Cuenta Richard McElreath en sus vídeos de Statistical Rethinking que la inferencia causal no es más que predecir la intervención. Una de las cosas que más me llamó la atención es lo que él llama “full luxury bayes”. El “full luxury” permite ajustar todo el DAG de un modelo causal, permitiéndonos cosas que los seguidores de Pearl dicen que no se puede hacer, cosas como condicionar por un collider o cosas así.
Una vez tenemos el DAG entero ajustado conjuntamente, podemos hacer cosas como simular la intervención. Esto no es más que - oye, ¿qué hubiera pasado si todo los individuos hubieran recibido el tratamiento?, ¿y si todos hubieran estado en control?- y de esta forma podemos estimar lo que queremos, que unos lo llaman el efecto causal, o ATE (average treatmen effect) y cosas así.
Ejemplo simulado
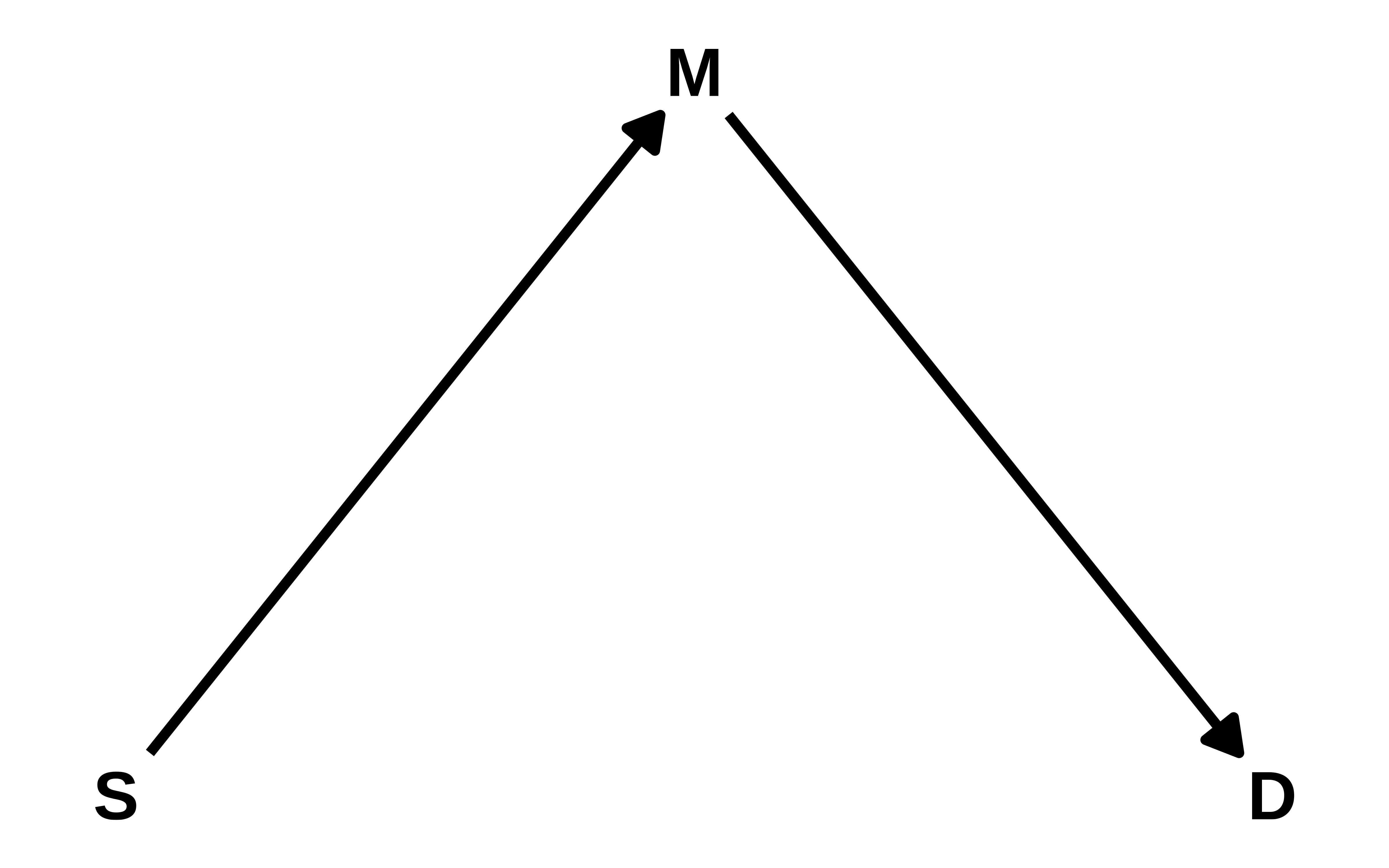
Supongamos que tenemos un DAG. Y que el DAG es correcto. Esto que acabo de escribir, de que el DAG es correcto es la principal asunción de toda la inferencia causal. No hay inferencia causal sin una descripción explícita de tu modelo causal (Ciencia antes que estadística). Las técnicas de inferencia causal son sólo herramientas técnicas que nos ayudarán a estimar el efecto. Pero si nuestras asunciones son incorrectas, no hay técnica que nos salve.
Vamos a simular los datos, de forma que sabremos cuál es el verdadero efecto causal.
Show the code
S <-rbinom(100,1, 0.3)M <-2* S +rnorm(100, 0, 1)D <-5+5* M +rnorm(100, 0, 1)
Sabemos que el efecto total de S sobre D es de 10. Por ser M una variable mediadora, y tal como hemos generado los datos se multiplican los coeficientes.
Usando dagitty
dagitty nos permite saber por qué variabbles hemos de condicionar, según los criterios de Pearl, para obtener diferentes efectos.
Y vemos que no hay que “controlar” por ninguna variable para obtener el efecto de S sobre D
Show the code
df <-data.frame(S = S , D = D, M = M)mod_simple_correcto <-lm(D ~ S, data = df)summary(mod_simple_correcto)#> #> Call:#> lm(formula = D ~ S, data = df)#> #> Residuals:#> Min 1Q Median 3Q Max #> -12.7691 -3.8648 -0.5862 3.6303 14.5658 #> #> Coefficients:#> Estimate Std. Error t value Pr(>|t|) #> (Intercept) 4.6562 0.7031 6.622 1.91e-09 ***#> S 11.4955 1.1559 9.945 < 2e-16 ***#> ---#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#> #> Residual standard error: 5.581 on 98 degrees of freedom#> Multiple R-squared: 0.5023, Adjusted R-squared: 0.4972 #> F-statistic: 98.9 on 1 and 98 DF, p-value: < 2.2e-16
Y obtenemos el coeficiente correcto.
Full luxury bayes
En modelos sencillos usar dagitty nos permite encontrar el mínimo conjunto de variables por las que controlar, para encontrar el efecto que buscamos. Pero pueden darse situaciones en las que sea necesario condicionar por una variable que en un “path” sea una variable de confusión, mientras que en otro sea un “collider”. En esos casos hay que recurrir al “front door criterio” y a veces ni aún así basta.
Pero tal y como empezaba el post. La inferencia causal no es más que predecir el efecto de la intervención. Y eso vamos a hacer.
En análisis bayesiano podemos ajustar el DAG entero y aún así estimar los efectos incluso condicionando por variable que los criterior de Pearl nos dicen que no se pueden. Esto lleva un coste computacional no despreciable si el DAG es complejo, de ahí lo de “luxury”.
Con las librerías brms y cmdstanr es relativamente sencillo ajustar este tipo de modelos
Show the code
# library(cmdstanr) # No me funciona cmdstanr al renderizar en quarto#set_cmdstan_path(path = "~/.cmdstan/cmdstan-2.34.1/")library(brms)library(ggdist) # pa pintar bf1 <-bf(M ~ S)bf2 <-bf(D ~ M )bf_full <- bf1 + bf2 +set_rescor(rescor =FALSE)mod_full_luxury <-brm( bf_full, chains =4,cores =4, iter =2000, data = df) #backend = "cmdstanr")
En el summary del modelo vemos que este modelo ha recuperado los coeficientes correctos.
Show the code
summary(mod_full_luxury)#> Family: MV(gaussian, gaussian) #> Links: mu = identity; sigma = identity#> mu = identity; sigma = identity #> Formula: M ~ S #> D ~ M #> Data: df (Number of observations: 100) #> Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;#> total post-warmup draws = 4000#> #> Regression Coefficients:#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS#> M_Intercept -0.09 0.14 -0.35 0.18 1.00 6248 3076#> D_Intercept 5.05 0.11 4.84 5.25 1.00 6264 2969#> M_S 2.31 0.22 1.88 2.75 1.00 6005 3074#> D_M 5.02 0.06 4.90 5.15 1.00 5702 2801#> #> Further Distributional Parameters:#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS#> sigma_M 1.09 0.08 0.95 1.26 1.00 5204 3058#> sigma_D 0.97 0.07 0.85 1.11 1.00 5868 3185#> #> Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS#> and Tail_ESS are effective sample size measures, and Rhat is the potential#> scale reduction factor on split chains (at convergence, Rhat = 1).
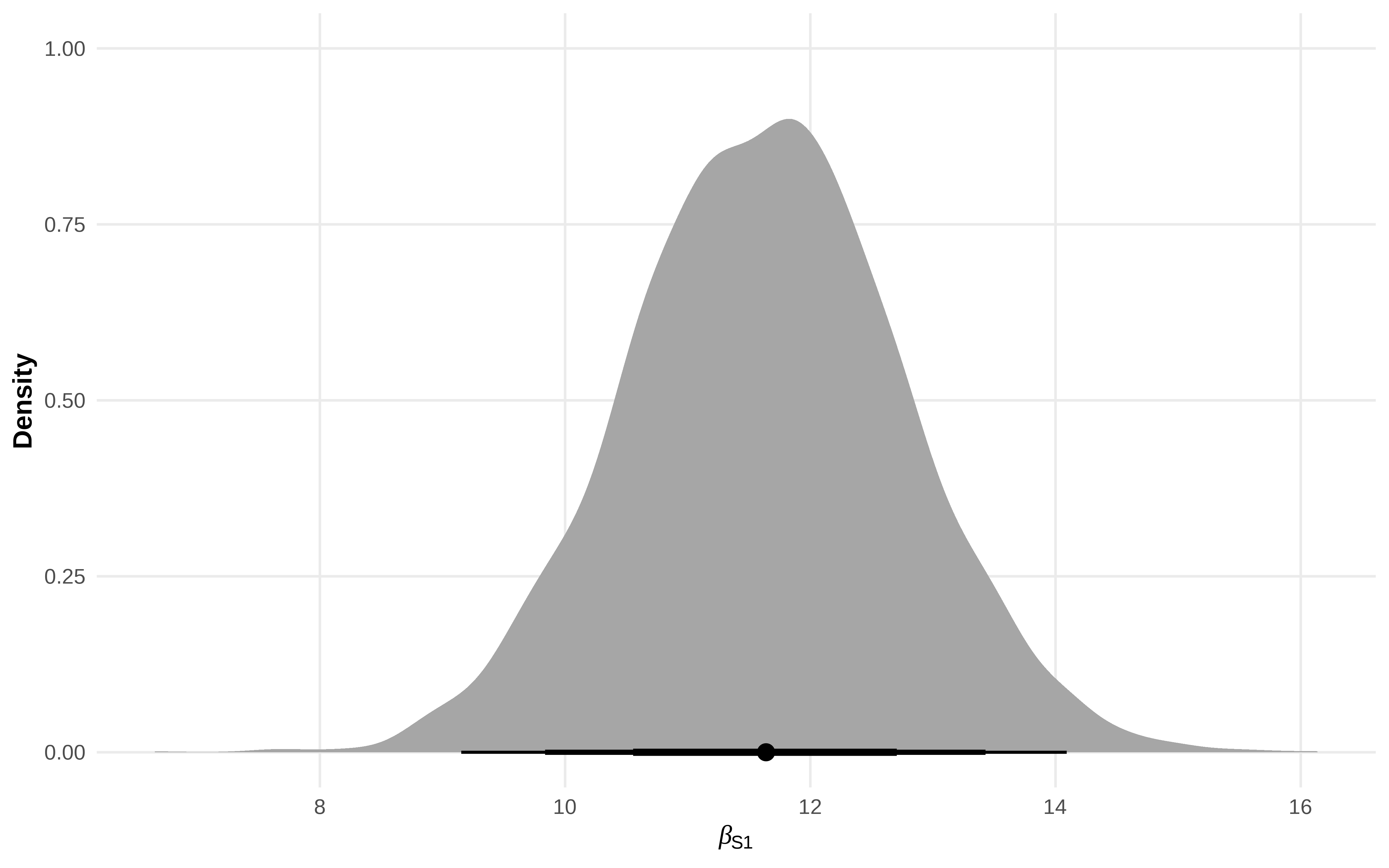
Una vez tenemos esto , podemos usar las posterior de dos forma. Una sería multiplicando las posteriors del coeficiente de M y el de S, y otra haciendo una “intervención”
Una vez tenemos el Dag estimado, podemos recorrerlo haciendo una intervención. Esto no es más que ver como sería el efecto cuando S= 0 y cuando S=1
El “truco” es que hay que recorrer el DAG y obteniendo las posteriors tras hacer la intervención.
Por ejemplo, la posterior del coeficiente de M no vale la que ha sacado el modelo, sino que hay que calcularla utilizando el primer modelo el de M ~ S, pero poniendo que S = 0, y usar esa posterior obtenida en el modelo D ~ M.
El efecto correcto se recupera ajustando el DAG completo y luego simulando una intervención. Tal y como dice Richard McElreath, la inferencia causal es predecir el efecto de la intervención.
Conclusión
La inferencia bayesiana nos permite ajustar un DAG completo e incluso ajustar por “colliders” o por variables no observadas. Esto puede ser útil cuando tenemos DAGs en los que no se puede obtener correctamente el efecto buscado , ya sea porque implica condicionar por variables que tengan el doble rol de “confounder” y de “colliders” en diferentes “paths” o por otros motivos. El “full luxury bayes” conlleva coste computacional elevado por lo que la estrategia debería ser la de usarlo sólo en caso necesario. Pero la verdad es que encuentro cierta belleza en ajustar todo el diagrama causal y luego simular la intervención.