ps1 <- rbeta(1000, 1, 3)
ps2 <- rbeta(300, 4, 1)
ps3 <- rbeta(600, 2, 60)
ps <- c(ps1, ps2, ps3)
mean(ps1) ; mean(ps2); mean(ps3)
#> [1] 0.2516992
#> [1] 0.8020855
#> [1] 0.03233513No mentirás
estadística
machine learning
python
R
2022
Hay veces que uno se deja llevar por la emoción cuando hace algo y a veces se exagera un poco con lo que hace tu criatura.
Tal es el caso de la librería Nanyml, la cual tiene buena pinta pero exagera en al menos dos partes. La primera y más evidente es cuándo dice que puede estimar el desempeño futuro de un modelo sin comparar con lo que realmente pase, así promete el Estimating Performance without Targets
Os juro que me he leído la documentación varias veces e incluso he visto el código y en ningún lado he visto que haga eso que promete.
En realidad lo que hace no es más que basarse en dos asunciones que, si se leen en primer lugar, hace que la afirmación presuntuosa de estimar el desempeño de un modelo sin ver el target se caiga por su propio peso. A saber, las dos asunciones son.
- El modelo retorna probabilidades bien calibradas siempre.
- La relación de \(P[y | X]\) no cambia .
Estas dos asunciones por si solas lo que nos dicen es que vas a medir el desempeño de un modelo (sin ver el verdadero valor del target) asumiendo de partida que el modelo es tan bueno como lo era cuando lo entrenaste.
La segunda parte es en lo que denomina CBPE algorithm que si se lee con atención no es otra cosa que simplemente utilizar el modelo para obtener predicciones sobre un nuevo conjunto de datos.
Así, para calcular el AUC estimado, lo que hace es asumir que el modelo es bueno, y obtener las diferentes matrices de confusión que se derivan de escoger los posibles puntos de corte y, aquí viene el tema, considerar que el valor predicho por el modelo, es el verdadero valor.
Con estas asunciones , cualquier cambio en la métrica del AUC se debería sólo y exclusivamente a cambios en la estructura de la población y no a que el modelo haya dejado de ser bueno (lo cual es imposible puesto que es una de las asunciones)..
Ejemplo. Si tenemos 3 grupos distintos dónde tenemos un evento binario. Supongamos que el primero de ellos viene de una población con proporción igual a 0.25, el segundo grupo viene de una población con proporción de 0.8 y el tercero de una población con proporción de 0.032. Si tomamos 1000, 300 y 600 observaciones de cada población respectivamente podemos simular tener un score que cumpla la condición de estar bien calibrado
La distribución de los “scores” sería
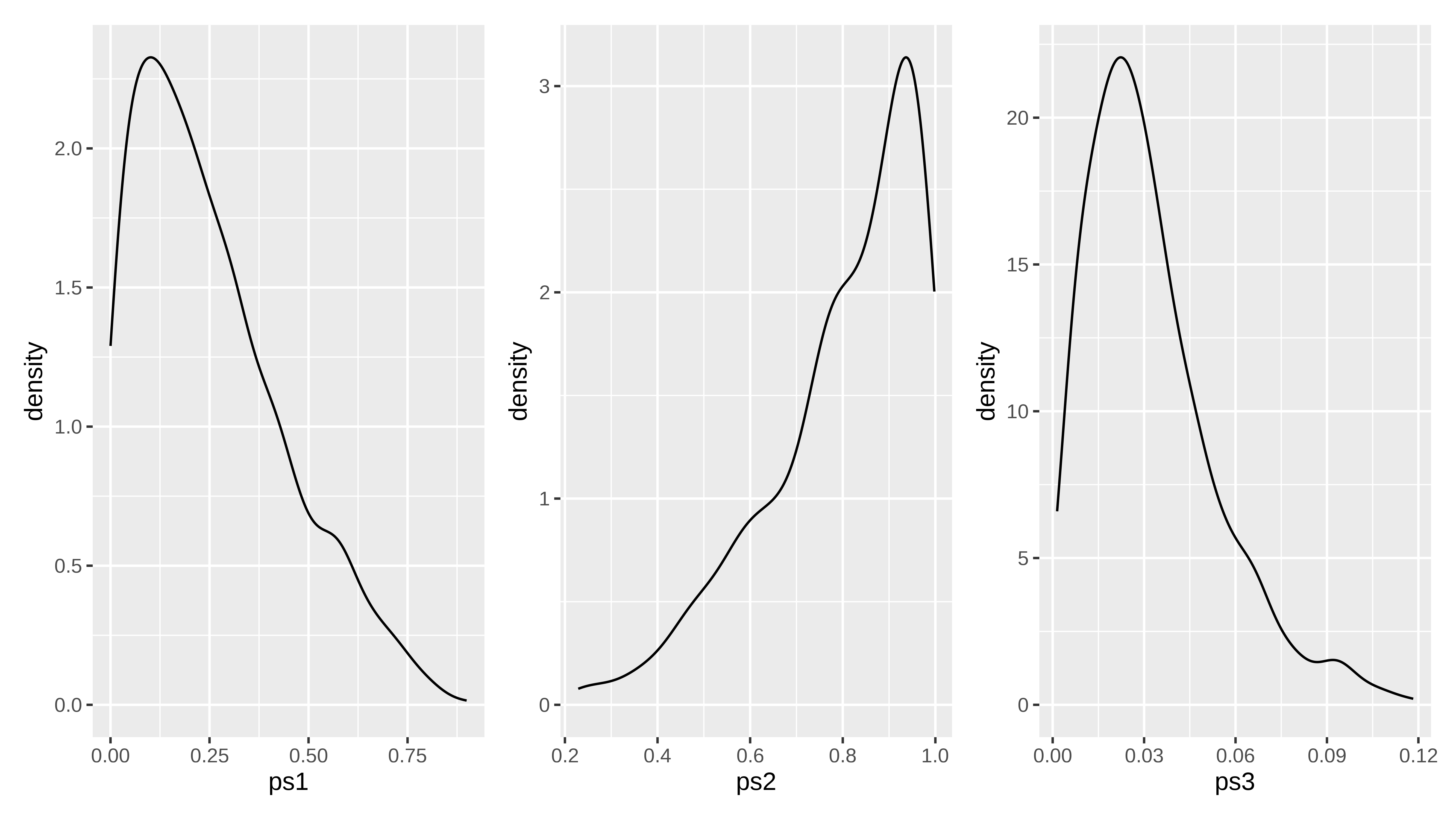
Pues el CBPE no sería otra cosa que calcular el auc del modelo ¡¡asumiendo que las probabilidades estimadas son correctas!! . Es como intentar demostrar algo teniendo como asunción que es cierto. Pero vayamos al cálculo.
Siguiendo lo descrito por la documentación y comprobando con el código de la librería se tendría que
tpr_fpr <- function(threshold, ps) {
yj <- ifelse(ps >= threshold, 1, 0)
p_false = abs(yj - ps)
p_true = 1- p_false
n <- length(yj)
tp <- sum(p_true[yj == 1])
fp <- sum(p_false[yj==1])
tn <- sum(p_true[yj==0] )
fn <- sum(p_false[yj==0] )
tpr <- tp / (tp + fn)
fpr <- fp /(fp + tn)
return(data.frame(tpr = tpr, fpr = fpr))
}
pscortes = sort(unique(ps), decreasing = TRUE)
dfs <- lapply(pscortes, function(x) tpr_fpr(x, ps))
valores <- do.call(rbind, dfs)
plot(valores$fpr, valores$tpr, type = "l")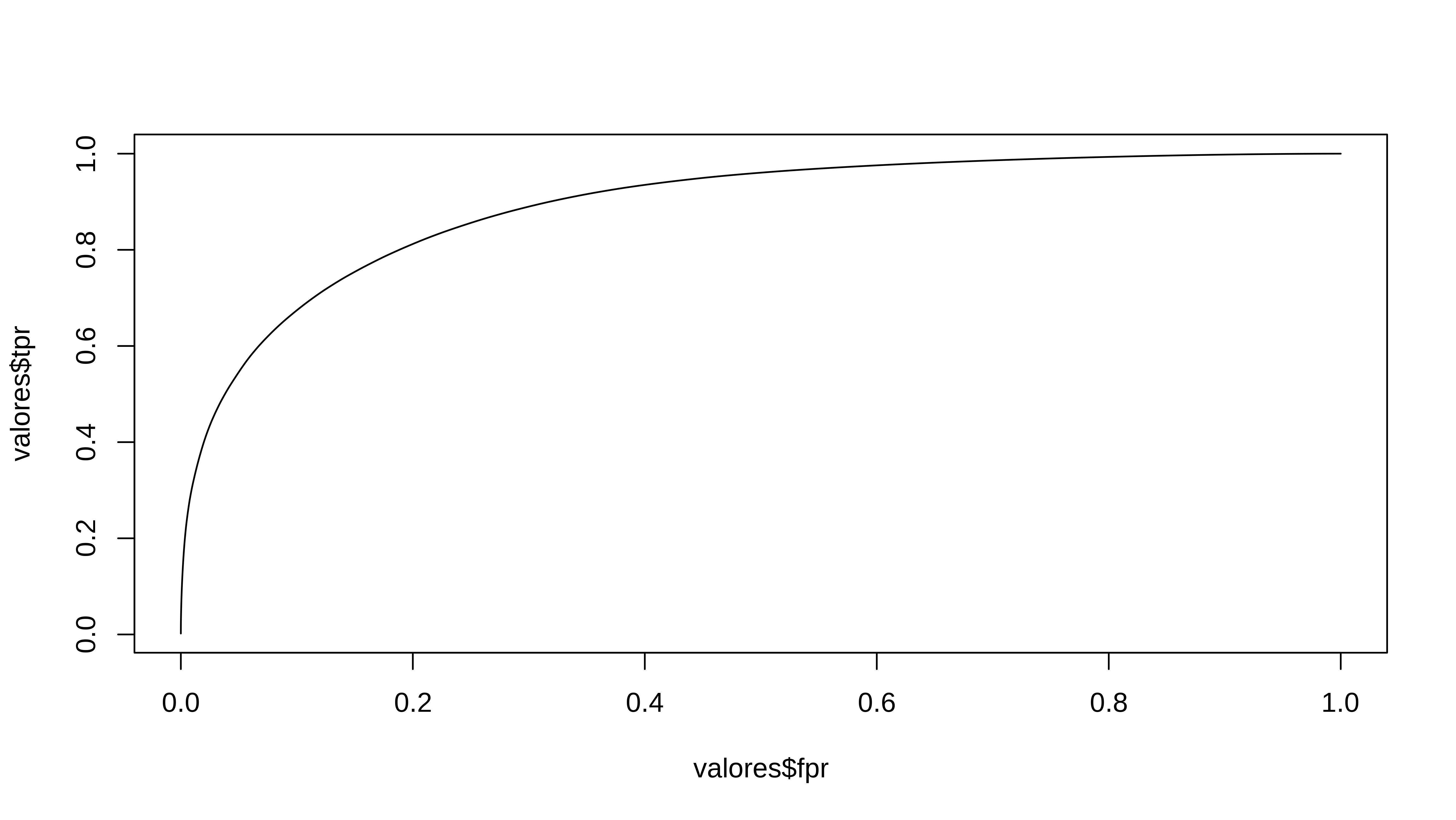
simple_auc <- function(TPR, FPR){
# inputs already sorted, best scores first
dFPR <- c(diff(FPR), 0)
dTPR <- c(diff(TPR), 0)
sum(TPR * dFPR) + sum(dTPR * dFPR)/2
}
with(valores, simple_auc(tpr, fpr))
#> [1] 0.8914538Cómo se ve, para calcular el auc sólo se tiene en cuenta las probabilidades estimadas, por lo que pierde todo el sentido para obtener un desempeño de cómo de bien lo hace el modelo.
De hecho, si hubiera simulado para cada observación una bernoulli tomando como probabilidad de éxito el score tendría lo siguiente, y tomo esa simulación como el valor real , obtengo el mismo auc que con CBPE.
labels <- rbinom(length(ps), 1, ps)
(res <- pROC::auc(labels, ps))
#> Area under the curve: 0.8962Es decir, en la misma definición de lo que es una matriz de confusión y las métricas asociadas va implícita la idea de comparar la realidad con la estimación, si sustituyes la realidad por la estimación , entonces pierde el sentido.
Pero veamos para qué si puede servir esta cosa. Pues nos puede servir para detectar cambios de distribuciones conjuntas entre dos conjuntos de datos. Me explico, supongamos que quiero predecir sobre un conjunto de datos que en vez de tener 1000 observaciones de la primera población hay 200, y que de la segunda hay 100 y 10000 de la tercera. Pues en este caso, el cambio en el auc se debe solo a eso, al cambio de la estructura de la población global.
ps1_new <- rbeta(200, 1, 3)
ps2_new <- rbeta(100, 4, 1)
ps3_new <- rbeta(10000, 2, 60)
ps_new <- c(ps1_new, ps2_new, ps3_new)labels <- rbinom(length(ps_new), 1, ps_new)
(res <- pROC::auc(labels, ps_new))
#> Area under the curve: 0.7616La bajada del “auc estimado” solo se debe a cambios en la estructura de la nueva población que tiene muchas más observaciones de la población 3.
Por lo tanto, lo que nannyml hace y no está mal, ojo, es simplemente ver cuál serían métricas agregadas (como el auc) cuando cambia la estructura pero no la probabilidad condicionada de y con respecto a las variables independientes.
Lo que no me parece bien es poner en la documentación que calcula el desempeño de un modelo sin ver el target, puesto que confunde y ya ha dado lugar a algún post en “towards data science” (gente, formaros primero con libros antes de leer post de estos sitios) con más humo que madera.
Y como se suele decir “No mentirás”.