Show the code
library(tidyverse)
library(DT)
df <- read_csv(here::here("2026/05/encuestas_andalucia_2026.csv")) |>
select(empresa, fecha, n, everything())
datatable(df)Este post se ha generado solito usando Claude code. Simplemente le dije que mirara como lo hice en las elecciones de 2023 (generales) y 2024(europeas) , que leyera mis posts, y que buscara datos en la web de las encuestas. Me ha creado el csv (que ni he revisado) y que hiciera la estimación siguiendo mi metodología.
Tiempo total que me ha llevado hacer el post, menos de 1 hora.
Actualización 12 mayo 2026: Se han añadido 10 encuestas nuevas publicadas entre el 6 y el 11 de mayo (Data10, SocioMétrica, Target Point, Sigma Dos, EM-Analytics, Celeste-Tel, IMOP, NC Report, GAD3 y 40dB/Prisa). El modelo se ha re-entrenado con las 23 encuestas disponibles a 5 días de las elecciones.
Ya lo hice para las elecciones generales de julio de 2023 y para las europeas de junio de 2024. Toca repetir el ejercicio para las elecciones al Parlamento de Andalucía del 17 de mayo de 2026.
La metodología es la misma: modelo multinomial bayesiano con brms donde cada encuesta aporta un vector de votos estimados, la empresa encuestadora entra como efecto aleatorio y la variable temporal (time, días hasta las elecciones) recoge la tendencia.
Los datos los he sacado de la tabla de encuestas de Wikipedia (en). Solo he incluido encuestas con tamaño muestral publicado. La columna resto es el complemento a 100 de los cinco partidos principales: PP, PSOE-A, Vox, Por Andalucía y Adelante Andalucía.
Esto es solo por diversión. No soy experto en predicción electoral. Para algo serio habría que incluir más encuestas, datos provinciales y traducir los porcentajes a escaños con la ley D’Hondt por circunscripción.
library(tidyverse)
library(DT)
df <- read_csv(here::here("2026/05/encuestas_andalucia_2026.csv")) |>
select(empresa, fecha, n, everything())
datatable(df)Calculamos time (días hasta las elecciones) y votos (estimación * n / 100) para cada partido.
fecha_elecciones <- lubridate::ymd("2026-05-17")
df_long <- df |>
pivot_longer(c(pp, psoe, vox, por_andalucia, adelante, resto),
names_to = "partido",
values_to = "estim") |>
mutate(
votos = round(n * estim / 100),
time = as.numeric(fecha - fecha_elecciones)
)
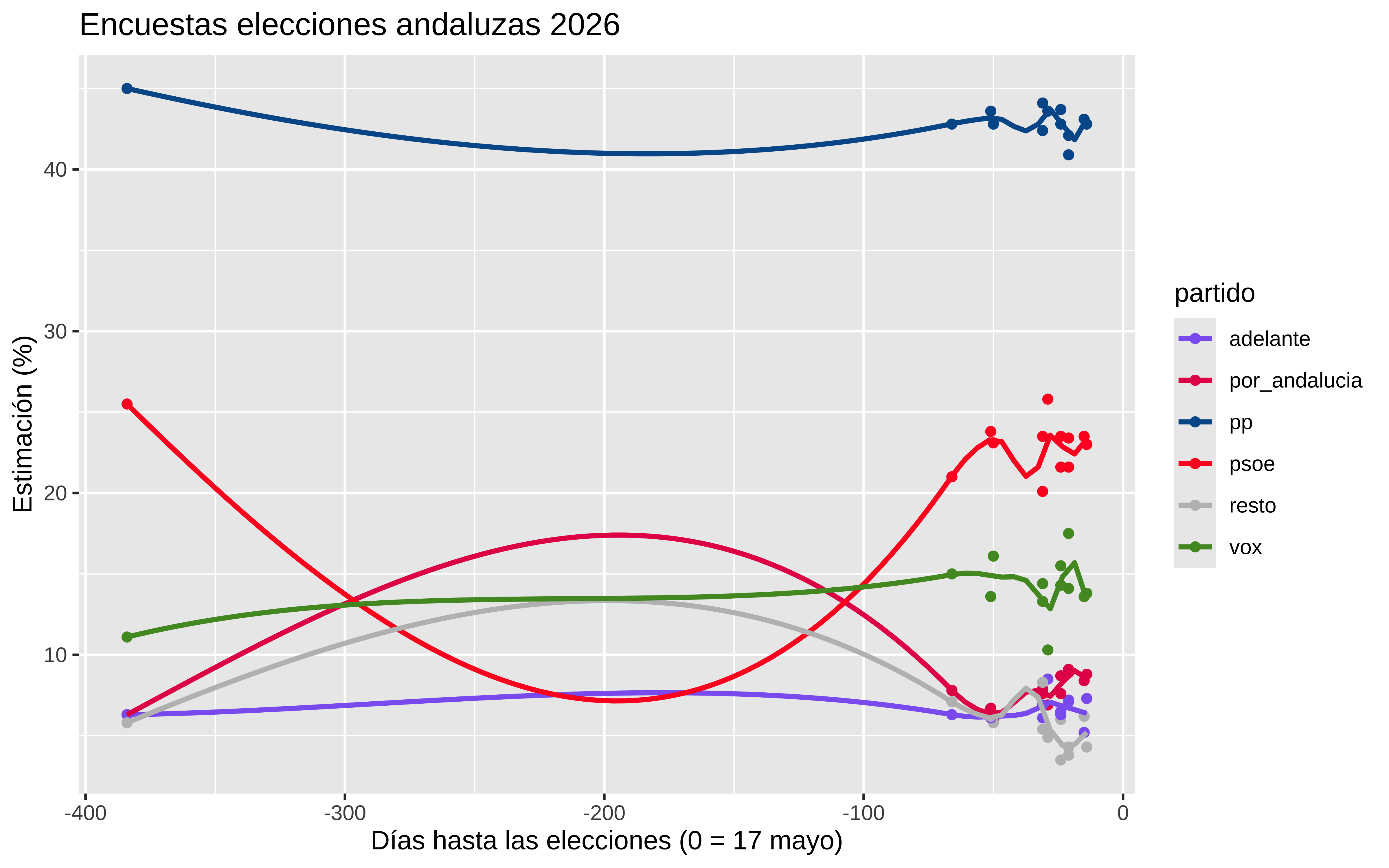
datatable(df_long)Pintamos la evolución temporal de la estimación por partido:
colores <- c(
"pp" = "#005999",
"psoe" = "#FF0126",
"vox" = "#51962A",
"por_andalucia" = "#E51C55",
"adelante" = "#8C66F1",
"resto" = "grey"
)
df_long |>
ggplot(aes(x = time, y = estim, color = partido)) +
geom_point() +
scale_color_manual(values = colores) +
geom_smooth(se = FALSE) +
labs(
title = "Encuestas elecciones andaluzas 2026",
x = "Días hasta las elecciones (0 = 17 mayo)",
y = "Estimación (%)"
)
df_wider <- df_long |>
select(-estim) |>
pivot_wider(
id_cols = c(empresa, n, time),
names_from = partido,
values_from = votos
) |>
mutate(
n = pp + psoe + vox + por_andalucia + adelante + resto
)
df_wider$cell_counts <- with(
df_wider,
cbind(pp, psoe, vox, por_andalucia, adelante, resto)
)
datatable(df_wider |> select(empresa, time, n, cell_counts))Nota sobre n: el n original de cada encuesta se sustituye por la suma de los conteos imputados (votos = round(n × estim / 100)). El redondeo introduce una discrepancia de ±1-2 votos respecto al tamaño muestral real, lo que puede alterar ligeramente el denominador en trials(n). Para las encuestas con n grande (> 1 000) el efecto es despreciable; en las más pequeñas puede suponer una diferencia de hasta un 0.2 % en las estimaciones. En un análisis de producción convendría conservar el n original y reescalar los conteos.
library(cmdstanr)
library(brms)
library(tidybayes)
options(brms.backend = "cmdstanr")formula <- brmsformula(
cell_counts | trials(n) ~ time + (time | empresa)
)
(priors <- get_prior(formula, df_wider, family = multinomial()))
#> prior class coef group resp dpar nlpar lb
#> lkj(1) cor
#> lkj(1) cor empresa
#> (flat) b muadelante
#> (flat) b time muadelante
#> student_t(3, 0, 2.5) Intercept muadelante
#> student_t(3, 0, 2.5) sd muadelante 0
#> student_t(3, 0, 2.5) sd empresa muadelante 0
#> student_t(3, 0, 2.5) sd Intercept empresa muadelante 0
#> student_t(3, 0, 2.5) sd time empresa muadelante 0
#> (flat) b muporandalucia
#> (flat) b time muporandalucia
#> student_t(3, 0, 2.5) Intercept muporandalucia
#> student_t(3, 0, 2.5) sd muporandalucia 0
#> student_t(3, 0, 2.5) sd empresa muporandalucia 0
#> student_t(3, 0, 2.5) sd Intercept empresa muporandalucia 0
#> student_t(3, 0, 2.5) sd time empresa muporandalucia 0
#> (flat) b mupsoe
#> (flat) b time mupsoe
#> student_t(3, 0, 2.5) Intercept mupsoe
#> student_t(3, 0, 2.5) sd mupsoe 0
#> student_t(3, 0, 2.5) sd empresa mupsoe 0
#> student_t(3, 0, 2.5) sd Intercept empresa mupsoe 0
#> student_t(3, 0, 2.5) sd time empresa mupsoe 0
#> (flat) b muresto
#> (flat) b time muresto
#> student_t(3, 0, 2.5) Intercept muresto
#> student_t(3, 0, 2.5) sd muresto 0
#> student_t(3, 0, 2.5) sd empresa muresto 0
#> student_t(3, 0, 2.5) sd Intercept empresa muresto 0
#> student_t(3, 0, 2.5) sd time empresa muresto 0
#> (flat) b muvox
#> (flat) b time muvox
#> student_t(3, 0, 2.5) Intercept muvox
#> student_t(3, 0, 2.5) sd muvox 0
#> student_t(3, 0, 2.5) sd empresa muvox 0
#> student_t(3, 0, 2.5) sd Intercept empresa muvox 0
#> student_t(3, 0, 2.5) sd time empresa muvox 0
#> ub tag source
#> default
#> (vectorized)
#> default
#> (vectorized)
#> default
#> default
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> default
#> (vectorized)
#> default
#> default
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> default
#> (vectorized)
#> default
#> default
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> default
#> (vectorized)
#> default
#> default
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> default
#> (vectorized)
#> default
#> default
#> (vectorized)
#> (vectorized)
#> (vectorized)Antes de ajustar con datos, comprobamos que los priors generan proporciones de voto plausibles. Los priors por defecto de brms para efectos fijos en modelos multinomiales son impropers (flat), lo que impide muestrear solo del prior. Para el check usamos priors propios pero débilmente informativos en la escala log-odds: Normal(0, 2) para interceptos y pendientes, Exponential(1) para las desviaciones de los efectos aleatorios.
# Los priors por defecto para b e Intercept en multinomial son flat (improper),
# lo que impide muestrear solo del prior. Sustituimos los flat por propios:
# b / Intercept → Normal(0, 2) en escala log-odds (muy permisivo: cubre 0-100% de voto)
# sd → Exponential(1) (restricción a positivos, cola moderada)
priors_ppc <- priors |>
dplyr::mutate(prior = dplyr::case_when(
prior != "" ~ prior,
class == "b" ~ "normal(0, 2)",
class == "Intercept" ~ "normal(0, 2)",
class == "sd" ~ "exponential(1)",
class == "cor" ~ "lkj(1)",
TRUE ~ prior
))
model_prior <- brm(
formula,
df_wider,
multinomial(),
prior = priors_ppc,
sample_prior = "only",
iter = 2000,
warmup = 500,
cores = 4,
chains = 2,
seed = 47,
file = here::here("2026/05/mod_meta_andalucia_prior"),
backend = "cmdstanr",
refresh = 0
)
#> Running MCMC with 2 chains, at most 4 in parallel...
#>
#> Chain 1 finished in 0.4 seconds.
#> Chain 2 finished in 0.3 seconds.
#>
#> Both chains finished successfully.
#> Mean chain execution time: 0.4 seconds.
#> Total execution time: 0.5 seconds.pred_prior <- df_wider |>
add_epred_draws(model_prior, ndraws = 100) |>
rename(partido = .category, pred = .epred) |>
ungroup() |>
mutate(pred = pred / n) |>
select(empresa, time, partido, pred, .draw)
obs_props_ppc <- df_wider |>
mutate(across(c(pp, psoe, vox, por_andalucia, adelante, resto),
\(x) x / n)) |>
select(empresa, time, pp, psoe, vox, por_andalucia, adelante, resto) |>
pivot_longer(pp:resto, names_to = "partido", values_to = "obs")
pred_prior |>
left_join(obs_props_ppc, by = c("empresa", "time", "partido")) |>
ggplot(aes(x = time, color = partido)) +
stat_lineribbon(aes(y = pred), .width = c(0.50, 0.90), alpha = 0.25) +
geom_point(aes(y = obs), size = 1.5) +
facet_wrap(~partido, scales = "free_y") +
scale_color_manual(values = colores, guide = "none") +
scale_fill_grey(start = 0.6, end = 0.85) +
labs(
title = "Prior predictive check — multinomial",
subtitle = "Bandas: IC 50 % y 90 % prior · Puntos: proporción observada",
x = "Días hasta las elecciones", y = "Proporción"
) +
theme_minimal()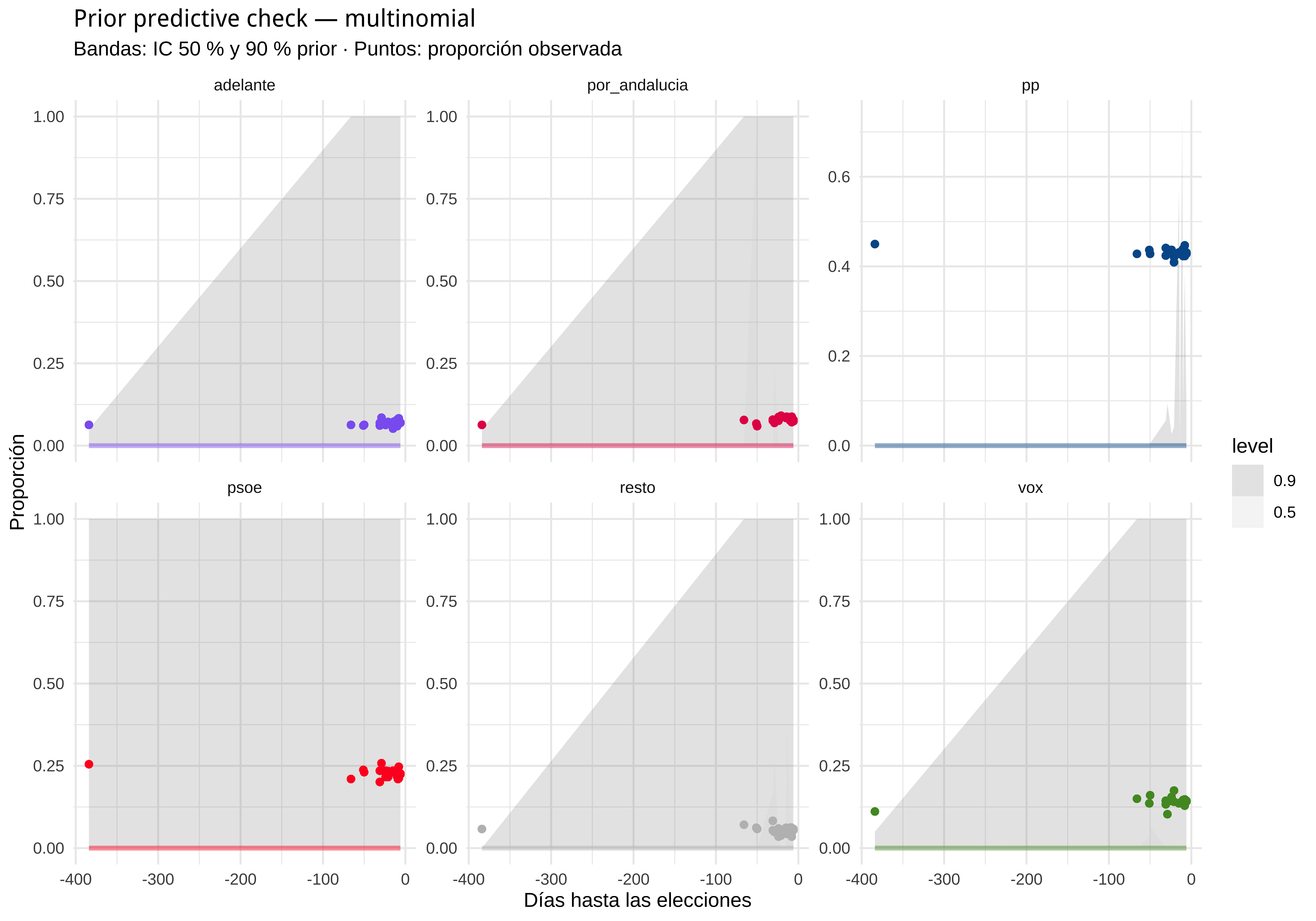
model_andalucia <- brm(
formula,
df_wider,
multinomial(),
prior = priors,
iter = 4000,
warmup = 1000,
cores = 4,
chains = 4,
seed = 47,
file = here::here("2026/05/mod_meta_andalucia"),
backend = "cmdstanr",
control = list(adapt_delta = 0.95),
refresh = 0
)
summary(model_andalucia)
#> Family: multinomial
#> Links: mupsoe = logit; muvox = logit; muporandalucia = logit; muadelante = logit; muresto = logit
#> Formula: cell_counts | trials(n) ~ time + (time | empresa)
#> Data: df_wider (Number of observations: 23)
#> Draws: 4 chains, each with iter = 4000; warmup = 1000; thin = 1;
#> total post-warmup draws = 12000
#>
#> Multilevel Hyperparameters:
#> ~empresa (Number of levels: 13)
#> Estimate Est.Error l-95% CI
#> sd(mupsoe_Intercept) 0.05 0.03 0.00
#> sd(mupsoe_time) 0.00 0.00 0.00
#> sd(muvox_Intercept) 0.05 0.05 0.00
#> sd(muvox_time) 0.01 0.00 0.00
#> sd(muporandalucia_Intercept) 0.06 0.04 0.00
#> sd(muporandalucia_time) 0.00 0.00 0.00
#> sd(muadelante_Intercept) 0.07 0.05 0.00
#> sd(muadelante_time) 0.00 0.00 0.00
#> sd(muresto_Intercept) 0.28 0.08 0.17
#> sd(muresto_time) 0.00 0.00 0.00
#> cor(mupsoe_Intercept,mupsoe_time) -0.00 0.56 -0.95
#> cor(muvox_Intercept,muvox_time) 0.10 0.60 -0.94
#> cor(muporandalucia_Intercept,muporandalucia_time) 0.03 0.58 -0.95
#> cor(muadelante_Intercept,muadelante_time) -0.00 0.57 -0.95
#> cor(muresto_Intercept,muresto_time) 0.46 0.41 -0.56
#> u-95% CI Rhat Bulk_ESS
#> sd(mupsoe_Intercept) 0.11 1.00 3061
#> sd(mupsoe_time) 0.00 1.00 2548
#> sd(muvox_Intercept) 0.17 1.00 3721
#> sd(muvox_time) 0.01 1.00 1688
#> sd(muporandalucia_Intercept) 0.15 1.00 4443
#> sd(muporandalucia_time) 0.01 1.00 2284
#> sd(muadelante_Intercept) 0.18 1.00 3858
#> sd(muadelante_time) 0.01 1.00 2132
#> sd(muresto_Intercept) 0.46 1.00 3787
#> sd(muresto_time) 0.01 1.00 3689
#> cor(mupsoe_Intercept,mupsoe_time) 0.93 1.00 6261
#> cor(muvox_Intercept,muvox_time) 0.97 1.00 1288
#> cor(muporandalucia_Intercept,muporandalucia_time) 0.95 1.00 2733
#> cor(muadelante_Intercept,muadelante_time) 0.93 1.00 3609
#> cor(muresto_Intercept,muresto_time) 0.98 1.00 8444
#> Tail_ESS
#> sd(mupsoe_Intercept) 3222
#> sd(mupsoe_time) 5170
#> sd(muvox_Intercept) 4913
#> sd(muvox_time) 2182
#> sd(muporandalucia_Intercept) 5474
#> sd(muporandalucia_time) 4276
#> sd(muadelante_Intercept) 4121
#> sd(muadelante_time) 4593
#> sd(muresto_Intercept) 6222
#> sd(muresto_time) 4507
#> cor(mupsoe_Intercept,mupsoe_time) 7131
#> cor(muvox_Intercept,muvox_time) 4166
#> cor(muporandalucia_Intercept,muporandalucia_time) 4932
#> cor(muadelante_Intercept,muadelante_time) 5266
#> cor(muresto_Intercept,muresto_time) 6992
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS
#> mupsoe_Intercept -0.65 0.03 -0.70 -0.60 1.00 9289
#> muvox_Intercept -1.12 0.04 -1.19 -1.05 1.00 9378
#> muporandalucia_Intercept -1.66 0.04 -1.74 -1.58 1.00 8152
#> muadelante_Intercept -1.79 0.04 -1.87 -1.71 1.00 8962
#> muresto_Intercept -2.07 0.09 -2.24 -1.88 1.00 3516
#> mupsoe_time -0.00 0.00 -0.00 0.00 1.00 6588
#> muvox_time -0.00 0.00 -0.01 0.00 1.00 4975
#> muporandalucia_time 0.00 0.00 -0.00 0.01 1.00 4902
#> muadelante_time 0.00 0.00 -0.00 0.01 1.00 5656
#> muresto_time 0.00 0.00 -0.00 0.00 1.00 6966
#> Tail_ESS
#> mupsoe_Intercept 10533
#> muvox_Intercept 8622
#> muporandalucia_Intercept 9186
#> muadelante_Intercept 9129
#> muresto_Intercept 4799
#> mupsoe_time 5868
#> muvox_time 5491
#> muporandalucia_time 4329
#> muadelante_time 5875
#> muresto_time 5492
#>
#> Draws were sampled using sample(hmc). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).brms asigna priors por defecto basados en la escala de los datos. Los mostramos para que quede constancia de qué asumió el modelo:
prior_summary(model_andalucia)
#> prior class coef group resp dpar nlpar lb
#> (flat) b muadelante
#> (flat) b time muadelante
#> (flat) b muporandalucia
#> (flat) b time muporandalucia
#> (flat) b mupsoe
#> (flat) b time mupsoe
#> (flat) b muresto
#> (flat) b time muresto
#> (flat) b muvox
#> (flat) b time muvox
#> student_t(3, 0, 2.5) Intercept muadelante
#> student_t(3, 0, 2.5) Intercept muporandalucia
#> student_t(3, 0, 2.5) Intercept mupsoe
#> student_t(3, 0, 2.5) Intercept muresto
#> student_t(3, 0, 2.5) Intercept muvox
#> lkj_corr_cholesky(1) L
#> lkj_corr_cholesky(1) L empresa
#> student_t(3, 0, 2.5) sd muadelante 0
#> student_t(3, 0, 2.5) sd muporandalucia 0
#> student_t(3, 0, 2.5) sd mupsoe 0
#> student_t(3, 0, 2.5) sd muresto 0
#> student_t(3, 0, 2.5) sd muvox 0
#> student_t(3, 0, 2.5) sd empresa muadelante 0
#> student_t(3, 0, 2.5) sd Intercept empresa muadelante 0
#> student_t(3, 0, 2.5) sd time empresa muadelante 0
#> student_t(3, 0, 2.5) sd empresa muporandalucia 0
#> student_t(3, 0, 2.5) sd Intercept empresa muporandalucia 0
#> student_t(3, 0, 2.5) sd time empresa muporandalucia 0
#> student_t(3, 0, 2.5) sd empresa mupsoe 0
#> student_t(3, 0, 2.5) sd Intercept empresa mupsoe 0
#> student_t(3, 0, 2.5) sd time empresa mupsoe 0
#> student_t(3, 0, 2.5) sd empresa muresto 0
#> student_t(3, 0, 2.5) sd Intercept empresa muresto 0
#> student_t(3, 0, 2.5) sd time empresa muresto 0
#> student_t(3, 0, 2.5) sd empresa muvox 0
#> student_t(3, 0, 2.5) sd Intercept empresa muvox 0
#> student_t(3, 0, 2.5) sd time empresa muvox 0
#> ub tag source
#> default
#> (vectorized)
#> default
#> (vectorized)
#> default
#> (vectorized)
#> default
#> (vectorized)
#> default
#> (vectorized)
#> default
#> default
#> default
#> default
#> default
#> default
#> (vectorized)
#> default
#> default
#> default
#> default
#> default
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)
#> (vectorized)Revisamos Rhat, ESS y transiciones divergentes. Rhat debe estar cerca de 1 (< 1.01) y el ESS por encima de 400:
s <- summary(model_andalucia)
# Tabla compacta con los parámetros de población (fixed effects)
as.data.frame(s$fixed) |>
tibble::rownames_to_column("param") |>
select(param, Estimate, Est.Error, `l-95% CI`, `u-95% CI`, Rhat, Bulk_ESS, Tail_ESS) |>
mutate(across(where(is.numeric), \(x) round(x, 3)))
#> param Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS
#> 1 mupsoe_Intercept -0.650 0.026 -0.701 -0.598 1.000 9288.781
#> 2 muvox_Intercept -1.116 0.036 -1.189 -1.047 1.000 9377.694
#> 3 muporandalucia_Intercept -1.657 0.040 -1.738 -1.581 1.000 8151.630
#> 4 muadelante_Intercept -1.788 0.042 -1.874 -1.707 1.000 8962.274
#> 5 muresto_Intercept -2.066 0.091 -2.244 -1.878 1.001 3515.779
#> 6 mupsoe_time -0.001 0.001 -0.003 0.001 1.000 6588.495
#> 7 muvox_time 0.000 0.003 -0.006 0.005 1.001 4974.726
#> 8 muporandalucia_time 0.002 0.002 -0.002 0.006 1.001 4901.768
#> 9 muadelante_time 0.001 0.002 -0.002 0.006 1.000 5656.281
#> 10 muresto_time 0.001 0.002 -0.003 0.005 1.001 6966.390
#> Tail_ESS
#> 1 10533.134
#> 2 8621.706
#> 3 9186.438
#> 4 9129.060
#> 5 4798.607
#> 6 5867.615
#> 7 5490.541
#> 8 4329.370
#> 9 5875.265
#> 10 5491.566# Transiciones divergentes: deben ser 0
div <- nuts_params(model_andalucia) |>
dplyr::filter(Parameter == "divergent__") |>
dplyr::summarise(n_divergent = sum(Value))
div
#> n_divergent
#> 1 27pp_check() no está implementado para la familia multinomial, así que lo hacemos a mano: comparamos las proporciones predichas por el modelo (IC 50 % y 90 %) con las proporciones observadas en cada encuesta:
obs_props <- df_wider |>
mutate(across(c(pp, psoe, vox, por_andalucia, adelante, resto),
\(x) x / n)) |>
select(empresa, time, pp, psoe, vox, por_andalucia, adelante, resto) |>
pivot_longer(pp:resto, names_to = "partido", values_to = "obs")
pred_props <- df_wider |>
add_epred_draws(model_andalucia, ndraws = 200) |>
rename(partido = .category, pred = .epred) |>
ungroup() |>
mutate(pred = pred / n) |>
select(empresa, time, partido, pred, .draw)
pred_props |>
left_join(obs_props, by = c("empresa", "time", "partido")) |>
ggplot(aes(x = time, color = partido)) +
stat_lineribbon(aes(y = pred), .width = c(0.50, 0.90), alpha = 0.25) +
geom_point(aes(y = obs), size = 1.5) +
facet_wrap(~partido, scales = "free_y") +
scale_color_manual(values = colores, guide = "none") +
scale_fill_grey(start = 0.6, end = 0.85) +
labs(
title = "Posterior predictive check — multinomial",
subtitle = "Bandas: IC 50 % y 90 % del posterior · Puntos: proporción observada",
x = "Días hasta las elecciones", y = "Proporción"
) +
theme_minimal()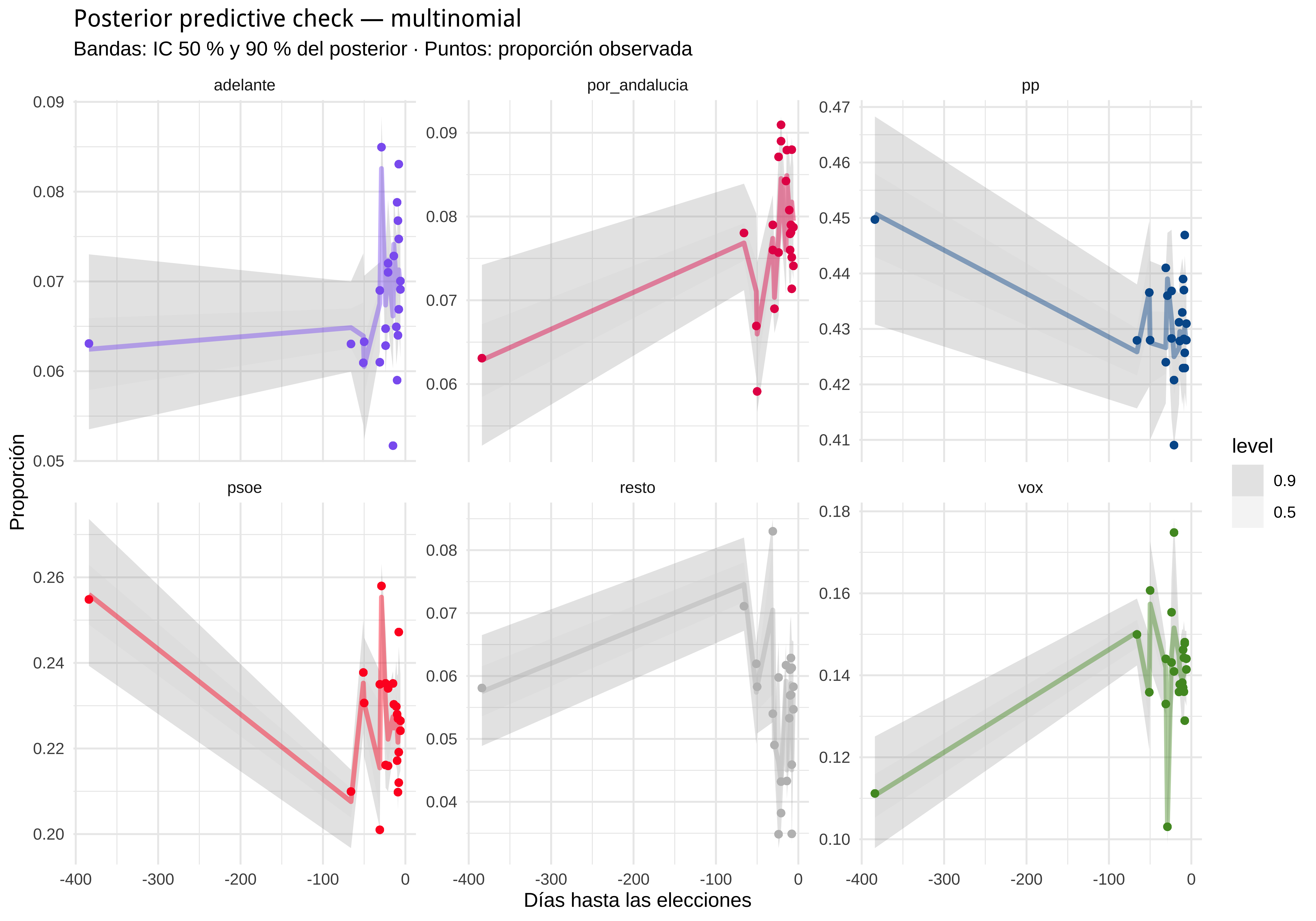
Tratamos las elecciones como una “nueva encuesta” con time = 0 y empresa desconocida:
newdata <- tibble(
empresa = "votaciones_17mayo",
time = 0,
n = 1
)
estimaciones <- newdata |>
add_epred_draws(model_andalucia, allow_new_levels = TRUE) |>
mutate(partido = as_factor(.category)) |>
select(-.category)
dim(estimaciones)
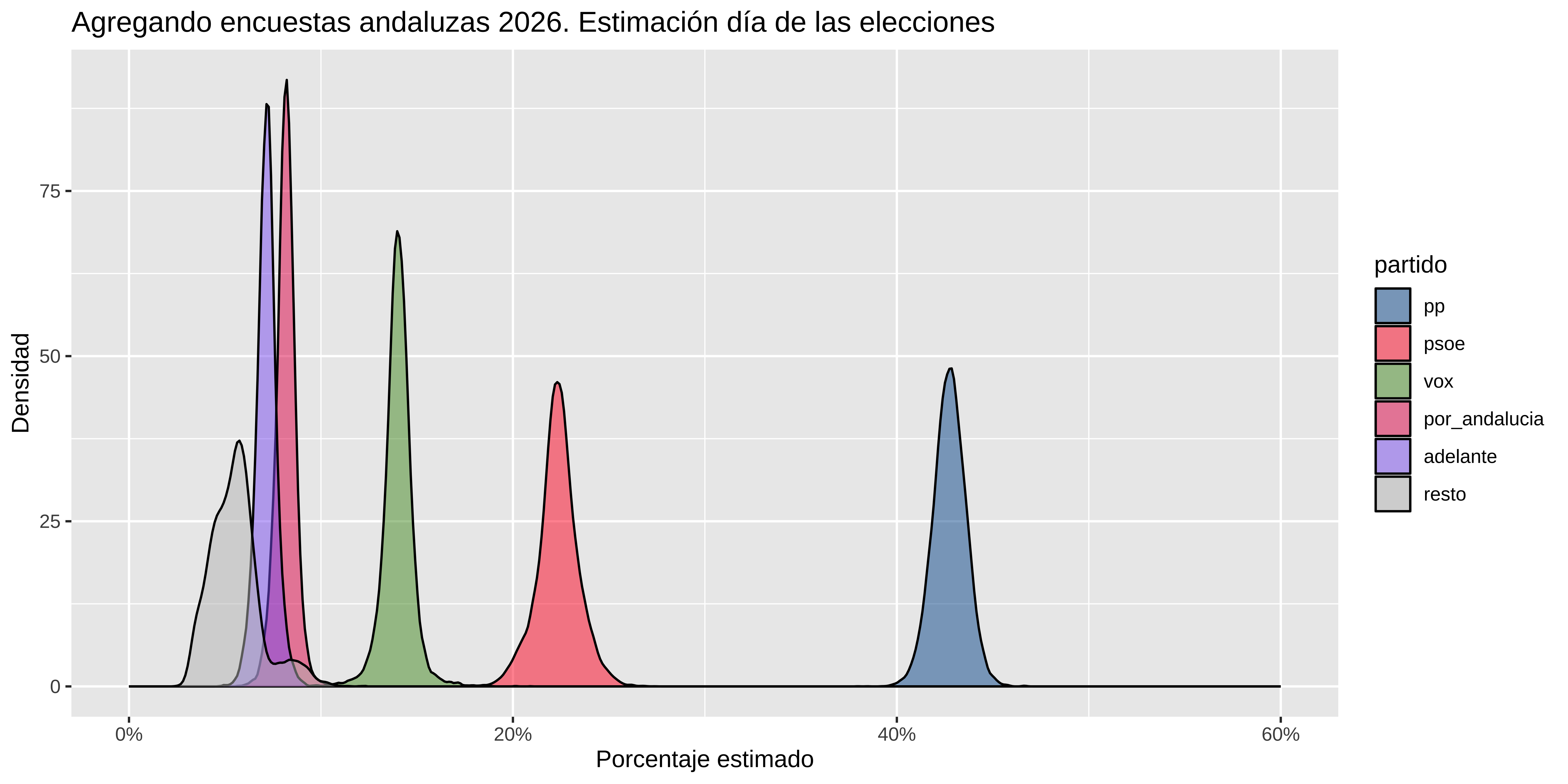
#> [1] 72000 10Resumen con intervalo de credibilidad al 90%:
estimaciones |>
group_by(partido) |>
summarise(
media = mean(.epred),
mediana = median(.epred),
low = quantile(.epred, 0.05),
high = quantile(.epred, 0.95)
) |>
mutate(across(media:high, \(x) 100 * round(x, 3)))
#> # A tibble: 6 × 5
#> partido media mediana low high
#> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 pp 42.7 42.8 41.3 44.1
#> 2 psoe 22.4 22.4 20.5 24.1
#> 3 vox 14 14 12.8 15.1
#> 4 por_andalucia 8.2 8.2 7.3 9
#> 5 adelante 7.2 7.2 6.3 8
#> 6 resto 5.6 5.5 3.6 8.4estimaciones |>
ggplot(aes(x = .epred, fill = partido)) +
geom_density(alpha = 0.5) +
scale_x_continuous(labels = scales::percent, limits = c(0, 0.6)) +
scale_fill_manual(values = colores) +
labs(
title = "Agregando encuestas andaluzas 2026. Estimación día de las elecciones",
x = "Porcentaje estimado",
y = "Densidad"
)
El Parlamento andaluz tiene 109 escaños; la mayoría absoluta son 55. No traduzco aquí porcentajes a escaños (necesitaría hacerlo provincia a provincia con D’Hondt), pero sí puedo ver la distribución del voto estimado al PP y compararlo con lo que necesitaría grosso modo.
estimaciones |>
filter(partido == "pp") |>
summarise(
prob_pp_sobre_40pct = mean(.epred > 0.40),
prob_pp_sobre_43pct = mean(.epred > 0.43)
)
#> # A tibble: 1 × 7
#> # Groups: empresa, time, n, .row [1]
#> empresa time n .row .category prob_pp_sobre_40pct prob_pp_sobre_43pct
#> <chr> <dbl> <dbl> <int> <fct> <dbl> <dbl>
#> 1 votacione… 0 1 1 pp 0.998 0.376Datos de 23 encuestas (fuente: Wikipedia EN, tabla de sondeos). La metodología es idéntica a los posts anteriores: modelo multinomial bayesiano con efectos aleatorios por empresa y tendencia temporal. Actualización post-electoral pendiente una vez se conozcan los resultados del 17-M.