Ya estuve hablando anteriormente de los Metalearners o como se diga aquí y aquí. Pero ahora vamos a ver si lo utilizamos en unos datos reales.
La encuestas de estructura salarial se ha usado muchas veces para ver la brecha salarial entre hombre y mujeres. No obstante yo me hago la pregunta de si es posible y cómo estimar la brecha salarial entre sector público y sector privado.
¿Cómo podríamos hacerlo? Está claro que son dos sectores muy distintos y que comparar las medias, tal y como hacen (mal) algunos para comparar brecha salarial de género, no es lo más adecuado.
Mi idea aquí es contar un poco como lo haríamos estilo compadre usando un modelo lineal de toda la vida, luego ver como se haría utilizando metalearners y también usando doubly robust estimator .
Datos
Vamos a utilizar los microdatos de la encuestas de estructura salarial del INE. A pesar de ser una encuesta anual, los últimos resultados publicados son de 2021 y los últimos microdatos disponibles los de 2018. La verdad es que me gustaría entender por qué el INE publica tan tarde los microdatos 😥. La nota de prensa con los resultados de 2021 es del 20 de junio de 2023. Y si ya tienen resultados de 2021, ¿por qué los últimos microdatos disponibles son los de hace 5 años?
Sea como fuere vamos a lo nuestro.
Mostrar / ocultar código
library(tidyverse)library(haven) # Para leer los datos de SPSSlibrary(survey) # para obtener estimadores correctos por ser una muestralibrary(sjPlot) # plot de los modelos, # library(causact) # usar alguna cosa de numpyro desde R , quiero probar este paquete
Aunque en el fichero comprimido que te descargas del INE viene script para leer los datos con R, no me gusta ese script que instala XLConnect y no sé qué más. Así que lo que he hecho es leer el fichero en formato de spss con haven::read_spss() y luego limpiarlos un poco con janitor::clean_names().
Lo que quiero comparar es el salario neto mensual, ¿por qué? porque me da la gana y porque en la docu del INE explican como se calcula el salario neto partiendo de los microdatos.
Así de primeras, pues parece que se gana más en el sector público que en el privado, pero ¡ojo! que la encuesta tiene una variable de ponderación, que el INE ha calculado para que los resultados sean representativos de la población. En la nota metodológica el INE dice lo siguiente sobre el plan de muestreo
El procedimiento de selección aleatoria de unidades corresponde a un muestreo bietápico estratificado, donde las unidades de primera etapa son las cuentas de cotización a la Seguridad Social (CC), mientras que las de segunda etapa son los trabajadores (asalariados). En la primera etapa tanto el diseño muestral como la muestra obtenida de CC coincide con la ETCL (para una mayor información consultar la metodología de la ETCL). Las unidades de primera etapa se estratifican según las siguientes variables:
Comunidad autónoma
Rama de actividad económica (división de la CNAE-09)
Tamaño, medido por el número de asalariados en cada CC
En los microdatos tenemos la variable factotal que es la ponderación que el INE dice que hay que usar a la hora de hacer estimaciones.
Pero sabemos que la media tal cual puede no ser un buen indicador, lo suyo sería controlar (condicionar) por otras variables, tales como el sexo, nivel de estudio, edad, años de antigüedad , tipo de jornada laboral, y cosas así.
Hagámoslo, pero usando que tenemos pesos en la encuesta.
Mostrar / ocultar código
disenno <-svydesign(id =~1, weight =~factotal, data = ess)
Modelo simple dónde uso variables como edad, tipo contrato, área nuts, antigüedad, nivel de estudios, etc..
Y el coeficiente asociaso al sector público indica que se gana en media unos 112 euros más que en el sector privado, según este modelo.
¿Cuánto sería para alguien que trabaja a jornada completa, nivel de estudios superior o igual a licenciado?
Para eso podemos hacer lo que se conoce como una “intervención”, que es crear dos conjuntos de datos copias del original, con la diferencia de que en uno todo el mundo es del sector privado y en el otro todos del sector público y comparamos las medias estimadas de salario neto que nos da el modelo para el subgrupo de población que queramos.
A esto se le conoce por los modernos como un S-learner
Y coincide con el coeficiente que daba el modelo. Y eso es así porque no he metido interacciones en el modelo. Si metemos una simple interacción entre ser del sector público y privado con la zona Nuts1.
Estimamos diferencias entre sector público y privado para Madrid y Andalucía, para un hombre a jornada completa y con estudios de licenciatura o superior.
Bueno, pues según esto, parece que para ese perfil, dónde se ha tenido en cuenta edad, años de antigüedad y demás, se gana un poco más en el sector público que en el privado, aunque esa diferencia es mayor en el Sur que en Madrid.
T- learner
Otro de los metalearners empleados es el T-learner, ya explicado en post anteriores. Aquí vamos a usarlo sin tener en cuenta la ponderación de la encuesta.
En el T-learner se ajusta un modelo para cuando sea sector público y otro para cuando sea sector privado y se ve la diferencia de las medias de sus estimaciones.
En este caso, nos sale que se ganaría más en el sector público que en el privado. ¿Con qué nos quedamos?
X-learner
Ya expliqué en su día en que consiste un X-learner (../2020/12/30/y-si-parte-ii/#x-learner)
Básicamente, usas el modelo ajustado con treatment = 1 para predecir las observaciones con treatment = 0 y al revés en un intento de estimar el potential outcome. Luego haces dos modelos para modelar las diferencias entre el outcome y las predicciones anteriores y otro modelo de propensity score que se usará para ponderar esas dos predicciones.
Con idea parecida al X-learner , en el sentido de mezclar las estrategias de usar Inverse probability weighting y el de hacer un modelo de la respuesta condicionando por los counfounders.
De nuevo, al igual que con el T-Learner o el X-Learner no vamos a tener en cuenta la variable de ponderación de casos.
Dónde \(\mu\) hace referencia al modelo para estimar el outcome y \(\pi\) al modelo de propensity score.
Este Doubly robust estimator es una combinación entre usar inverse probability weighting y el modelo de la media del outcome. Este estimador suele ser consistnete si al menos uno de los dos modelos es correcto. A la expresión coloreda en rojo se le denomina augmented IPW estimator
El S-learner usando ponderación de observaciones, el doubly robust y estimator (sin usar ponderaciones) y el x-learner nos dan estimaciones diciendo que se gana más en el sector público que en el privado, mientras que el t-learner nos dice lo contrario.
Así que, no me queda claro la respueta a la pregunta inicial.
Me acabo de acordar de otra forma de estimar esto. Consiste en:
Hago un modelo para estimar el salario neto pero sólo usando la población que trabaja en el sector privado.
Aplico ese modelo para obtener estimaciones sobre la población que trabaja en el sector público.
Comparo la estimación obtenida con el salario neto de esa subpoblación.
Es parecido al X-learner, pero sin tanta complicación. Es como decir ¿cuánto ganarían los que están en el sector público si estuvieran en el privado?
Al hacerlo así hay que obviar en el modelo en la subpoblación para el sector privado, las variables de cnace y de cno1 puesto que tienen niveles en el sector público que no están en el privado y el modelo daría error por niveles nuevos. Un modelo mixto si podría hacer eso.
Y haciéndolo así se tendría que si los trabajadores del sector público hombres a jornada completa y con estudios de licenciados o superiores lse cambiaran al privado, manteniendo el resto igual ganarían unos 124 euros menos al mes de media.
Así que tengo varias preguntas
¿Qué piensan mis escasos lectores a la vista de estas estimaciones? ¿Hay brecha salarial?
Sea cual sea la respuesta, ¿no os parece que podría utilizar un método u otro según lo que me interese contar? Dan ganas de escribir un manual sobre como “engañar con estadística de forma avanzada”, pero ya conozco a quien tiene esa idea en mente
¿Cuál sería la metodología correcta si es que existe? ¿Quizá adentrándonos en el mundo bayesiano? ¿o es todo un artificio “técnico”?
Otra actualización
Una de las hipótesis es que en el sector privado la distribución es más dispersa.
Todo esto debería haberse hecho antes que todos los modelos. EL EDA es lo primero.
Mostrar / ocultar código
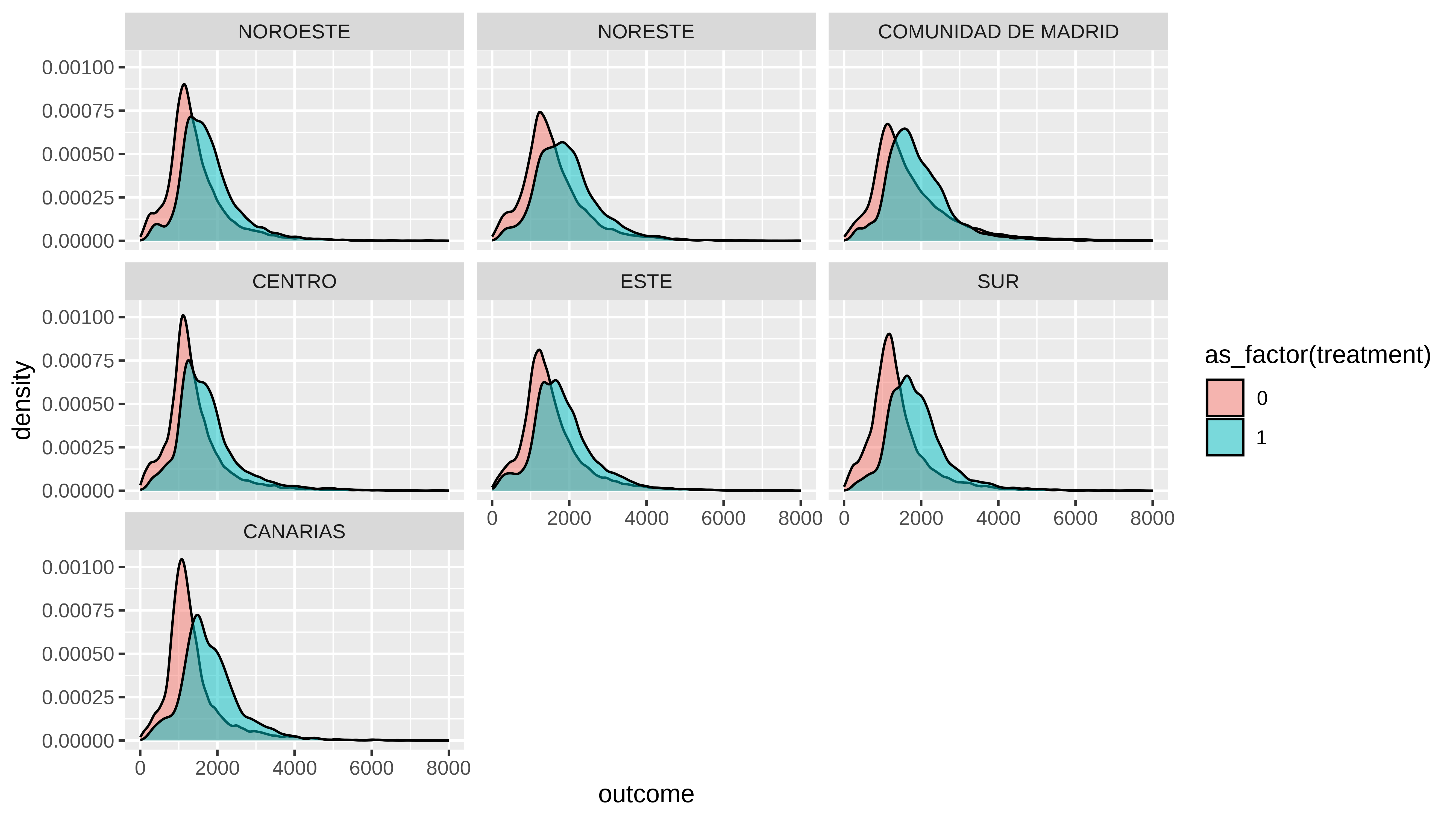
# En general parece que no ess |>mutate(nuts1 =as_factor(nuts1)) |>ggplot(aes(x =outcome,fill =as_factor(treatment))) +geom_density(alpha =0.5) +scale_x_continuous(limits =c(0,8000)) +facet_wrap( ~ nuts1)
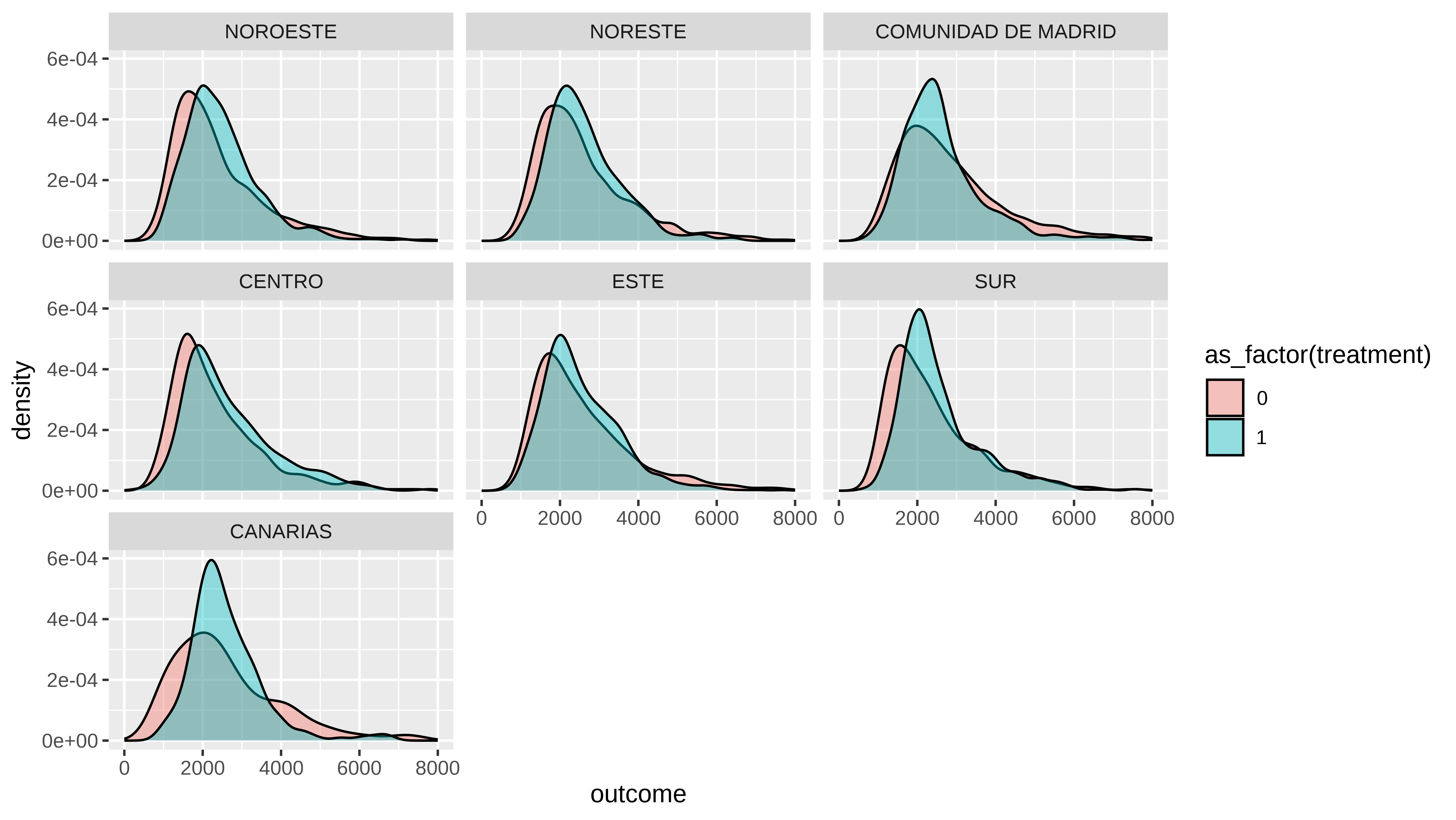
Pero y si la vemos, para los licenciados, hombres y a jornada completa.
En la comunidad de Madrid y en Canarias si se aprecia que en la cola de la derecha es superior la función de densidad en el sector privado.
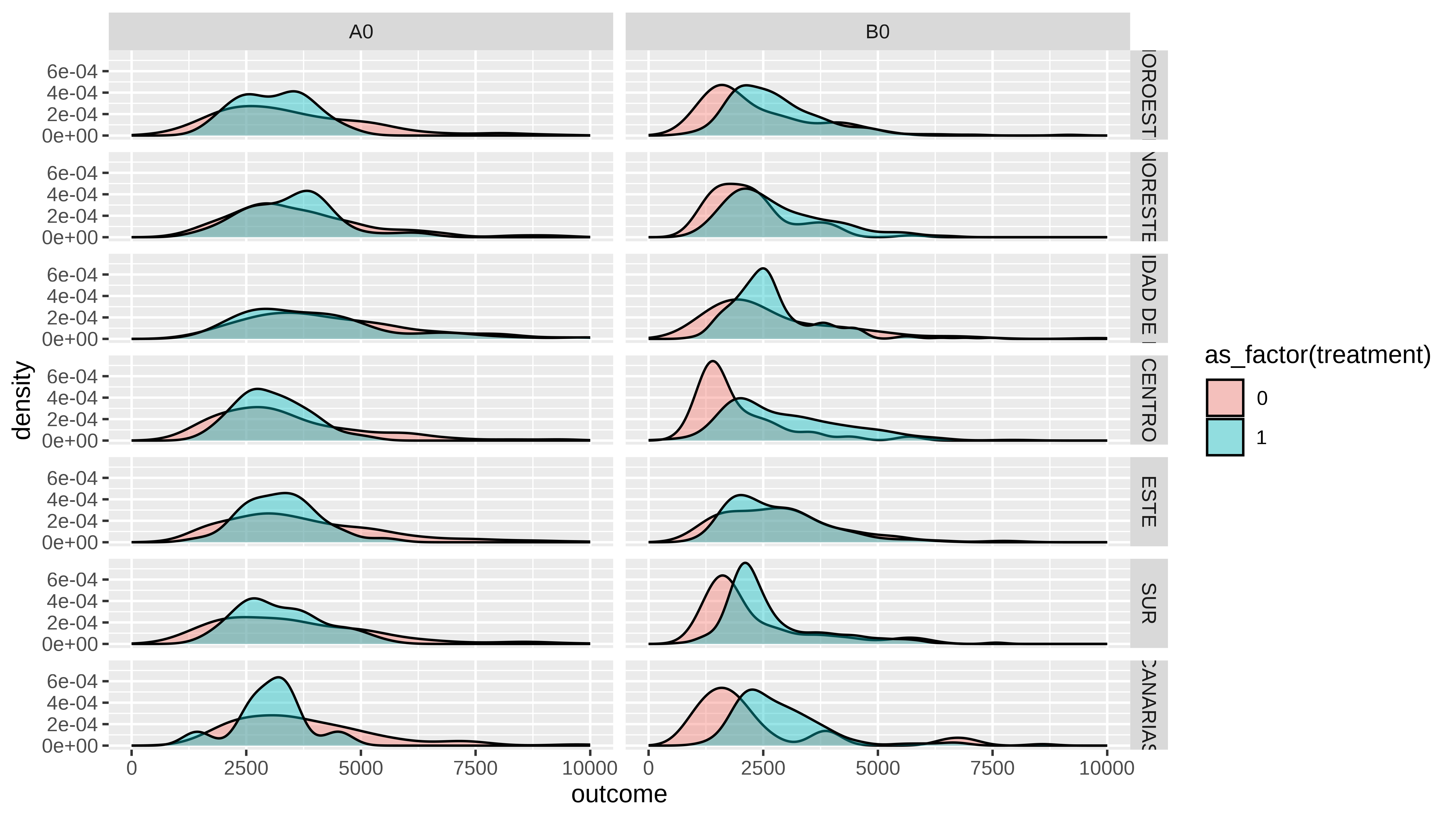
Y si lo vemos para un par de ocupaciones, tales como Directores y gerentes (A0) y para técnicos y profesionales científicos e intelectuales de la salud y la enseñanza(B0).
Gerentes (A0) mejor en el privado, curritos de la enseñanza y la salud pues..
Pero claramente como lo que predice es la media condicionada queda todo muy “centrado”. Lo suyo sería un modelo bayesiano o hacer boostraping y tener la posterior predictive, para incorporar correctamente la variabilidad. A ver si lo hago en otro post, pero con numpyro, que stan no puede con estos datos
Coda
Es complicado dar una respuesta concluyente a la pregunta inicial.
Mi objetivo era sólo contaros algunas formas de estimar “efectos causales”, o si es gusta más, diferencias entre grupos condicionando por variables
La inferencia causal es complicada, ha de sustentarse en un análisis teórico previo. Yo he decidido que no había colliders por ejemplo
He obviado variables que podrían influir tanto en la variable respuesta como en el tratamiento (sector público o privado), pero estos son datos reales, no una simulación ad hoc, y en el mundo real tienes que tomar decisiones y apechugar con ellas.
Para escribir este post lo he hecho con Rstudio y con el github copilot activado y la verdad es que ayuda bastante, incluso a completar las fórmulas en latex.
Corrección
corrección 2024-10-12
Preparando taller de inferencia causal estaba repasando este post y he visto que tenía un error en el x-learner. Corregido.