library(tidyverse)
root_directory = "~/proyecto_cachitos/"
anno <- "2023"
nombre_ficheros <- list.files(path = str_glue("{root_directory}{anno}_txt/")) %>%
enframe() %>%
rename(n_fichero = value)
nombre_ficheros
#> # A tibble: 687 × 2
#> name n_fichero
#> <int> <chr>
#> 1 1 00000004.jpg.subtitulo.tif.txt
#> 2 2 00000010.jpg.subtitulo.tif.txt
#> 3 3 00000011.jpg.subtitulo.tif.txt
#> 4 4 00000012.jpg.subtitulo.tif.txt
#> 5 5 00000018.jpg.subtitulo.tif.txt
#> 6 6 00000019.jpg.subtitulo.tif.txt
#> 7 7 00000020.jpg.subtitulo.tif.txt
#> 8 8 00000025.jpg.subtitulo.tif.txt
#> 9 9 00000026.jpg.subtitulo.tif.txt
#> 10 10 00000027.jpg.subtitulo.tif.txt
#> # ℹ 677 more rowsCachitos 2023. Segunda parte
estadística
polémica
2024
textmining
ocr
linux
cachitos
Una vez que ya hemos visto en la entrada anterior como extraer los rótulos, vamos a juntarlos todos en un sólo csv y hacer algo de limpieza.
Dejo el enlace a los ficheros de texto construidos por tesseract enlace directorio
Lectura rótulos
Ahora los podemos leer en orden
subtitulos <- list.files(path = str_glue("{root_directory}{anno}_txt/"),
pattern = "*.txt", full.names = TRUE) %>%
map(~read_file(.)) %>%
enframe() %>%
left_join(nombre_ficheros)
glimpse(subtitulos)
#> Rows: 687
#> Columns: 3
#> $ name <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…
#> $ value <list> "ey ÁNGEL CARMONA | y\n.».\n\n \n\f", "DAVID BISBAL - Llora…
#> $ n_fichero <chr> "00000004.jpg.subtitulo.tif.txt", "00000010.jpg.subtitulo.ti…
subtitulos
#> # A tibble: 687 × 3
#> name value n_fichero
#> <int> <list> <chr>
#> 1 1 <chr [1]> 00000004.jpg.subtitulo.tif.txt
#> 2 2 <chr [1]> 00000010.jpg.subtitulo.tif.txt
#> 3 3 <chr [1]> 00000011.jpg.subtitulo.tif.txt
#> 4 4 <chr [1]> 00000012.jpg.subtitulo.tif.txt
#> 5 5 <chr [1]> 00000018.jpg.subtitulo.tif.txt
#> 6 6 <chr [1]> 00000019.jpg.subtitulo.tif.txt
#> 7 7 <chr [1]> 00000020.jpg.subtitulo.tif.txt
#> 8 8 <chr [1]> 00000025.jpg.subtitulo.tif.txt
#> 9 9 <chr [1]> 00000026.jpg.subtitulo.tif.txt
#> 10 10 <chr [1]> 00000027.jpg.subtitulo.tif.txt
#> # ℹ 677 more rowsTenemos 687 rótulos de los cuales la mayoría estarán vacíos
Contando letras
En n_fichero tenemos el nombre y en value el texto. Si vemos alguno de los subtítulos.
subtitulos %>%
pull(value) %>%
pluck(239)
#> [1] "El Darth Vader español: tiene la voz profunda,\n\nun lado oscuro y podría ser tu padre\n\n \n\f"Contemos letras.
subtitulos <- subtitulos %>%
mutate(n_caracteres = nchar(value))
subtitulos %>%
group_by(n_caracteres) %>%
count()
#> # A tibble: 105 × 2
#> # Groups: n_caracteres [105]
#> n_caracteres n
#> <int> <int>
#> 1 10 5
#> 2 12 3
#> 3 13 1
#> 4 15 1
#> 5 18 1
#> 6 21 2
#> 7 22 1
#> 8 23 1
#> 9 29 1
#> 10 32 4
#> # ℹ 95 more rows
subtitulos %>%
group_by(n_caracteres) %>%
count() %>%
ggplot(aes(x = n_caracteres, y = n)) +
geom_col()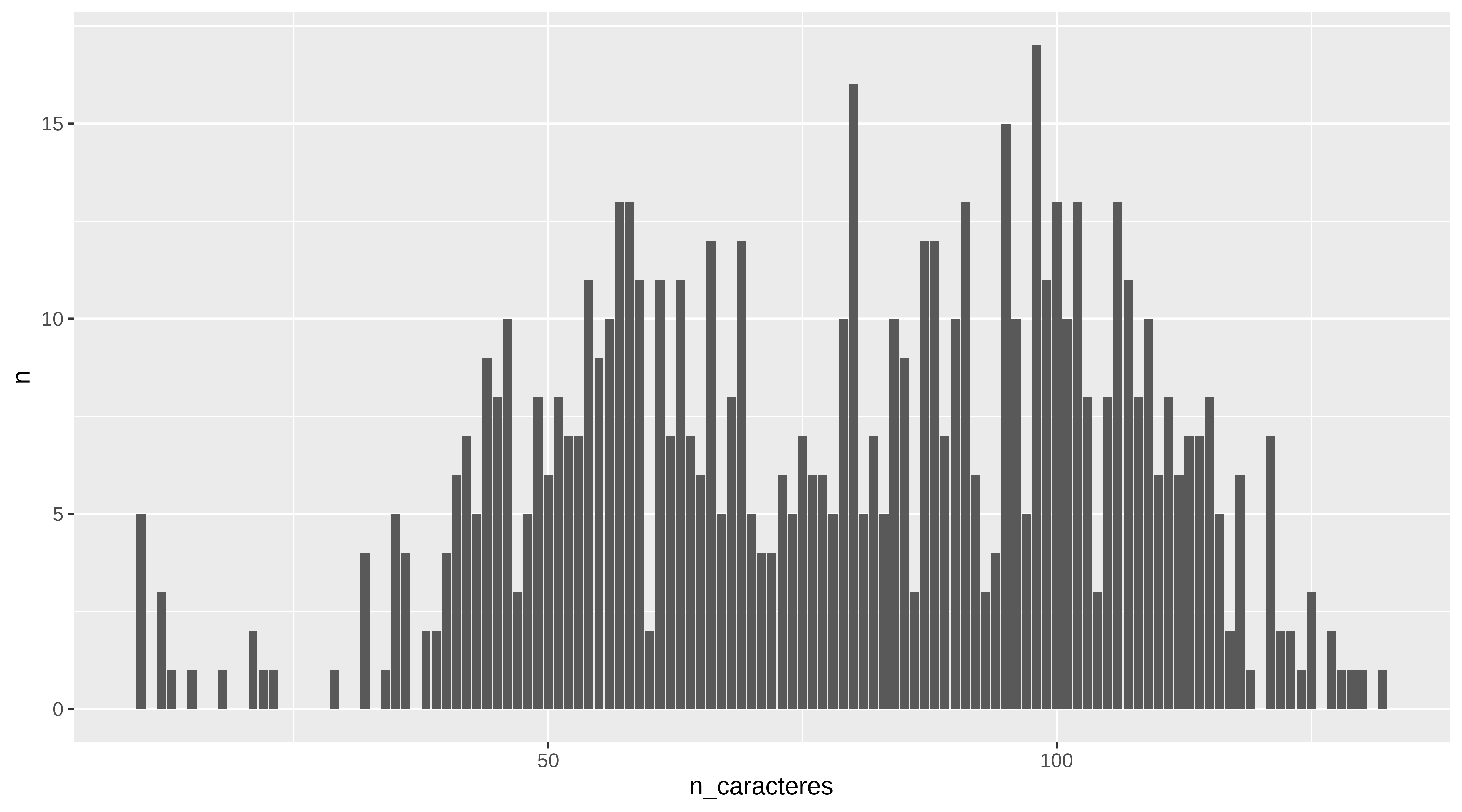
Y viendo el conteo podríamos ver cómo son los rótulos con menos de 25 caracteres. Y suele ser por haber pillado el nombre de la canción en vez del rótulo
subtitulos %>%
filter(n_caracteres <= 25, n_caracteres > 0 ) %>%
arrange(desc(n_caracteres)) %>%
head(40) %>%
pull(value)
#> [[1]]
#> [1] "Para Crazy, su padre.\n\f"
#>
#> [[2]]
#> [1] "—\nNATALIA LAFOURCADE\n\f"
#>
#> [[3]]
#> [1] "HO *\n\n= Roland 7-50\n\f"
#>
#> [[4]]
#> [1] "Os lo dijimos.\n\n \n\f"
#>
#> [[5]]
#> [1] "pee\n\nES\n\no\n\nMIEL\n\f"
#>
#> [[6]]
#> [1] "¿Es ANO MN ss\n\f"
#>
#> [[7]]
#> [1] "The GodFary\n\f"
#>
#> [[8]]
#> [1] "Mar y sol.\n\f"
#>
#> [[9]]
#> [1] "NA PAL =>:\n\f"
#>
#> [[10]]
#> [1] "O AA A\nA E\n\f"
#>
#> [[11]]
#> [1] "WI ES MO\n\f"
#>
#> [[12]]
#> [1] "QA Y EPA\n\f"
#>
#> [[13]]
#> [1] "SN\n1\nO y\n\f"
#>
#> [[14]]
#> [1] " \n\nml\n\n \n\f"
#>
#> [[15]]
#> [1] "ly\nMi\n\n \n\f"subtitulos %>%
filter(n_caracteres >= 30) %>%
arrange(n_caracteres)
#> # A tibble: 671 × 4
#> name value n_fichero n_caracteres
#> <int> <list> <chr> <int>
#> 1 151 <chr [1]> 00000309.jpg.subtitulo.tif.txt 32
#> 2 176 <chr [1]> 00000361.jpg.subtitulo.tif.txt 32
#> 3 513 <chr [1]> 00001015.jpg.subtitulo.tif.txt 32
#> 4 677 <chr [1]> 00001333.jpg.subtitulo.tif.txt 32
#> 5 466 <chr [1]> 00000917.jpg.subtitulo.tif.txt 34
#> 6 170 <chr [1]> 00000346.jpg.subtitulo.tif.txt 35
#> 7 241 <chr [1]> 00000496.jpg.subtitulo.tif.txt 35
#> 8 361 <chr [1]> 00000733.jpg.subtitulo.tif.txt 35
#> 9 446 <chr [1]> 00000877.jpg.subtitulo.tif.txt 35
#> 10 687 <chr [1]> 00001353.jpg.subtitulo.tif.txt 35
#> # ℹ 661 more rowsUsando la librería magick en R que permite usar imagemagick en R, ver post de Raúl Vaquerizo y su homenaje a Sean Connery, podemos ver el fotgrama correspondiente
library(magick)
(directorio_imagenes <- str_glue("{root_directory}video/{anno}_jpg/"))
#> ~/proyecto_cachitos/video/2023_jpg/
image_read(str_glue("{directorio_imagenes}00000383.jpg"))
Así que nos quedamos con los rótulos con más de 30 caracteres
subtitulos <- subtitulos %>%
filter(n_caracteres > 30)
dim(subtitulos)
#> [1] 671 4Detección duplicados
Mini limpieza de caracteres extraños y puntuación
string_mini_clean <- function(string){
string <- gsub("?\n|\n", " ", string)
string <- gsub("\r|?\f|=", " ", string)
string <- gsub('“|”|—|>'," ", string)
string <- gsub("[[:punct:][:blank:]]+", " ", string)
string <- tolower(string)
string <- gsub(" ", " ", string)
return(string)
}
# Haciendo uso de programación funciona con purrr es muy fácil pasar esta función a cada elemento. y decirle que
# el resultado es string con map_chr
subtitulos_proces <- subtitulos %>%
mutate(texto = map_chr(value, string_mini_clean)) %>%
select(-value)
subtitulos_proces %>%
select(texto)
#> # A tibble: 671 × 1
#> texto
#> <chr>
#> 1 "david bisbal lloraré las penas noche de fiesta 2002 "
#> 2 "bueno cómo están los máquinas lo primero de todo estáis bien "
#> 3 "pues eso que hemos venido a bailar a cantar y si hay que llorar las penas d…
#> 4 "rayden calle de la llorería benidorm fest 2021 "
#> 5 "la verdad es que rayden por no ir a eurovisión con esta canción no lloró mu…
#> 6 "anunció que se iba a retirar cuando lo veamos lloramos "
#> 7 "fangoria dramas y comedias feliz 2015 "
#> 8 "para algunos el año ha sido más dramático que cómico y viceversa "
#> 9 "aunque también ha habido muchos como nacho canut a su bola "
#> 10 "rozalén con estopa vivir territorio estopa 2019 "
#> # ℹ 661 more rowsDistancia de texto entre rótulos consecutivos
subtitulos_proces <- subtitulos_proces %>%
mutate(texto_anterior = lag(texto)) %>%
mutate(distancia = stringdist::stringdist(texto, texto_anterior, method = "lcs"))
subtitulos_proces %>%
filter(!is.na(distancia)) %>%
select(name,texto,distancia, texto_anterior, everything()) %>%
arrange(distancia) %>%
DT::datatable(options = list(scrollX=TRUE))Decidimos eliminar texto cuya distancia sea menor de 30
subtitulos_proces <- subtitulos_proces %>%
filter(distancia >= 30) %>%
select(-texto_anterior)
subtitulos_proces %>%
select(name,texto, everything()) %>%
DT::datatable()No nos hemos quitado todos los duplicados pero sí algunos de ellos.
dim(subtitulos_proces)
#> [1] 583 5Y ya solo tenemos 583 rótulos
Guardamos el fichero unido
write_csv(subtitulos_proces,
file = str_glue("{root_directory}{anno}_txt_unido.csv"))
DT::datatable(
subtitulos_proces %>%
select(-distancia) %>%
arrange(n_fichero))Y aquí os dejo el enlace con los rótulos definitivos