2.5833333 5.2500000 2.6666667 0.0000000
#> 122 2.2500000 5.5000000 3.0000000 0.2500000
#> 123 2.5833333 5.2500000 2.6666667 0.0000000
#> 124 2.2500000 5.5833333 2.6666667 0.0000000
#> 125 2.5833333 5.2500000 2.6666667 0.0000000
#> 126 2.8333333 5.5000000 2.6666667 0.0000000
#> 127 2.4166667 5.6666667 2.9166667 0.0000000
#> 128 2.2500000 5.5833333 2.6666667 0.0000000
#> 129 2.5833333 5.2500000 2.6666667 0.0000000
#> 13 1.5000000 2.5000000 2.0000000 0.0000000
#> 130 4.0666667 6.0666667 2.2000000 2.1666667
#> 131 2.5833333 5.2500000 2.6666667 0.0000000
#> 132 2.5833333 5.2500000 2.6666667 0.0000000
#> 133 2.5833333 5.2500000 2.6666667 0.0000000
#> 134 3.8000000 5.9000000 2.2000000 2.1000000
#> 135 3.9500000 5.9500000 2.2000000 1.9000000
#> 136 2.5833333 5.2500000 2.6666667 0.0000000
#> 137 2.5833333 5.2500000 2.6666667 0.0000000
#> 138 2.8333333 5.5000000 2.6666667 0.0000000
#> 139 2.6666667 5.7500000 3.0833333 0.0000000
#> 14 1.5000000 2.5000000 2.0000000 0.0000000
#> 140 2.5833333 5.2500000 2.6666667 0.0000000
#> 141 2.5833333 5.2500000 2.6666667 0.0000000
#> 142 2.5833333 5.2500000 2.6666667 0.0000000
#> 143 2.8333333 5.4166667 3.0000000 0.2500000
#> 144 2.5833333 5.2500000 2.6666667 0.0000000
#> 145 2.5833333 5.2500000 2.6666667 0.0000000
#> 146 2.5833333 5.2500000 2.6666667 0.0000000
#> 147 2.5833333 5.0000000 2.9166667 0.0000000
#> 148 2.5833333 5.2500000 2.6666667 0.0000000
#> 149 2.5833333 5.2500000 2.6666667 0.0000000
#> 15 1.0000000 3.3333333 2.0000000 0.6666667
#> 150 3.0833333 5.6666667 3.0000000 0.2500000
#> 16 1.0000000 3.3333333 2.0000000 0.6666667
#> 17 1.5000000 2.5000000 2.0000000 0.0000000
#> 18 1.5000000 2.5000000 2.0000000 0.0000000
#> 19 1.0000000 3.3333333 2.0000000 0.6666667
#> 2 1.5000000 2.5000000 2.0000000 0.0000000
#> 20 1.5000000 2.5000000 2.0000000 0.0000000
#> 21 1.5000000 2.5000000 2.0000000 0.0000000
#> 22 1.5000000 2.5000000 2.0000000 0.0000000
#> 23 1.5000000 2.5000000 2.0000000 0.0000000
#> 24 1.5000000 2.5000000 2.0000000 0.0000000
#> 25 1.5000000 2.5000000 2.0000000 0.0000000
#> 26 1.5000000 2.5000000 2.0000000 0.0000000
#> 27 1.5000000 2.5000000 2.0000000 0.0000000
#> 28 1.5000000 2.5000000 2.0000000 0.0000000
#> 29 1.5000000 2.5000000 2.0000000 0.0000000
#> 3 1.5000000 2.5000000 2.0000000 0.0000000
#> 30 1.5000000 2.5000000 2.0000000 0.0000000
#> 31 1.5000000 2.5000000 2.0000000 0.0000000
#> 32 1.5000000 2.5000000 2.0000000 0.0000000
#> 33 1.5000000 2.5000000 2.0000000 0.0000000
#> 34 1.5000000 2.6666667 2.0000000 0.3333333
#> 35 1.5000000 2.5000000 2.0000000 0.0000000
#> 36 1.5000000 2.5000000 2.0000000 0.0000000
#> 37 1.5000000 2.6666667 2.0000000 0.3333333
#> 38 1.5000000 2.5000000 2.0000000 0.0000000
#> 39 1.5000000 2.5000000 2.0000000 0.0000000
#> 4 1.5000000 2.5000000 2.0000000 0.0000000
#> 40 1.5000000 2.5000000 2.0000000 0.0000000
#> 41 1.5000000 2.5000000 2.0000000 0.0000000
#> 42 1.5000000 2.5000000 2.0000000 0.0000000
#> 43 1.5000000 2.5000000 2.0000000 0.0000000
#> 44 1.5000000 2.5000000 2.0000000 0.0000000
#> 45 1.5000000 2.5000000 2.0000000 0.0000000
#> 46 1.5000000 2.5000000 2.0000000 0.0000000
#> 47 1.5000000 2.5000000 2.0000000 0.0000000
#> 48 1.5000000 2.5000000 2.0000000 0.0000000
#> 49 1.5000000 2.5000000 2.0000000 0.0000000
#> 5 1.5000000 2.5000000 2.0000000 0.0000000
#> 50 1.5000000 2.5000000 2.0000000 0.0000000
#> 51 2.5000000 5.1666667 2.0000000 1.3333333
#> 52 2.5000000 5.1666667 2.0000000 1.3333333
#> 53 2.5000000 5.1666667 2.0000000 1.3333333
#> 54 3.6500000 4.5500000 2.2000000 1.1000000
#> 55 2.5000000 5.1666667 2.0000000 1.3333333
#> 56 2.5000000 5.1666667 2.0000000 1.3333333
#> 57 2.5000000 5.1666667 2.0000000 1.3333333
#> 58 3.6666667 4.3333333 2.3333333 0.6666667
#> 59 2.5000000 5.1666667 2.0000000 1.3333333
#> 6 1.5000000 2.5000000 2.0000000 0.0000000
#> 60 3.0000000 4.1666667 2.0000000 0.3333333
#> 61 3.4000000 4.3000000 2.2000000 0.6000000
#> 62 2.5000000 5.1666667 2.0000000 1.3333333
#> 63 2.9000000 5.3000000 2.2000000 1.6000000
#> 64 2.5000000 5.1666667 2.0000000 1.3333333
#> 65 2.5000000 5.1666667 2.0000000 1.3333333
#> 66 2.5000000 5.1666667 2.0000000 1.3333333
#> 67 2.5000000 5.1666667 2.0000000 1.3333333
#> 68 2.5000000 5.1666667 2.0000000 1.3333333
#> 69 2.9000000 5.3000000 2.2000000 1.6000000
#> 7 1.5000000 2.5000000 2.0000000 0.0000000
#> 70 2.9000000 5.3000000 2.2000000 1.6000000
#> 71 2.6666667 5.8333333 3.2500000 0.2500000
#> 72 2.5000000 5.1666667 2.0000000 1.3333333
#> 73 2.9000000 5.3000000 2.2000000 1.6000000
#> 74 2.5000000 5.1666667 2.0000000 1.3333333
#> 75 2.5000000 5.1666667 2.0000000 1.3333333
#> 76 2.5000000 5.1666667 2.0000000 1.3333333
#> 77 2.5000000 5.1666667 2.0000000 1.3333333
#> 78 3.9166667 5.6666667 2.2500000 2.1666667
#> 79 2.5000000 5.1666667 2.0000000 1.3333333
#> 8 1.5000000 2.5000000 2.0000000 0.0000000
#> 80 2.9000000 5.3000000 2.2000000 1.6000000
#> 81 3.6500000 4.5500000 2.2000000 1.1000000
#> 82 3.6500000 4.5500000 2.2000000 1.1000000
#> 83 2.5000000 5.1666667 2.0000000 1.3333333
#> 84 4.0666667 6.0666667 2.2000000 2.1666667
#> 85 3.0000000 4.1666667 2.0000000 0.3333333
#> 86 2.5000000 5.1666667 2.0000000 1.3333333
#> 87 2.5000000 5.1666667 2.0000000 1.3333333
#> 88 2.9000000 5.3000000 2.2000000 1.6000000
#> 89 2.5000000 5.1666667 2.0000000 1.3333333
#> 9 1.5000000 2.5000000 2.0000000 0.0000000
#> 90 3.6500000 4.5500000 2.2000000 1.1000000
#> 91 3.6500000 4.5500000 2.2000000 1.1000000
#> 92 2.5000000 5.1666667 2.0000000 1.3333333
#> 93 2.9000000 5.3000000 2.2000000 1.6000000
#> 94 3.4000000 4.3000000 2.2000000 0.6000000
#> 95 2.5000000 5.1666667 2.0000000 1.3333333
#> 96 2.5000000 5.1666667 2.0000000 1.3333333
#> 97 2.5000000 5.1666667 2.0000000 1.3333333
#> 98 2.5000000 5.1666667 2.0000000 1.3333333
#> 99 3.4000000 4.3000000 2.2000000 0.6000000Y al hacer un CA podemos ver qué individuos están asociados con las variables pero por la importancia ponderada.
res_ca <- FactoMineR::CA(tabla_para_diagonalizar, graph = FALSE)
fviz_ca(res_ca)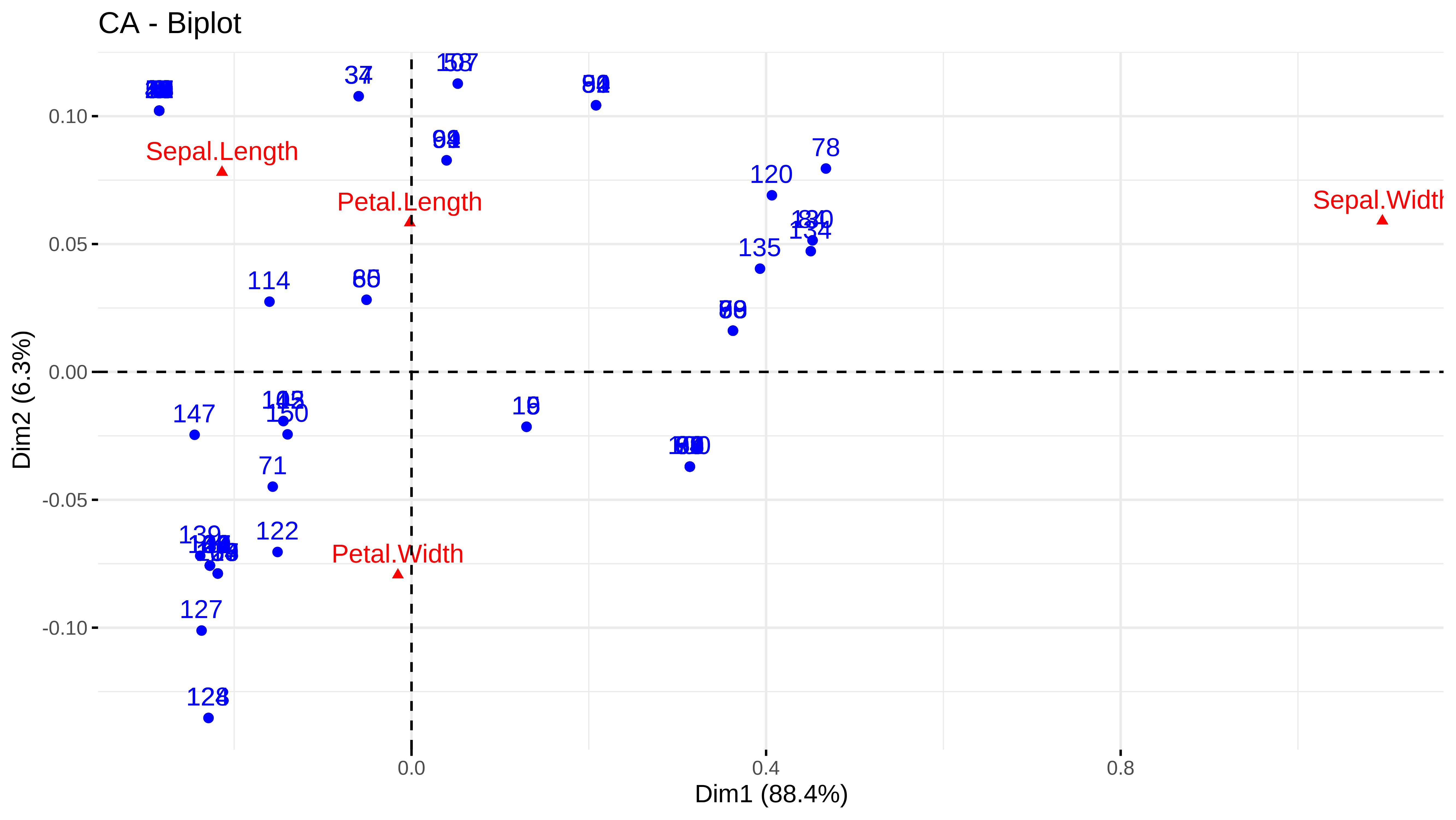
Utilicemos esto para los datos de Boston Housing
boston_df <- MASS::BostonHousing Values in Suburbs of Boston Description The Boston data frame has 506 rows and 14 columns.
Usage Boston Format This data frame contains the following columns:
crim per capita crime rate by town.
zn proportion of residential land zoned for lots over 25,000 sq.ft.
indus proportion of non-retail business acres per town.
chas Charles River dummy variable (= 1 if tract bounds river; 0 otherwise).
nox nitrogen oxides concentration (parts per 10 million).
rm average number of rooms per dwelling.
age proportion of owner-occupied units built prior to 1940.
dis weighted mean of distances to five Boston employment centres.
rad index of accessibility to radial highways.
tax full-value property-tax rate per $10,000.
ptratio pupil-teacher ratio by town.
black 1000(Bk−0.63)^2 where BkBk is the proportion of blacks by town.
lstat lower status of the population (percent).
medv median value of owner-occupied homes in $1000s.
set.seed(47)
idx <- sample(1:nrow(boston_df),300)
train_df <- boston_df[idx,]
test_df <- boston_df[-idx, ]rg_boston <- ranger(medv ~ ., data = train_df, num.trees = 50)Variables importantes a nivel individual
Por simplificar, voy a seleccionar solo las 5 variables más importantes para cada observación
importancia_individual <- getIndividualImportance(rg_boston, test_df,top = 5, parallel = TRUE)dim(importancia_individual)
#> [1] 1030 6DT::datatable(importancia_individual)tabla_diag_boston <- xtabs(ponderado ~ id+ variables, data= importancia_individual)
head(tabla_diag_boston)
#> variables
#> id age crim dis indus lstat nox ptratio rm
#> 100 18.34266 0.00000 0.00000 21.95556 37.81429 17.20397 0.00000 38.40952
#> 108 0.00000 0.00000 28.51039 27.88223 50.73328 34.23095 0.00000 41.07002
#> 110 27.78868 0.00000 29.29312 0.00000 51.24393 33.02176 0.00000 42.08247
#> 111 0.00000 0.00000 27.27855 33.53332 49.47596 26.90144 0.00000 43.21389
#> 112 0.00000 0.00000 24.53920 25.53335 54.25059 30.61195 0.00000 39.80125
#> 119 0.00000 0.00000 26.33785 28.28968 53.85364 35.92384 0.00000 39.11696
#> variables
#> id tax
#> 100 0.00000
#> 108 0.00000
#> 110 0.00000
#> 111 0.00000
#> 112 0.00000
#> 119 0.00000res_ca <- FactoMineR::CA(tabla_diag_boston, graph = FALSE)
fviz_ca(res_ca)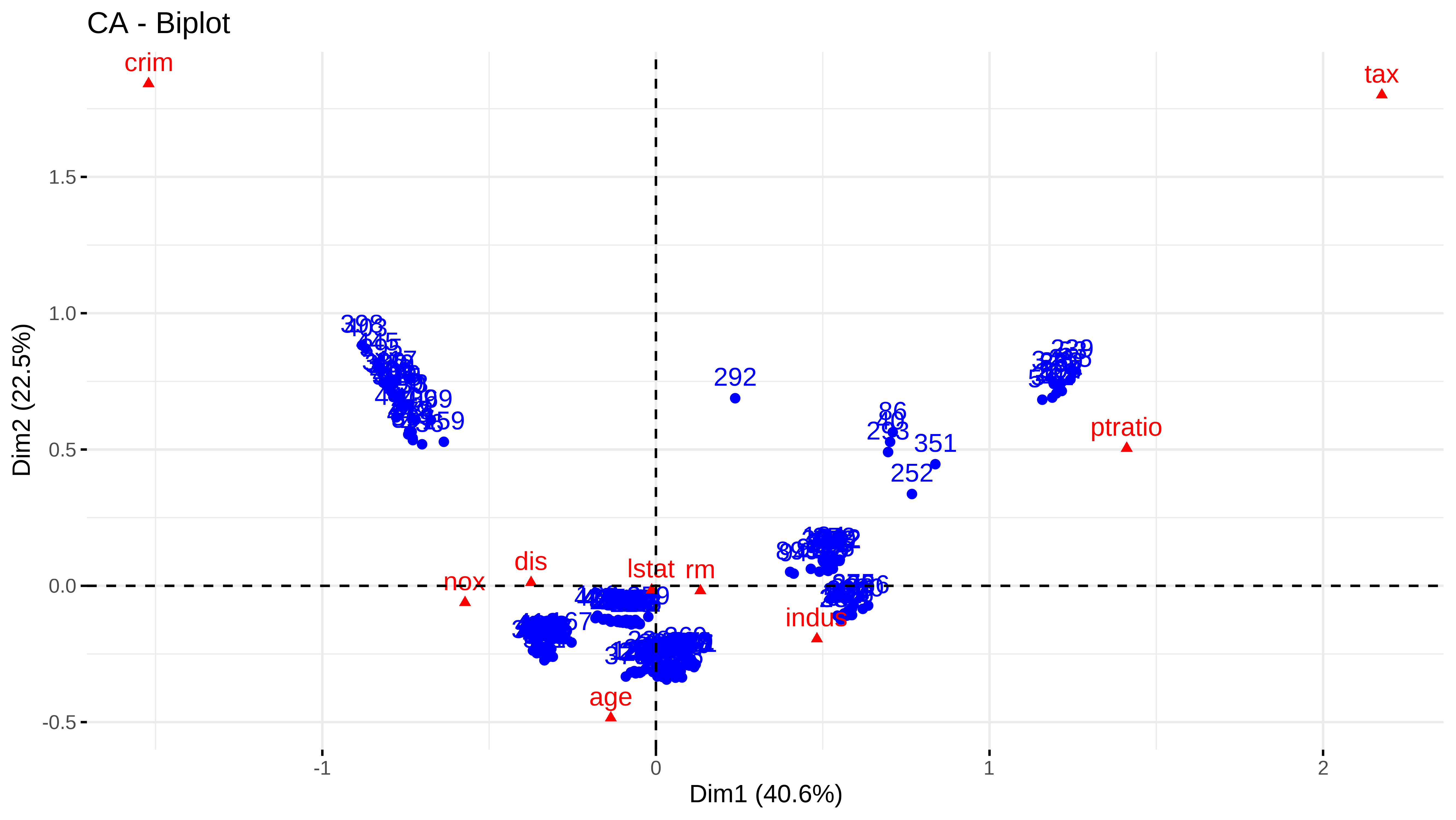
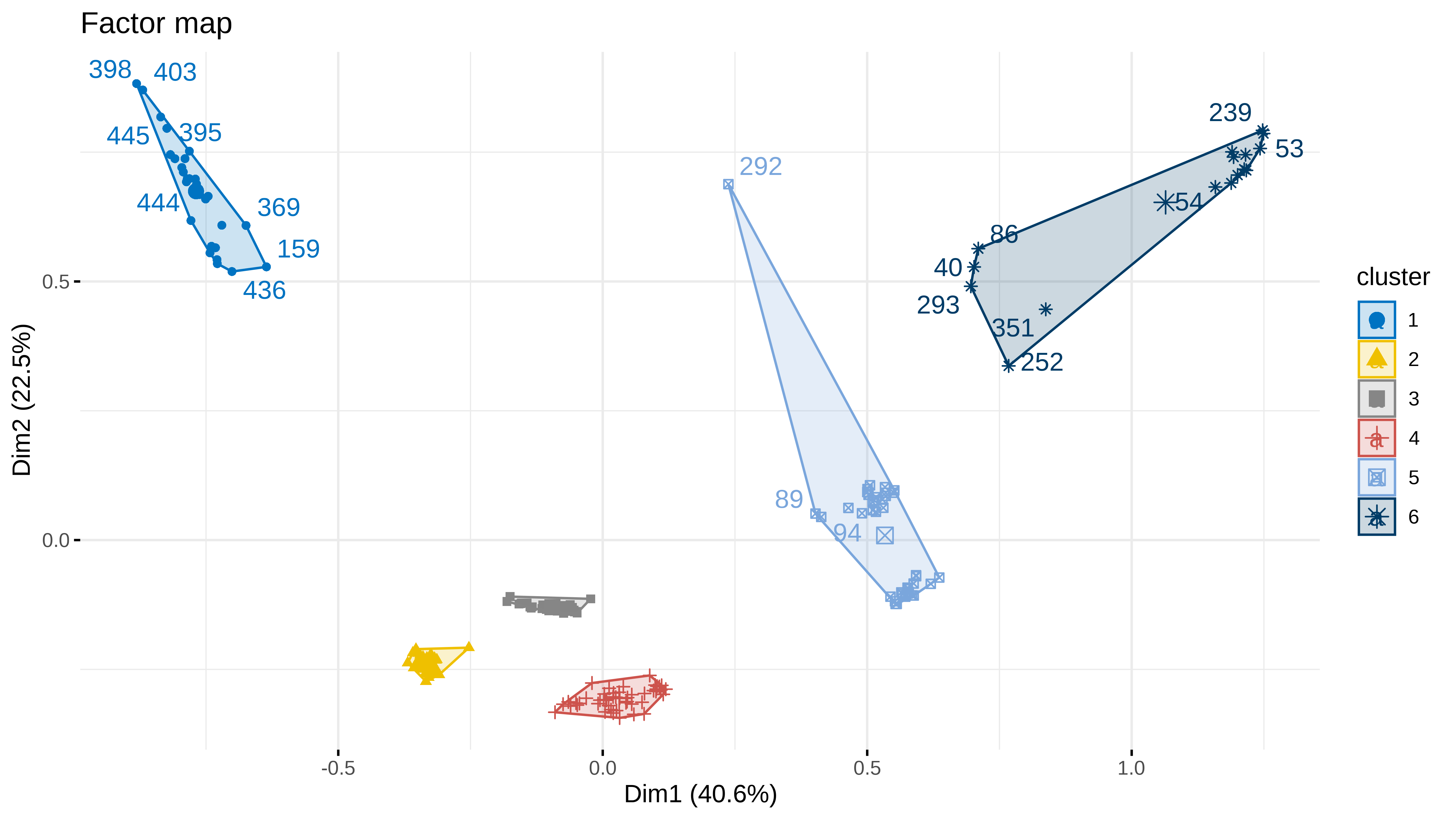
Podemos hacer un HCPC usando las dimensiones obtenidas. Lo que hace es un cluster jerárquico usando las dimensiones obtenidas en la estructura factorial.
res_hcpc <- HCPC(res_ca, graph = FALSE)
fviz_cluster(res_hcpc,
repel = TRUE, # Avoid label overlapping
show.clust.cent = TRUE, # Show cluster centers
palette = "jco", # Color palette see ?ggpubr::ggpar
ggtheme = theme_minimal(),
main = "Factor map"
)
plot(res_hcpc, choice = "3D.map")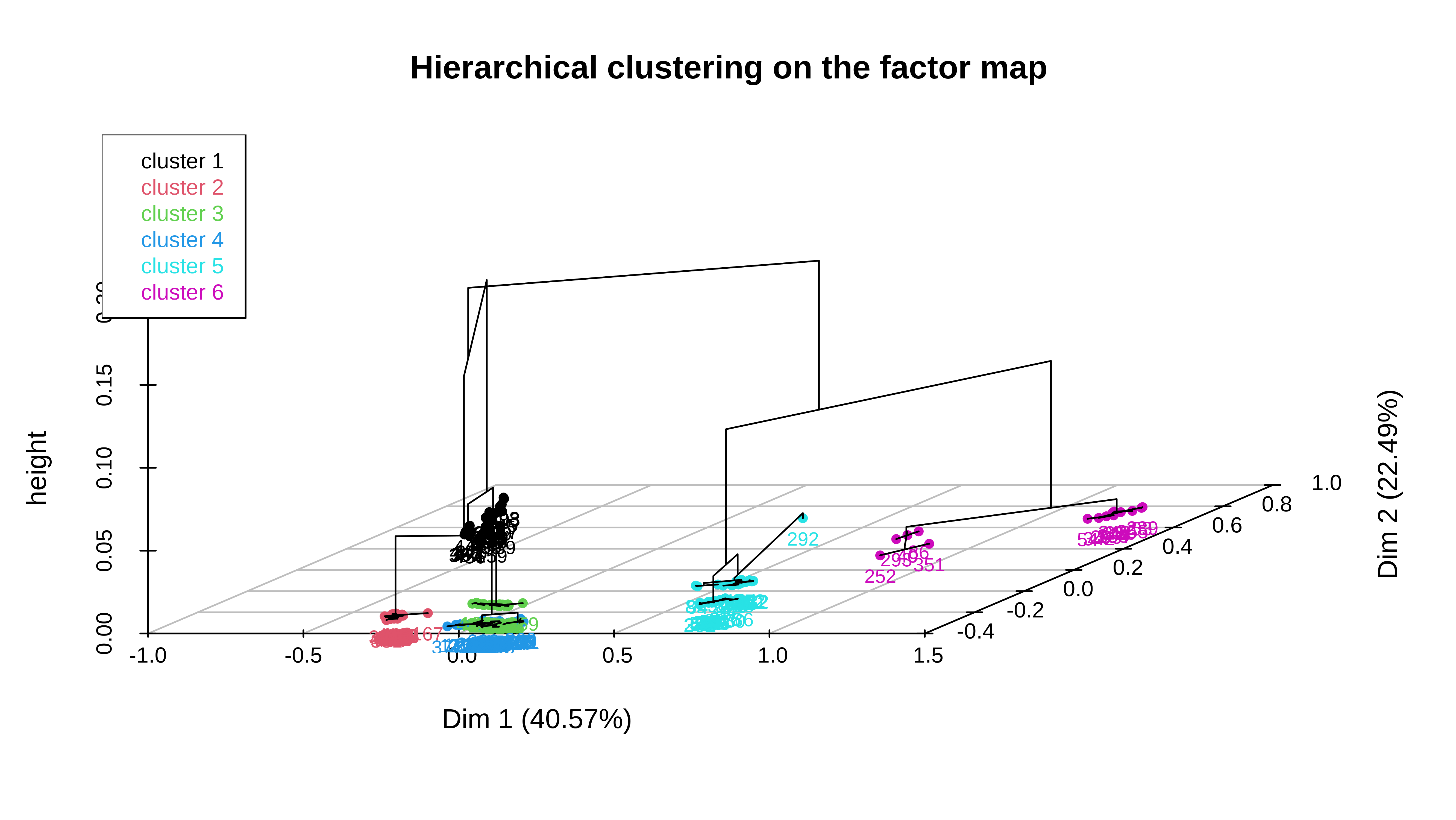
Una utilidad interesante es la descripción de las variables de los clusters. Dónde nos dice cuales son la variables más importantes para cada uno.
Cuando en un cluster su Intern % para una variable se desvíe mucho de glob % quiere decir que en esa variable la distribución es distinta de en la población general y por tanto es una variables que caracteriza al cluster.
En este caso estaremos encontrando grupos de individuos con mismas variables importantes en el randomForest.
Claramente se ven grupos dónde es muy importante la variable de criminalidad o la edad
res_hcpc$desc.var
#> $`1`
#> Intern % glob % Intern freq Glob freq p.value v.test
#> crim 15.592962 2.127929 642.8840 657.2566 0.000000e+00 Inf
#> nox 20.157813 12.416539 831.0888 3835.1142 2.807733e-52 15.215104
#> dis 11.939900 9.329212 492.2715 2881.5271 2.572108e-09 5.956809
#> rm 20.191263 25.487484 832.4679 7872.3559 1.117021e-17 -8.561196
#> age 4.411035 7.568723 181.8631 2337.7625 1.230524e-18 -8.811891
#> tax 0.000000 1.001897 0.0000 309.4575 9.327733e-20 -9.096514
#> ptratio 0.000000 3.118072 0.0000 963.0835 2.250504e-61 -16.529487
#> indus 0.000000 10.860935 0.0000 3354.6328 2.069270e-222 -31.835808
#>
#> $`2`
#> Intern % glob % Intern freq Glob freq p.value v.test
#> age 14.32559 7.568723 803.0250 2337.7625 7.150050e-85 19.521920
#> nox 19.56112 12.416539 1096.5037 3835.1142 9.886451e-65 16.989118
#> dis 15.61069 9.329212 875.0616 2881.5271 3.449026e-63 16.779470
#> rm 21.85203 25.487484 1224.9213 7872.3559 2.382720e-12 -7.010027
#> tax 0.00000 1.001897 0.0000 309.4575 1.880511e-27 -10.855366
#> crim 0.00000 2.127929 0.0000 657.2566 2.961603e-58 -16.090764
#> ptratio 0.00000 3.118072 0.0000 963.0835 1.146579e-85 -19.615212
#> indus 0.00000 10.860935 0.0000 3354.6328 2.480702e-311 -37.718398
#>
#> $`3`
#> Intern % glob % Intern freq Glob freq p.value v.test
#> dis 14.41601 9.329212 885.4575 2881.5271 7.965757e-48 14.528753
#> indus 15.72645 10.860935 965.9468 3354.6328 4.377749e-39 13.078362
#> nox 17.05504 12.416539 1047.5513 3835.1142 1.891207e-32 11.860817
#> rm 24.28797 25.487484 1491.8110 7872.3559 1.531797e-02 -2.424773
#> tax 0.00000 1.001897 0.0000 309.4575 2.402280e-30 -11.448146
#> crim 0.00000 2.127929 0.0000 657.2566 1.885153e-64 -16.951216
#> ptratio 0.00000 3.118072 0.0000 963.0835 8.318594e-95 -20.657729
#> age 0.00000 7.568723 0.0000 2337.7625 1.165375e-235 -32.779199
#>
#> $`4`
#> Intern % glob % Intern freq Glob freq p.value v.test
#> age 13.713854 7.568723 994.4487 2337.7625 7.010364e-100 21.214544
#> indus 15.980898 10.860935 1158.8415 3354.6328 3.363370e-53 15.353354
#> rm 27.297454 25.487484 1979.4522 7872.3559 6.332137e-05 4.000079
#> nox 11.031380 12.416539 799.9313 3835.1142 3.337066e-05 -4.149154
#> tax 0.000000 1.001897 0.0000 309.4575 1.541120e-36 -12.624810
#> crim 0.000000 2.127929 0.0000 657.2566 1.026729e-77 -18.661061
#> dis 3.479402 9.329212 252.3059 2881.5271 1.613296e-102 -21.498348
#> ptratio 0.000000 3.118072 0.0000 963.0835 2.246449e-114 -22.730329
#>
#> $`5`
#> Intern % glob % Intern freq Glob freq p.value v.test
#> ptratio 13.4631336 3.118072 731.46909 963.0835 0.000000e+00 Inf
#> indus 16.0021844 10.860935 869.41894 3354.6328 2.134777e-37 12.779485
#> rm 30.0450942 25.487484 1632.38800 7872.3559 6.922077e-17 8.348354
#> age 5.9723379 7.568723 324.48468 2337.7625 4.791243e-07 -5.034489
#> dis 5.8922388 9.329212 320.13279 2881.5271 6.783780e-24 -10.079838
#> tax 0.0000000 1.001897 0.00000 309.4575 1.567007e-26 -10.659939
#> crim 0.2645368 2.127929 14.37262 657.2566 4.931237e-37 -12.714201
#> nox 1.1050567 12.416539 60.03913 3835.1142 3.406088e-250 -33.783844
#>
#> $`6`
#> Intern % glob % Intern freq Glob freq p.value v.test
#> tax 13.270152 1.001897 309.45748 309.4575 0.000000e+00 Inf
#> ptratio 9.932087 3.118072 231.61443 963.0835 3.328525e-58 16.083531
#> indus 15.455762 10.860935 360.42551 3354.6328 2.442145e-12 7.006580
#> rm 30.502626 25.487484 711.31557 7872.3559 1.684450e-08 5.641633
#> crim 0.000000 2.127929 0.00000 657.2566 4.470886e-23 -9.892856
#> dis 2.414161 9.329212 56.29780 2881.5271 1.144880e-43 -13.857568
#> age 1.455459 7.568723 33.94103 2337.7625 5.050710e-44 -13.916197
#> nox 0.000000 12.416539 0.00000 3835.1142 2.015379e-140 -25.227201
#>
#> attr(,"class")
#> [1] "descfreq" "list"Y por supuesto tenemos los datos con el cluster asignado y los valores de cada variable (no son los valores originales de las variables , sino la importancia ponderada que tenían con el procedimiento descrito para cada observación )
res_hcpc$data.clust %>%
dplyr::select(clust, everything()) %>%
slice_sample(prop = 0.3) %>%
DT::datatable()Si unimos con el dataset original
test_df_with_cluster <- res_hcpc$data.clust %>%
rownames_to_column(var = "id") %>%
dplyr::select(id, clust)
unido <- test_df %>%
rownames_to_column(var = "id") %>%
inner_join(test_df_with_cluster, by = "id")Y efectivamente vemos que el cluster 1 tiene mucho más ratio de criminalidad, y además es la variable más importante para ese grupo en relación con la variable dependiente medv. No causa sorpresa ver que es justo en ese cluster dónde el precio de la propiedad es más bajo
unido %>%
group_by(clust) %>%
summarise(across(c(lstat,crim, age, black, medv), list(mean = mean, median = median), .names = "{.col}_{.fn}" )) %>%
DT::datatable()Carlos en el post que inspira este, comenta que este tipo de procedimientos sería útil para aquellas de las observaciones con un mayor score predicho. En este ejemplo se podría aplicar para clusterizar las observaciones con un mayor valor predicho del valor de la propiedad.
Hice el código deprisa y corriendo, es claramente mejorable y podría ir mucho más rápido. El objetivo era mostrar como se puede obtener variables importantes a nivel de observación en este tipo de modelos, simplemente recorriendo por qué camino ha ido cada observación en cada árbol
Estaría chulo representar espacialmente la distribución de los clusters obtenidos