Cuenta Matheus Facure Alves en este capítulo de Causal Inference for the Brave and True que hay buenos y malos controles en esto de la inferencia causal. Y no le falta razón, tenemos al bueno y al feo, pero yo quiero hablar del otro, no del malo, sino del bayesiano
Ejemplo
Para ilustrar lo de buenos y malos (yo llamaré feos) confounders Matheus usa unos datos simulados. Yo voy a usar el mismo proceso de generación de datos.
Usa el ejemplo de que eres un científico de datos en un equipo de recobro en una fintech. Y que tu tarea es estimar el impacto que tiene enviar un mail pidiendo a la gente que negocie su deuda. La variable repuesta es el importe de por pagar de los clientes morosos.
Vaya, resulta que la estimación no es muy precisa.
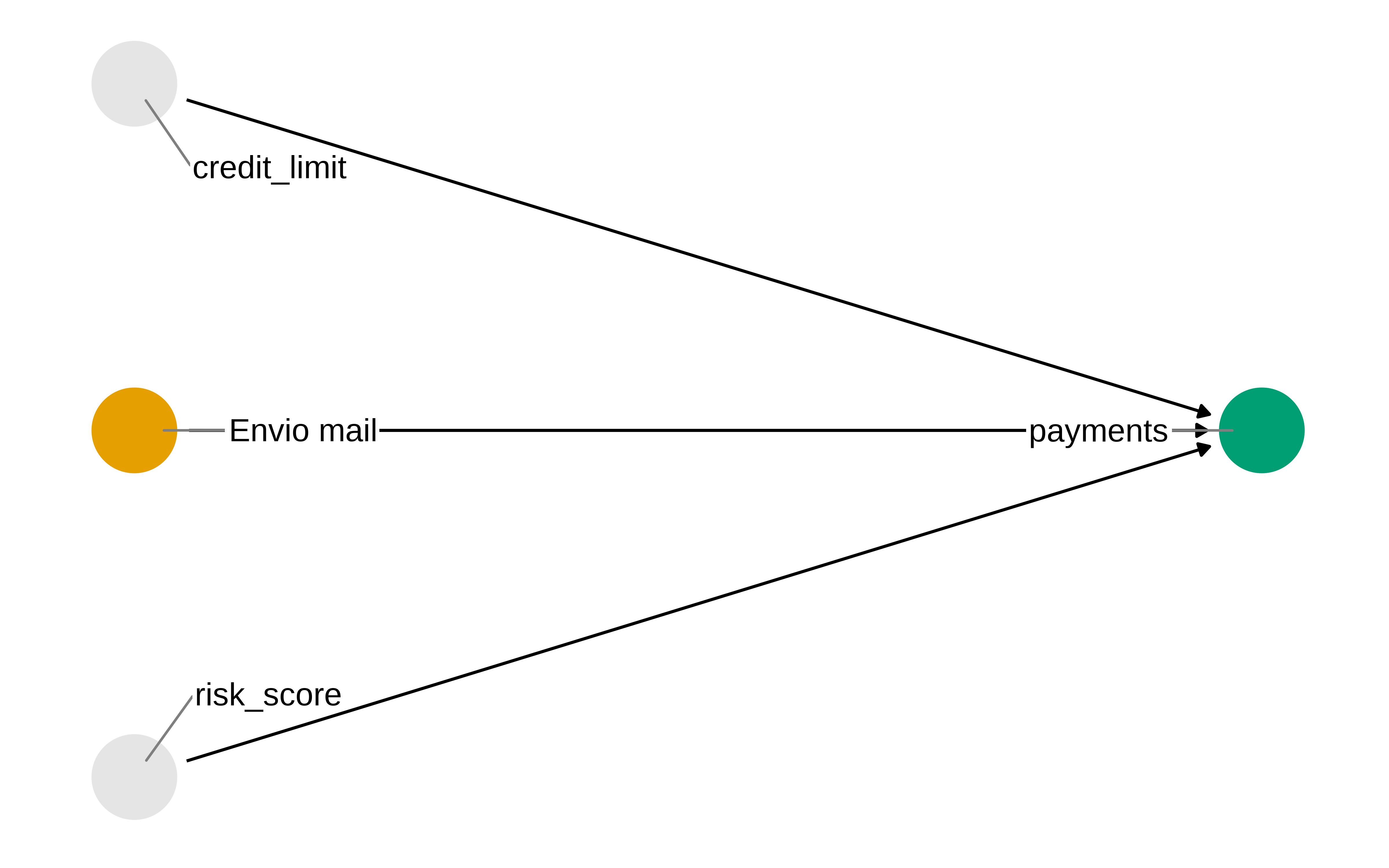
Podríamos pensar que las variables risk_score y credit_limit influyen en payments, al fin y al cabo, no se le va a dar un préstamo muy alto a quien tenga un alto risk_score. Así el dag podría ser este
Pues podríamos considerar que los amigos del bueno serían estas dos variables, risk_score y credit_limit. Que sabemos que no son necesarias para obtener una estimación insesgada del efecto causal, puesto que no son variables de confusión. No obstante son amigos del bueno porque al estar relacionadas con la respuesta (si nuestro modelo causal es correcto), incrementan la precisión de la estimación , tal y como vemos en el resultado del modelo siguiente.
m4<-brm(payments~email+credit_limit+risk_score , data =data, seed =44, chains =4, iter =3000, warmup =1000, cores =4, file =here::here("brms_stan_models/email2"))# hqy que evitar el exceso de decimales dando impresión de falsa exactitudround(posterior_summary(m4), 2)
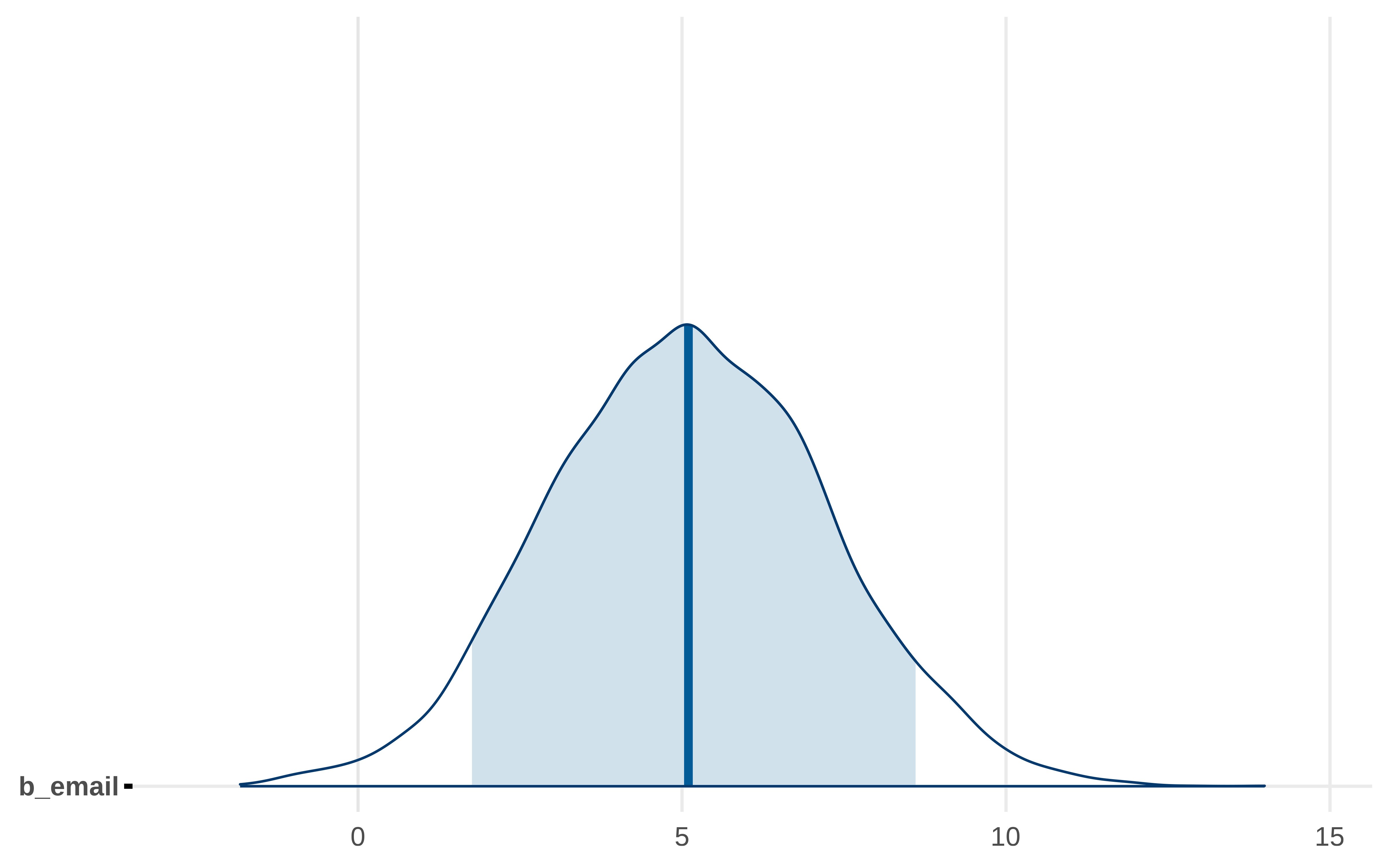
posteriors<-m4|>as_draws()bayesplot::mcmc_areas(posteriors, pars =c("b_email"), prob =0.89)
El malo feo
Ahora bien, y si nuestro modelo causal es de otra manera. Tal y como bien cuenta Carlos aquí hay un modelo mental (a priori) de como funcionan las causas. Y ese modelo es nuestra respuesta a la pregunta causal inversa, que no es otra que “¿qué causas han causado este efecto?”. A eso repondemos con por ejemplo un DAG causal. Pero ese DAG no es más que nuestra asunción, puede que no sea correcto. Otra cosa es medir el efecto de la intervención, que es lo que verás en todo lo que leas sobre inferencia causal.
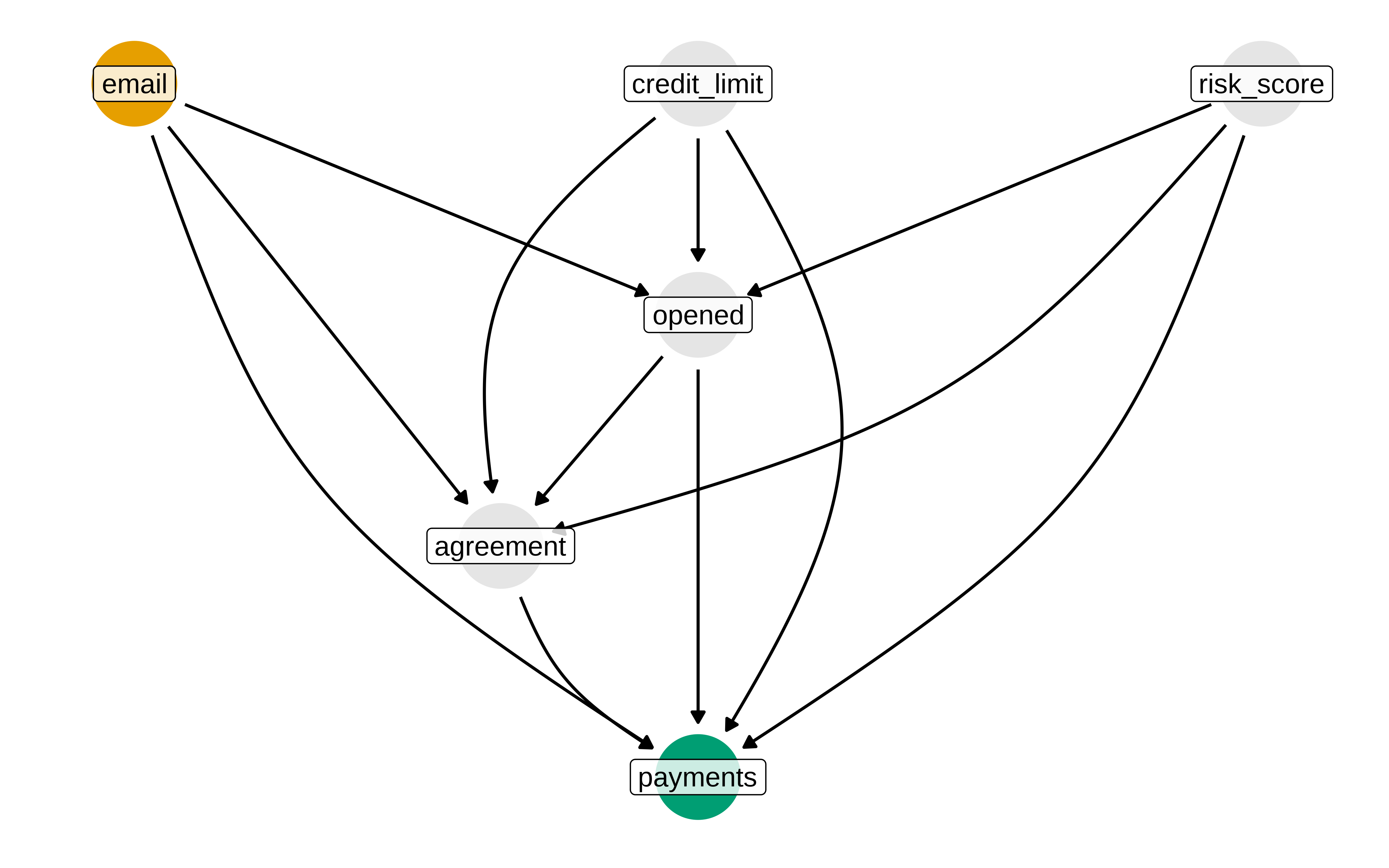
Bueno, dicho esto, supongamos que nuestro modelo de como funcionan las cosas es este
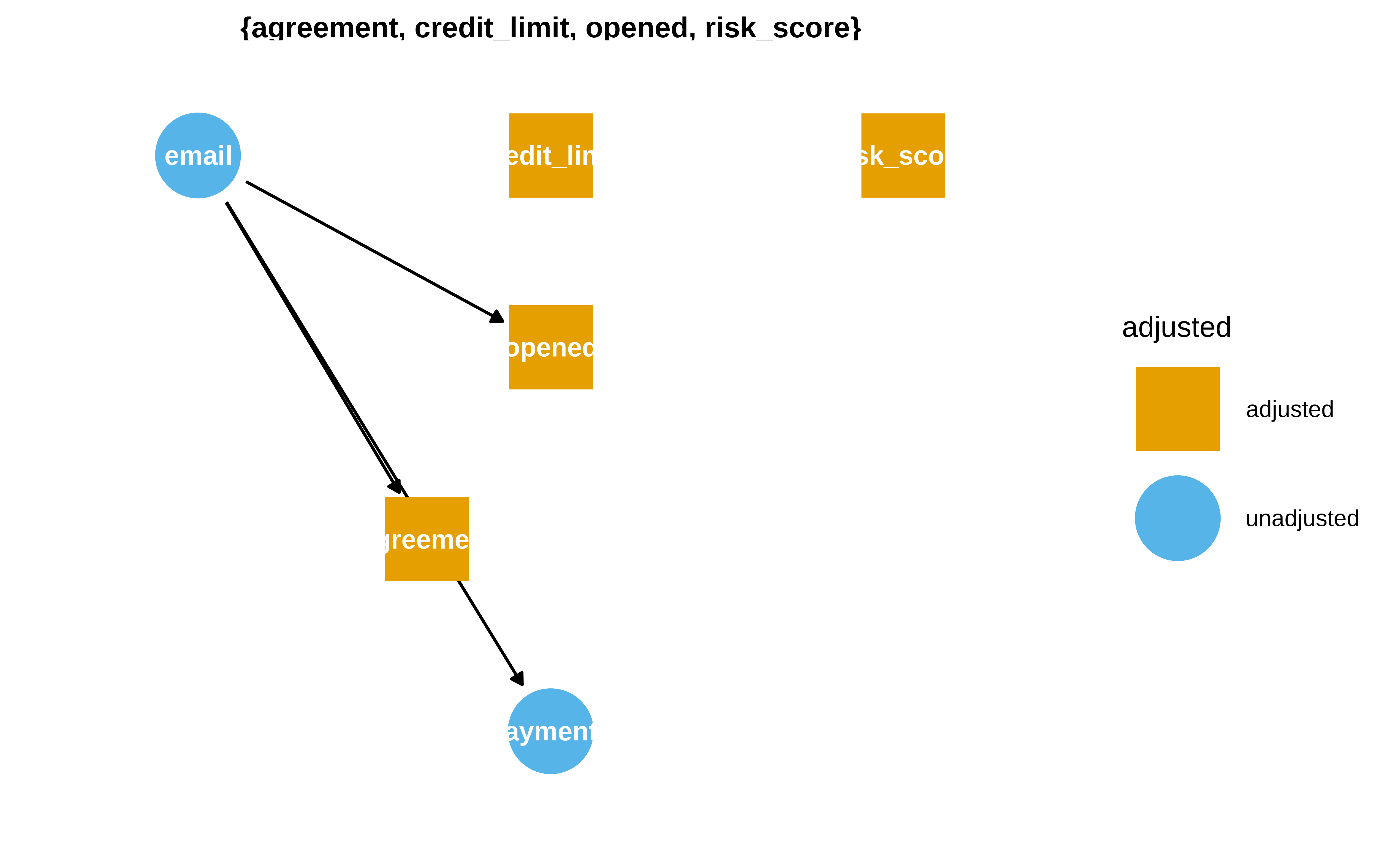
Matheus lo explica mejor que yo, pero lo que subyace es que abrir o no un mail depende claramente de si se lo han enviado, y seguramente quien ha recibido el mail y no lo ha abierto tiene comportamiento distinto de quién si lo ha abierto en cuánto al payments. También es plausible que distintos valores en risk_score o credit_limit influyan tanto en abrir o no un email de la fintech, como en la probabilidad de intentar llegar a uno acuerdo y también en en si pagas o no.
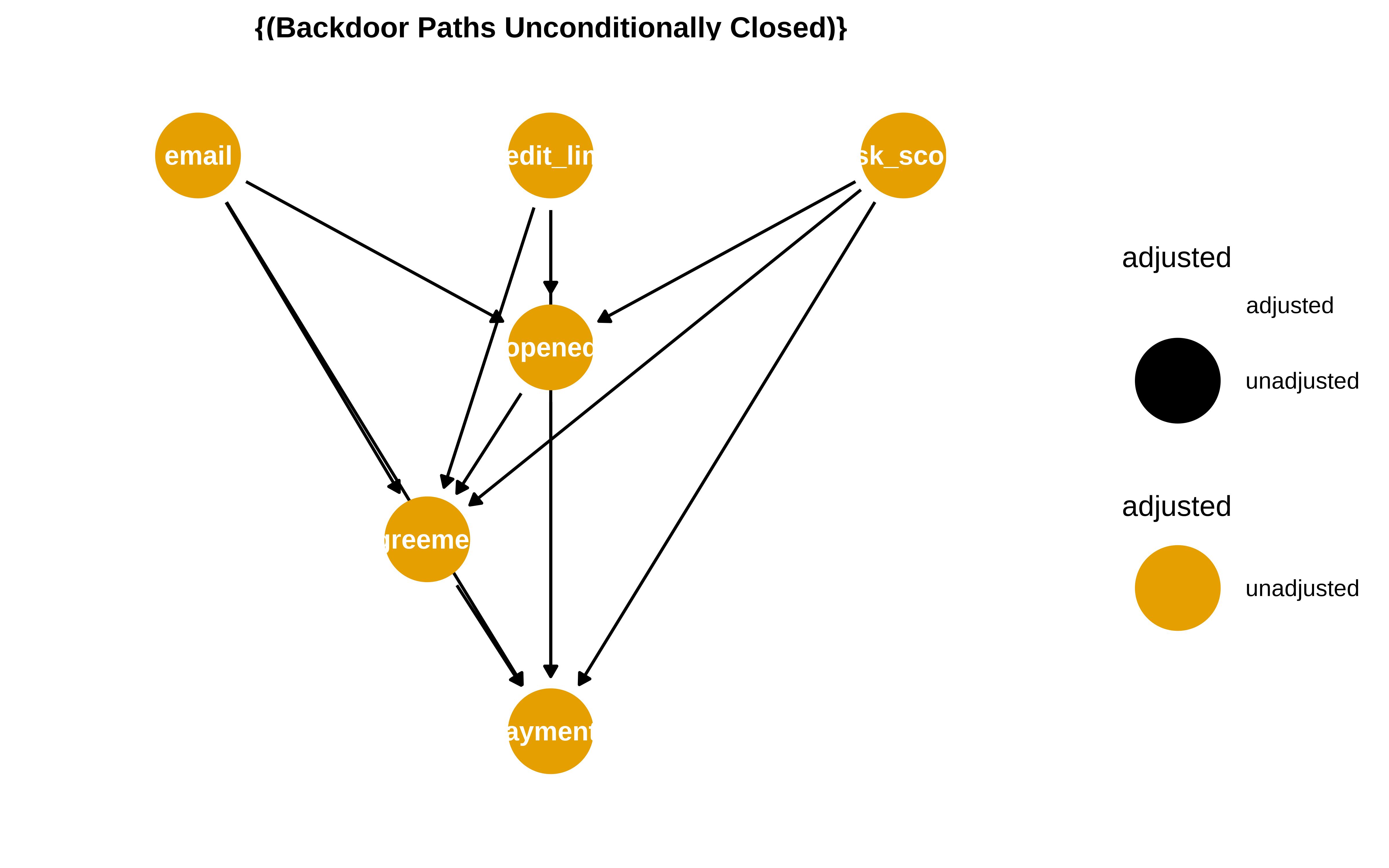
Ahora bien, dado este DAG, podríamos pensar en que para obtener el efecto total de email no hay que condicionar por nada, porque si condicionamos por opened al ser este una variable que hace de mediator se “descuenta” ese efecto global que pasa por opened en el coeficiente de email. Entonces Matheus dice que son malos controles si condicionamos por opened, agreement , credit_limit y ris_score , (se condiciona por estos dos últimos porque si no, se abre un path no causal ).
Pero claro, yo no diría que son malos, sino que depende de qué efecto quieres estimar. Para el efecto total no hay que condicionar por ellos, pero si parea ver el efecto directo. La librería dagitty nos ayuda en eso
Y vemos que la estimación del efecto directo de email es prácticamente 1. Y si nos vamos a como se han simulado los datos vemos que efectivamente el efecto directo es 1. Condicionar por las variables que hacen de mediadoras hacen que en el coeficiente que tenemos de email lo que se tenga sea el efecto que queda de email una vez descontado el efecto que pasa a través de las otras variables.
El bayesiano
Pero ¿y si ajustamos el dag completo a la vez?. En la inferencia causal que se suele enseñar se suele ajustar un solo modelo por pregunta causal. En este caso sería payments ~ email + credit_limit + risk_score para el efecto total y payments ~ email + agreement + opened + credit_limit + risk_score para el efecto directo.
Veamos como sería en inferencia bayesiana. Ajustamos todas las relaciones del DAG anterior
Show the code
# Especificar la fórmula con múltiples partes y distribucionesf1<-bf(payments~email+agreement+opened+credit_limit+risk_score, family =gaussian()# Asumimos que payments es continua, por lo tanto usamos la distribución normal)+bf(agreement~email+opened+credit_limit+risk_score, family =bernoulli("logit")# agreement es binaria (0 o 1), entonces usamos una distribución Bernoulli)+bf(opened~email+credit_limit+risk_score, family =bernoulli("logit")# opened es binaria (0 o 1), entonces usamos también una distribución Bernoulli)+set_rescor(FALSE)# No correlación entre las ecuaciones# Ajustar el modelo usando brms, tarda un rato, unos 13 minutos en mi pcm5<-brm(f1, data =data, seed =44, chains =4, iter =4000, warmup =1000, cores =4, file =here::here("brms_stan_models/email_flbi"), file_refit ="on_change")
Y vemos que el coeficiente b_payments_email es de nuevo la estimación correcta del efecto directo. En brms cuando se ajustan varios modelos a la vez, los coeficientes se suelen especificar como b_variable_respuesta_variable_explicativa.
Pero ahora vamos a la parte divertida. Una vez ajustado este modelo, ¿puedo usarlo para estimar el efecto total de email?
Pues si, si recordamos la inferencia causal no es más que el efecto de la intervención, así que hagamos una intervención. Recorramos el DAG partiendo de que todo el mundo tiene email=1 y usemos las posterioris para ir obteniendo las variables intermedias. Y luego hagamos lo mismo con email=0. En esta parte es dónde usaremos la función rvar de la librería posterior que nos va permitir trabajar con la matriz de las muestras mcmc en la posterior de forma sencilla.
Podemos ver por ejemplo la posterior del coeficiente de email en el modelo de payments. Al ser de tipo rvar nos la muestra como media y un más menos de la desviación típica, pero en ese objeto están los 12 mil valores de la posteriori
Show the code
post_rvars$b_payments_email
#> rvar<12000>[1] mean ± sd:
#> [1] 0.93 ± 2.7
Vamos a ir recorriendo el DAG. Simulamos el valor de la variable opened suponiendo que email = 1 para todos los individuos y luego suponemos que email = 0 para todos. Vamos utilizando las posterioris obtenidas en el modelo. Para email = 0 no hace falta hacer nada, puesto que si no envías el email no se puede abrir, por tanto opened cuando email = 0 es 0.
Pero opened es una variable dicotómica con valores 0 o 1 , por tanto voy a simular los valores de la variable. Como el modelo me lo devuelve en escala logit lo paso a probabilidades y simulo los valores
Show the code
# creo una version de rbinom que funcione con el tipo de dato rvarrvar_rbinom<-rfun(rbinom)opened_sim_1<-rvar_rbinom(nrow(data),1,inv_logit_scaled(p1_opened))opened_sim_1[1:5]
Seguimos recorriendo el DAG, de nuevo , una parte es que todo el mundo ha recibido un email y otra que nadie lo ha recibido.
Ahora predecimos la variable agreement, para cuando email = 1 usamos lo estimado en el paso anterior para la variable opened
Show the code
# predecir agreementp1_agreement_lineal<-with(post_rvars,b_agreement_Intercept+b_agreement_email*1+# intervencion email = 1b_agreement_opened*opened_sim_1+b_agreement_credit_limit*data$credit_limit+b_agreement_risk_score*data$risk_score)# para email = 0, opened es 0 p0_agreement_lineal<-with(post_rvars,b_agreement_Intercept+b_agreement_email*0+# intervencion email = 0b_agreement_opened*0+# si no hay mail no lo puede abrirb_agreement_credit_limit*data$credit_limit+b_agreement_risk_score*data$risk_score)# simulamos de nuevo los valores dicotómciosagreement_sim_1<-rvar_rbinom(nrow(data),1, inv_logit_scaled(p1_agreement_lineal))agreement_sim_0<-rvar_rbinom(nrow(data),1, inv_logit_scaled(p0_agreement_lineal))
Vemos claramente que parea los primeros 5 individuos , cuando intervenimos diciendo que todos han recibido el email, algunos tienen hasta una prob de 0.30 en media en agreement
Vamos a la última parte con la variable payments. Hacemos lo mismo, utilizamos los valores estimados en los pasos anteriores.
El siguiente paso es importante, puesto que puedo calcular dos cosas para cada observación. La distribución de su valor medio esperado cuando email = 1 o email = 0 y también puedo calcular la distribución de sus valores predichos.
La distribución de la media para cada individuo es mucho menos dispersa que la distribución de sus valores predichos. Es lo que se conoce como la posterior average prediction distribution en el primer caso o la posterior predictive distribution en el segundo.
y ahora la distribución de los valores predichos. Simplemente se simulan valores normales para cada observación, de forma que la media es la estimada en el paso anterior pero ponemos como desviación típica la posterior de la desviación típica de payments que nos ha dado el modelo bayesiano.
Show the code
# posterior_predict hay que incorporar la varianza de paymentsvar_rnorm<-rfun(rnorm)p1_payments_pp<-with(post_rvars,var_rnorm(nrow(data), b_payments_Intercept+b_payments_email*1+# intervencion email = 1b_payments_opened*opened_sim_1+b_payments_agreement*agreement_sim_1+b_payments_credit_limit*data$credit_limit+b_payments_risk_score*data$risk_score,sigma_payments))p0_payments_pp<-with(post_rvars,var_rnorm(nrow(data),b_payments_Intercept+b_payments_email*0+# intervencion email = 0b_payments_opened*0+b_payments_agreement*agreement_sim_0+b_payments_credit_limit*data$credit_limit+b_payments_risk_score*data$risk_score,sigma_payments))
y aquí vemos como para el primer individuo ambas distribuciones (cuando email = 1) tienen media similar, pero diferente desviación típica.
Show the code
p1_payments[1]
#> rvar<12000>[1] mean ± sd:
#> [1] 741 ± 7.3
Show the code
p1_payments_pp[1]
#> rvar<12000>[1] mean ± sd:
#> [1] 742 ± 76
Pues con esto ya nos podemos calcular para cada observación el CATE (conditional average treatment effect), pero con la ventaja de que podemos hacerlo sobre la distribución de las medias o sobre la distribución de los valores predichos.
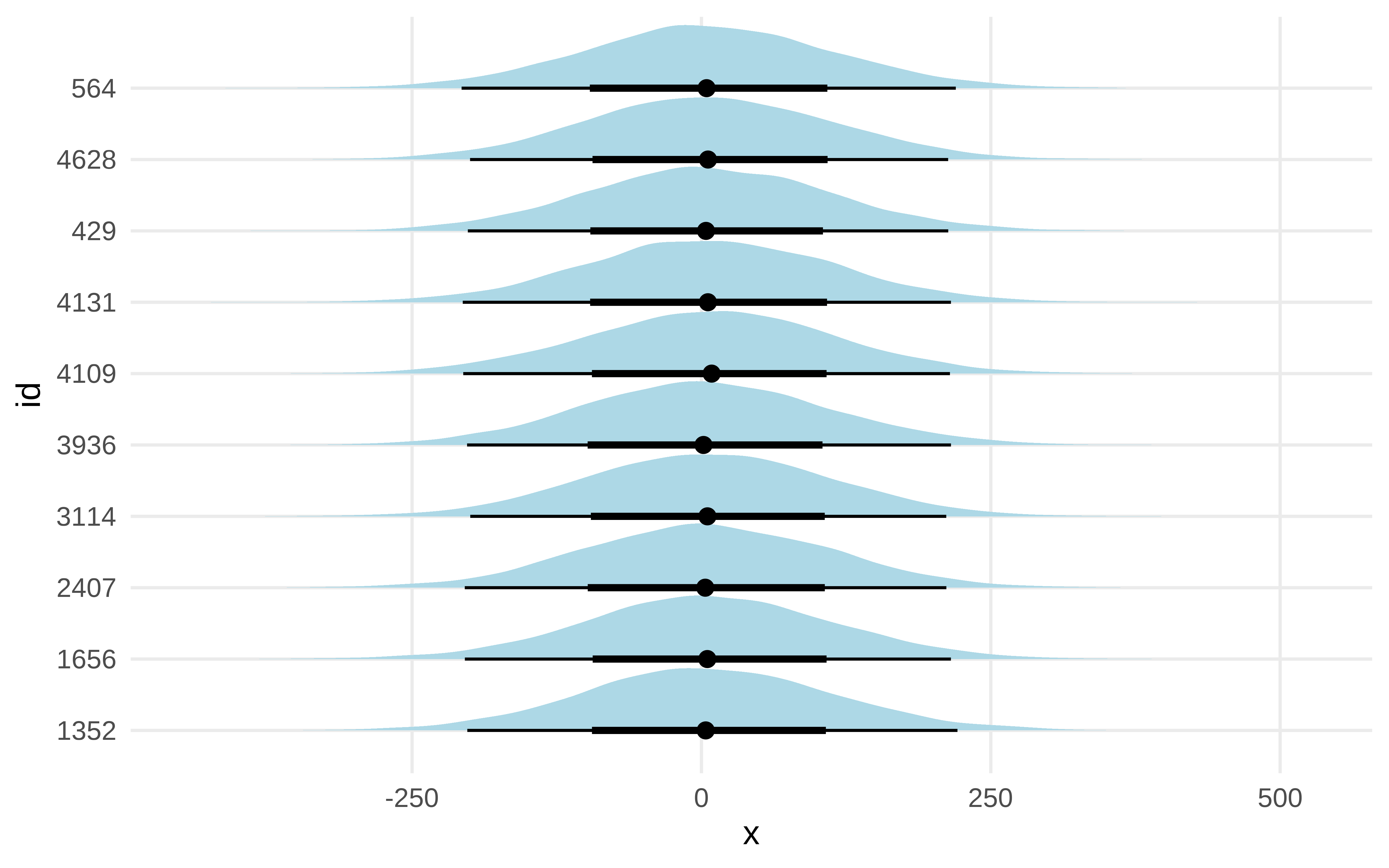
Y ahora vamos a pintar un poco. Vemos que la distribución a nivel individual de los valores predichos del cate es muy dispersa.
Show the code
sim<-data_with_cate|>sample_n(10)sim|>ggplot()+ggdist::stat_halfeye(aes( y =id, xdist =cate_ind_posterior_predict), fill ="lightblue")
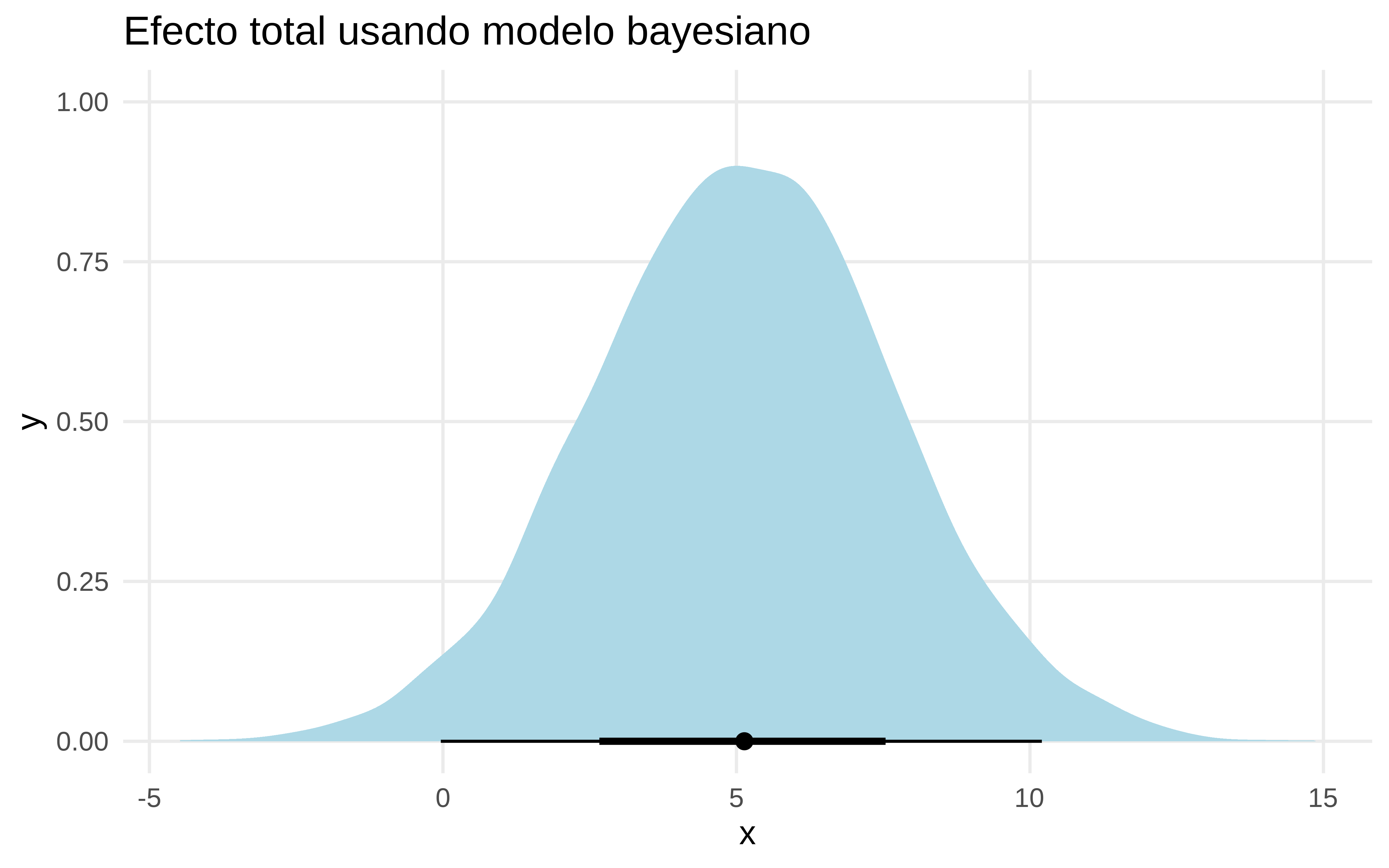
y podríamos ver la distribución del cate en la muestra. Podemos tomar medias de los cate individuales. Y vemos que de esta forma podemos recuperar el efecto “total”.
Show the code
data_with_cate|>summarise( cate_medio =rvar_mean(cate_ind_posterior_predict))|>ggplot()+ggdist::stat_halfeye(aes( xdist =cate_medio), fill ="lightblue")+labs(title="Efecto total usando modelo bayesiano")
Nota final
En inferencia causal podemos hacer un modelo para cada pregunta causal, o si usamos esta forma de hacerlo en bayesiano, podemos tener un solo modelo global y utilizando las posterioris responder a varias preguntas causales.
Adenda
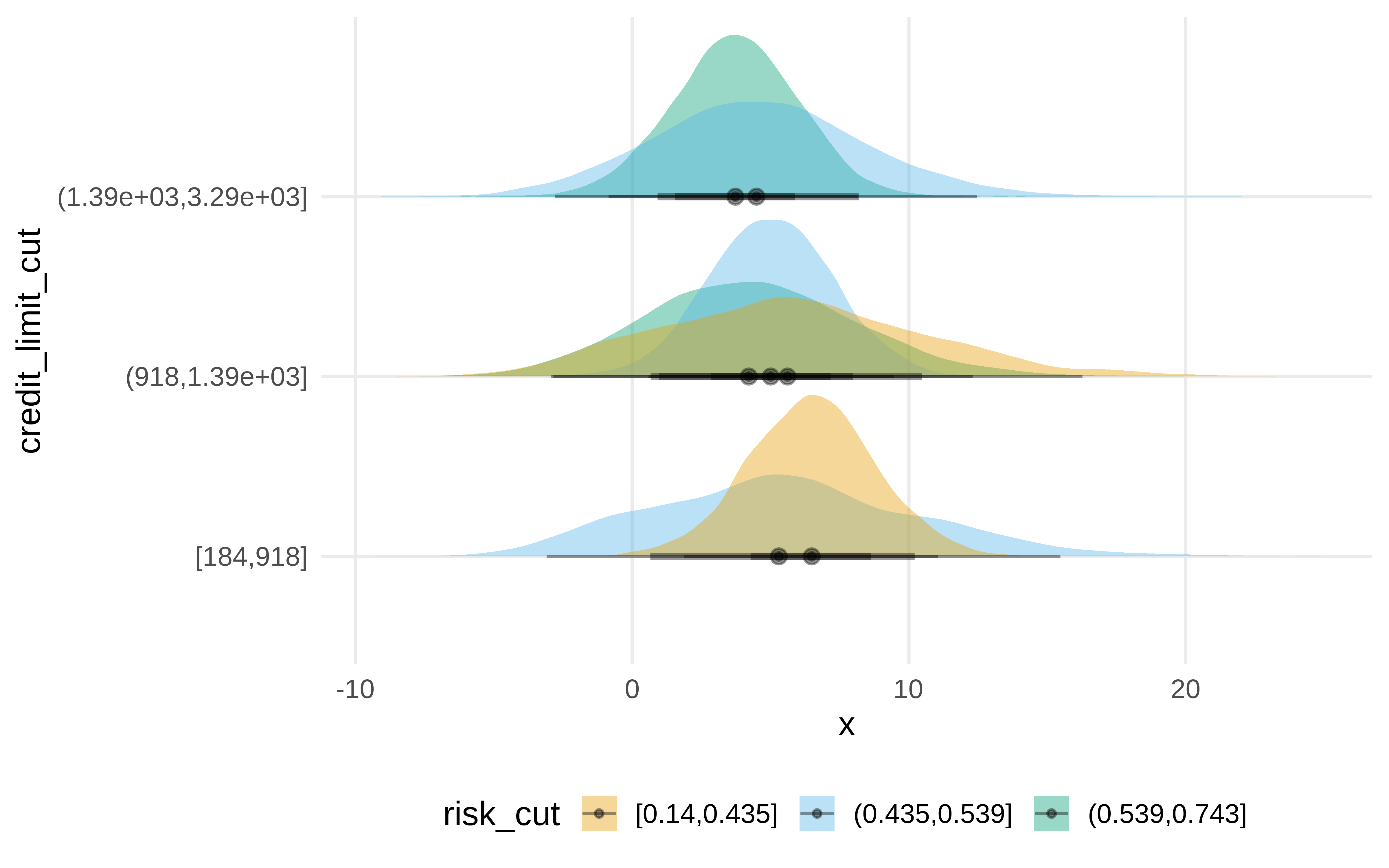
Al tener las posterioris, podemos de forma sencilla tener distribuciones de los efectos condicionando por las variables que queramos. Por ejemplo podemos ver como cambia el efecto según combinaciones de credit_limit y risk_score
---title: "El bueno, el feo y el bayesiano" date: '2024-09-19'categories: - 2024 - Inferencia causal - análisis bayesiano - Rdescription: ''execute: message: false warning: false echo: true output: trueformat: html: fig-height: 5 fig-dpi: 300 fig-width: 8 fig-align: center code-fold: true code-link: true code-summary: "Show the code" code-tools: true knitr: opts_chunk: out.width: 80% fig.showtext: TRUE comment: "#>"image: 'dag_completo.png'---::: callout-note## Listening<iframe style="border-radius:12px" src="https://open.spotify.com/embed/track/5pB2NnApayVJ6mvpa8XfjU?utm_source=generator" width="100%" height="250" frameBorder="0" allowfullscreen="" allow="autoplay; clipboard-write; encrypted-media; fullscreen; picture-in-picture" loading="lazy"></iframe>:::## IntroducciónCuenta Matheus Facure Alves en este capítulo de [Causal Inference for the Brave and True ](https://matheusfacure.github.io/python-causality-handbook/07-Beyond-Confounders.html#bad-controls-selection-bias) que hay buenos y malos controles en esto de la inferencia causal. Y no le falta razón, tenemos al bueno y al feo, pero yo quiero hablar del otro, no del malo, sino del __bayesiano__## Ejemplo Para ilustrar lo de buenos y malos (yo llamaré feos) confounders Matheus usa unos datos simulados. Yo voy a usar el mismo proceso de generación de datos. Usa el ejemplo de que eres un científico de datos en un equipo de recobro en una _fintech_. Y que tu tarea es estimar el impacto que tiene enviar un mail pidiendo a la gente que negocie su deuda. La variable repuesta es el importe de por pagar de los clientes morosos. El conjunto de datos luce tal que así```{r, setup_libraries}# algunas funciones para configurar ggplot y gggdag. El que quiera que visite mi githubsource(here::here("aux_functions/ggdag-mask.R"))source(here::here("aux_functions/setup.R"))library(tidyverse)library(dagitty)library(ggdag)library(ggokabeito)library(cmdstanr)library(brms)library(posterior) # para cosas como rvaroptions(brms.backend = "cmdstanr")``````{r}#| echo: falsedata <-read_csv(here::here("data/collections_email.csv"))DT::datatable(data, extensions ='Buttons', options =list(paging =TRUE,scrollX=TRUE, searching =TRUE,ordering =TRUE,dom ='Bfrtip',buttons =c('copy', 'csv', 'excel', 'pdf'),pageLength=5, lengthMenu=c(3,5,10) ))```La generación de los datos, copiada de Matheus es el siguiente```{r}#| eval: falsesemilla <-44n <-5000email <-rbinom(n = n, size =1, prob =0.5)credit_limit <-rgamma(n = n, shape =6, scale =200)risk_score <-rbeta(n= n, shape1 = credit_limit, shape2 =mean(credit_limit) )opened <-rnorm(n = n , mean =5+0.001* credit_limit -4* risk_score, sd =2 )opened <- (opened >4) * emailagreement <-rnorm(n = n, mean =30+(-0.003*credit_limit -10*risk_score), sd =7) *2* openedagreement <-as.integer(agreement >40)payments <-floor(rnorm(n = n , mean =500+0.16*credit_limit -40*risk_score +11*agreement + email, sd =75) /10) *10data <-data.frame( payments, email, opened, agreement, credit_limit, risk_score)write_csv(data, here::here("data/collections_email.csv"))```## El bueno y sus amigosSabemos que email ha sido generado aleatoriamente y por tanto podríamos estimar el efecto causal de forma simple```{r}m1 <-lm(payments ~ email, data = data)summary(m1)confint(m1, level =0.89)```Vaya, resulta que la estimación no es muy precisa. Podríamos pensar que las variables `risk_score` y `credit_limit` influyen en `payments`,al fin y al cabo, no se le va a dar un préstamo muy alto a quien tenga un alto `risk_score`. Así el dag podría ser este```{r}email_dag <-dagify( payments ~ email + credit_limit + risk_score,exposure ="email",outcome ="payments",labels =c(payments ="payments",email ="Envio mail",credit_limit ="credit_limit",risk_score ="risk_score" ),coords =list(x =c(payments =5,email =4,credit_limit =4,risk_score =4 ),y =c(payments =2,email =2,credit_limit =3,risk_score =1 )))email_dag |>tidy_dagitty() |>node_status() |>ggplot(aes(x, y, xend = xend, yend = yend, color = status) ) +geom_dag_edges() +geom_dag_point() +geom_dag_label_repel() +scale_color_okabe_ito(na.value ="grey90") +theme_dag() +theme(legend.position ="none") +coord_cartesian(clip ="off")```Pues podríamos considerar que los _amigos del bueno_ serían estas dos variables, `risk_score` y `credit_limit`. Que sabemos que no son necesarias para obtener una estimación insesgada del efecto causal, puesto que no son variables de confusión. No obstante son _amigos_ del bueno porque al estar relacionadas con la respuesta (si nuestro modelo causal es correcto), __incrementan la precisión de la estimación__ , tal y como vemos en el resultado del modelo siguiente. :::{.panel-tabset}#### Amigos frecuentistas```{r}m2 <-lm(payments ~ email + credit_limit + risk_score , data = data)summary(m2)confint(m2, level =0.89)```#### Amigos bayesianos```{r}m4 <-brm( payments ~ email + credit_limit + risk_score ,data = data,seed =44,chains =4,iter =3000,warmup =1000,cores =4,file = here::here("brms_stan_models/email2"))# hqy que evitar el exceso de decimales dando impresión de falsa exactitudround(posterior_summary(m4), 2) posteriors <- m4 |>as_draws()bayesplot::mcmc_areas(posteriors, pars =c("b_email"), prob =0.89)```:::## El ~~malo~~ feo Ahora bien, y si nuestro modelo causal es de otra manera. Tal y como bien cuenta Carlos [aquí](https://www.datanalytics.com/2024/09/10/causalidad/) hay un modelo mental (a priori) de como funcionan las causas. Y ese modelo es nuestra respuesta a la pregunta causal inversa, que no es otra que "¿qué causas han causado este efecto?". A eso repondemos con por ejemplo un DAG causal. Pero ese DAG no es más que nuestra asunción, puede que no sea correcto. Otra cosa es medir el efecto de la intervención, que es lo que verás en todo lo que leas sobre inferencia causal. Bueno, dicho esto, supongamos que nuestro modelo de como funcionan las cosas es este```{r}email_dag_full <-dagify( payments ~ email + agreement + opened + credit_limit + risk_score, agreement ~ email + opened + credit_limit + risk_score, opened ~ email + credit_limit + risk_score,exposure ="email",outcome ="payments",labels =c(payments ="payments",email ="Envio mail",agreement ="agreement",opened ="opened",credit_limit ="credit_limit",risk_score ="risk_score" ) ,coords =list(x =c(payments =2,email =0,credit_limit =2,risk_score =4,opened =2,agreement =1.3 ),y =c(payments =0,email =3,credit_limit =3,risk_score =3,opened =2,agreement =1 )))curvatures =c(-0.2,-0.3, 0, 0.3, 0, 0,-0.2, 0, 0, 0.2, 0, 0.2)email_dag_full |>tidy_dagitty() |>node_status() |>ggplot(aes(x, y, xend = xend, yend = yend, color = status) ) +geom_dag_edges_arc(curvature = curvatures) +geom_dag_point() +geom_dag_label(colour="black", size =4, alpha =0.8) +scale_color_okabe_ito(na.value ="grey90") +theme_dag() +theme(legend.position ="none") +coord_cartesian(clip ="off")```Matheus lo explica mejor que yo, pero lo que subyace es que abrir o no un mail depende claramente de si se lo han enviado, y seguramente quien ha recibido el mail y no lo ha abierto tiene comportamiento distinto de quién si lo ha abierto en cuánto al payments. También es plausible que distintos valores en _risk_score_ o _credit_limit_ influyan tanto en abrir o no un email de la fintech, como en la probabilidad de intentar llegar a uno acuerdo y también en en si pagas o no. Ahora bien, dado este DAG, podríamos pensar en que para obtener el efecto _total_ de email no hay que condicionar por nada, porque si condicionamos por _opened_ al ser este una variable que hace de _mediator_ se "descuenta" ese efecto global que pasa por opened en el coeficiente de _email_. Entonces Matheus dice que son malos controles si condicionamos por _opened_, _agreement_ , _credit_limit_ y _ris_score_ , (se condiciona por estos dos últimos porque si no, se abre un path no causal ). Pero claro, yo no diría que son malos, sino que depende de qué efecto quieres estimar. Para el efecto _total_ no hay que condicionar por ellos, pero si parea ver el efecto _directo_. La librería `dagitty` nos ayuda en esoPara el efecto total ```{r}ggdag_adjustment_set(email_dag_full, effect ="total") +theme_dag()```Para efecto directo```{r}ggdag_adjustment_set(email_dag_full, effect ="direct") +theme_dag()```Asi si hacemos el modelo condicionando. ```{r}m_email_ugly <-lm(payments ~ email + agreement + opened + credit_limit + risk_score,data = data)summary(m_email_ugly)confint(m_email_ugly, level =0.89)```Y vemos que la estimación del efecto __directo__ de email es prácticamente 1. Y si nos vamos a como se han simulado los datos vemos que efectivamente el efecto directo es 1. Condicionar por las variables que hacen de mediadoras hacen que en el coeficiente que tenemos de email lo que se tenga sea el efecto que queda de email una vez descontado el efecto que pasa a través de las otras variables.## El bayesianoPero ¿y si ajustamos el dag completo a la vez?. En la inferencia causal que se suele enseñar se suele ajustar un solo modelo por pregunta causal. En este caso sería `payments ~ email + credit_limit + risk_score` para el efecto total y `payments ~ email + agreement + opened + credit_limit + risk_score` para el efecto directo. Veamos como sería en inferencia bayesiana. Ajustamos todas las relaciones del DAG anterior```{r}# Especificar la fórmula con múltiples partes y distribucionesf1 <-bf( payments ~ email + agreement + opened + credit_limit + risk_score,family =gaussian() # Asumimos que payments es continua, por lo tanto usamos la distribución normal) +bf( agreement ~ email + opened + credit_limit + risk_score,family =bernoulli("logit") # agreement es binaria (0 o 1), entonces usamos una distribución Bernoulli ) +bf( opened ~ email + credit_limit + risk_score,family =bernoulli("logit") # opened es binaria (0 o 1), entonces usamos también una distribución Bernoulli ) +set_rescor(FALSE) # No correlación entre las ecuaciones# Ajustar el modelo usando brms, tarda un rato, unos 13 minutos en mi pcm5 <-brm( f1,data = data,seed =44,chains =4,iter =4000,warmup =1000,cores =4,file = here::here("brms_stan_models/email_flbi"),file_refit ="on_change")``````{r}round(posterior_summary(m5), digits =2)```Y vemos que el coeficiente b_payments_email es de nuevo la estimación correcta del efecto directo. En `brms` cuando se ajustan varios modelos a la vez, los coeficientes se suelen especificar como b_variable_respuesta_variable_explicativa.Pero ahora vamos a la parte divertida. Una vez ajustado este modelo, ¿puedo usarlo para estimar el efecto total de email? Pues si, si recordamos la inferencia causal no es más que el efecto de la intervención, así que hagamos una intervención. Recorramos el DAG partiendo de que todo el mundo tiene email=1 y usemos las posterioris para ir obteniendo las variables intermedias. Y luego hagamos lo mismo con email=0. En esta parte es dónde usaremos la función `rvar` de la librería `posterior` que nos va permitir trabajar con la matriz de las muestras mcmc en la posterior de forma sencilla. Lo primero es obtener las posteriores. ```{r}posteriores <-as_tibble(m5)post_rvars <-as_draws_rvars(posteriores)```Podemos ver por ejemplo la posterior del coeficiente de `email` en el modelo de `payments`. Al ser de tipo `rvar` nos la muestra como media y un más menos de la desviación típica, pero en ese objeto están los 12 mil valores de la posteriori```{r}post_rvars$b_payments_email```Vamos a ir recorriendo el DAG. Simulamos el valor de la variable `opened` suponiendo que email = 1 para todos los individuos y luego suponemos que email = 0 para todos. Vamos utilizando las posterioris obtenidas en el modelo. Para email = 0 no hace falta hacer nada, puesto que si no envías el email no se puede abrir, por tanto opened cuando email = 0 es 0. ```{r}p1_opened <-with(post_rvars, b_opened_Intercept + b_opened_email*1+# intervencion email = 1 b_opened_credit_limit * data$credit_limit + b_opened_risk_score* data$risk_score)# p0_opened <- with(post_rvars,# b_opened_Intercept +# b_opened_email* 0 + # intervencion email = 0# b_opened_credit_limit * data$credit_limit +# b_opened_risk_score* data$risk_score# # )```En p1_opened tiene de longitud 5000, hay una variable aleatoria para cada observación de los datos```{r}p1_opened |>length()```Y para cada observación tengo su variable aleatorio con 12000 valores. ```{r}p1_opened[1:5]```Pero opened es una variable dicotómica con valores 0 o 1 , por tanto voy a simular los valores de la variable. Como el modelo me lo devuelve en escala logit lo paso a probabilidades y simulo los valores ```{r}# creo una version de rbinom que funcione con el tipo de dato rvarrvar_rbinom <-rfun(rbinom)opened_sim_1 <-rvar_rbinom(nrow(data),1,inv_logit_scaled(p1_opened))opened_sim_1[1:5]```Seguimos recorriendo el DAG, de nuevo , una parte es que todo el mundo ha recibido un email y otra que nadie lo ha recibido. Ahora predecimos la variable agreement, para cuando `email` = 1 usamos lo estimado en el paso anterior para la variable `opened````{r}# predecir agreementp1_agreement_lineal <-with(post_rvars, b_agreement_Intercept + b_agreement_email*1+# intervencion email = 1 b_agreement_opened * opened_sim_1 + b_agreement_credit_limit * data$credit_limit + b_agreement_risk_score* data$risk_score )# para email = 0, opened es 0 p0_agreement_lineal <-with(post_rvars, b_agreement_Intercept + b_agreement_email*0+# intervencion email = 0 b_agreement_opened *0+# si no hay mail no lo puede abrir b_agreement_credit_limit * data$credit_limit + b_agreement_risk_score* data$risk_score )# simulamos de nuevo los valores dicotómciosagreement_sim_1 <-rvar_rbinom(nrow(data),1, inv_logit_scaled(p1_agreement_lineal))agreement_sim_0 <-rvar_rbinom(nrow(data),1, inv_logit_scaled(p0_agreement_lineal))```Vemos claramente que parea los primeros 5 individuos , cuando intervenimos diciendo que todos han recibido el email, algunos tienen hasta una prob de 0.30 en media en `agreement````{r}agreement_sim_1[1:5]agreement_sim_0[1:5]```Vamos a la última parte con la variable payments. Hacemos lo mismo, utilizamos los valores estimados en los pasos anteriores.El siguiente paso es importante, puesto que puedo calcular dos cosas para cada observación. La distribución de su valor medio esperado cuando email = 1 o email = 0 y también puedo calcular la distribución de sus valores predichos. La distribución de la media para cada individuo es mucho menos dispersa que la distribución de sus valores predichos. Es lo que se conoce como la posterior average prediction distribution en el primer caso o la posterior predictive distribution en el segundo. Calculamos la distribución de las medias```{r}## payments, media esperadap1_payments <-with(post_rvars, b_payments_Intercept + b_payments_email*1+# intervencion email = 1 b_payments_opened * opened_sim_1 + b_payments_agreement * agreement_sim_1 + b_payments_credit_limit * data$credit_limit + b_payments_risk_score* data$risk_score )p0_payments <-with(post_rvars, b_payments_Intercept + b_payments_email*0+# intervencion email = 0 b_payments_opened *0+ b_payments_agreement * agreement_sim_0 + b_payments_credit_limit * data$credit_limit + b_payments_risk_score* data$risk_score )```y ahora la distribución de los valores predichos. Simplemente se simulan valores normales para cada observación, de forma que la media es la estimada en el paso anterior pero ponemos como desviación típica la posterior de la desviación típica de `payments` que nos ha dado el modelo bayesiano. ```{r}# posterior_predict hay que incorporar la varianza de paymentsvar_rnorm <-rfun(rnorm)p1_payments_pp <-with(post_rvars,var_rnorm(nrow(data), b_payments_Intercept + b_payments_email*1+# intervencion email = 1 b_payments_opened * opened_sim_1 + b_payments_agreement * agreement_sim_1 + b_payments_credit_limit * data$credit_limit + b_payments_risk_score* data$risk_score, sigma_payments) )p0_payments_pp <-with(post_rvars,var_rnorm(nrow(data),b_payments_Intercept + b_payments_email*0+# intervencion email = 0 b_payments_opened *0+ b_payments_agreement * agreement_sim_0 + b_payments_credit_limit * data$credit_limit + b_payments_risk_score* data$risk_score, sigma_payments) )```y aquí vemos como para el primer individuo ambas distribuciones (cuando email = 1) tienen media similar, pero diferente desviación típica. ```{r}p1_payments[1]p1_payments_pp[1]```Pues con esto ya nos podemos calcular para cada observación el CATE (conditional average treatment effect), pero con la ventaja de que podemos hacerlo sobre la distribución de las medias o sobre la distribución de los valores predichos. ```{r}cate_ind_posterior_predict <- p1_payments_pp - p0_payments_ppcate_ind_posterior_average_predict <- p1_payments - p0_paymentsdata_with_cate <-data.frame(data, cate_ind_posterior_average_predict, cate_ind_posterior_predict) |>rownames_to_column(var ="id")head(data_with_cate)```Y ahora vamos a pintar un poco. Vemos que la distribución a nivel individual de los valores predichos del cate es muy dispersa. ```{r}sim <- data_with_cate |>sample_n(10)sim |>ggplot() + ggdist::stat_halfeye(aes( y = id, xdist = cate_ind_posterior_predict), fill ="lightblue")```y podríamos ver la distribución del cate en la muestra. Podemos tomar medias de los cate individuales. Y vemos que de esta forma podemos recuperar el efecto "total". ```{r}data_with_cate |>summarise(cate_medio =rvar_mean(cate_ind_posterior_predict)) |>ggplot() + ggdist::stat_halfeye(aes( xdist = cate_medio), fill ="lightblue") +labs (title="Efecto total usando modelo bayesiano")```## Nota finalEn inferencia causal podemos hacer un modelo para cada pregunta causal, o si usamos esta forma de hacerlo en bayesiano, podemos tener un solo modelo global y utilizando las posterioris responder a varias preguntas causales. ## AdendaAl tener las posterioris, podemos de forma sencilla tener distribuciones de los efectos condicionando por las variables que queramos. Por ejemplo podemos ver como cambia el efecto según combinaciones de credit_limit y risk_score```{r}data_with_cate |>sample_n(300) |>mutate(credit_limit_cut =cut_number(credit_limit, 3),risk_cut =cut_number(risk_score, 3) )|>group_by(credit_limit_cut, risk_cut) |>summarise(cate_medio =rvar_mean(cate_ind_posterior_average_predict) ) |>ggplot() + ggdist::stat_halfeye(aes(y = credit_limit_cut, xdist = cate_medio, fill = risk_cut), alpha =0.4)```