cmd <- "cat ~/proyecto_cachitos/2023_txt/00000035.jpg.subtitulo.tif.txt"
system(cmd, intern = TRUE)
#> [1] "ste tema se escribió con cartas de mujeres con cáncer de mama"
#> [2] ""
#> [3] "Si te ha tocado este año, lo de la amnistía igual lo relativizas."
#> [4] "\f"Cachitos 2023. Primera parte
estadística
polémica
2024
textmining
ocr
linux
cachitos
Como todos los años toca hacer el análisis de de los subtítulos de Nochevieja a Cachitos
Este año resulta que la gente de RTVE ha capado el poder bajarse los videos desde rtve usando curl o wget , pero gracias a Javi Fdez he podido bajarme el video tirando de la url del streaming .
Requisitos
- Un plugin en el navegador que pueda identificar el
m3uasociado al archivomp4del video de Cachitos que está en rtve play. Yo he usado live Stream Downloader , pero seguro que hay alguno mejor - Usar un sistema operativo GNU/Linux, en mi caso Linux Mint 21.2 basada en Ubuntu Jammy
ffmpegsudo apt install ffmpeg. ffmpeg nos va a servir para poder bajar el videomplayersudo apt install mplayer.mplayerconmplayervamos a extraer 1 de cada 200 fotogramas del videoimagemagickconsudo apt install imagemagick. Conimagemagickvamos a cambiar el tamaño de los fotogramas, recortar el área dónde están los subtítulos, convertir a formatotife invertir los colores para que el texto se vea mejor.parallelsudo apt install parallel. Conparallelvamos a poder utilizar varios núcleos e hilos del ordenador en paralelo y poder hacer la modificación de los fotogramas y el reconocimiento óptico de caracteres más rápido.tesseractsudo apt install tesseract-ocrysudo apt install tesseract-ocr-spa. Contesseractse va a hacer el reconocimiento óptico del texto y guardar en ficheros de texto.- Elimina ficheros de texto de menos de 10 bytes, puesto que ahí no hay texto .
Plugin
Con el plugin de Live Stream instalado en el navegador, lo primero que hacemos es ir a la web de rtveplay, buscar Nochevieja a Cachitos y darle al play. Estando en esa pestaña, le damos al plugin y nos abrirá una ventana emergente dónde se nos ha copiado la info del streaming. Esta info será útil porque es lo que nos va a permitir poder bajar el video usando ffmpeg
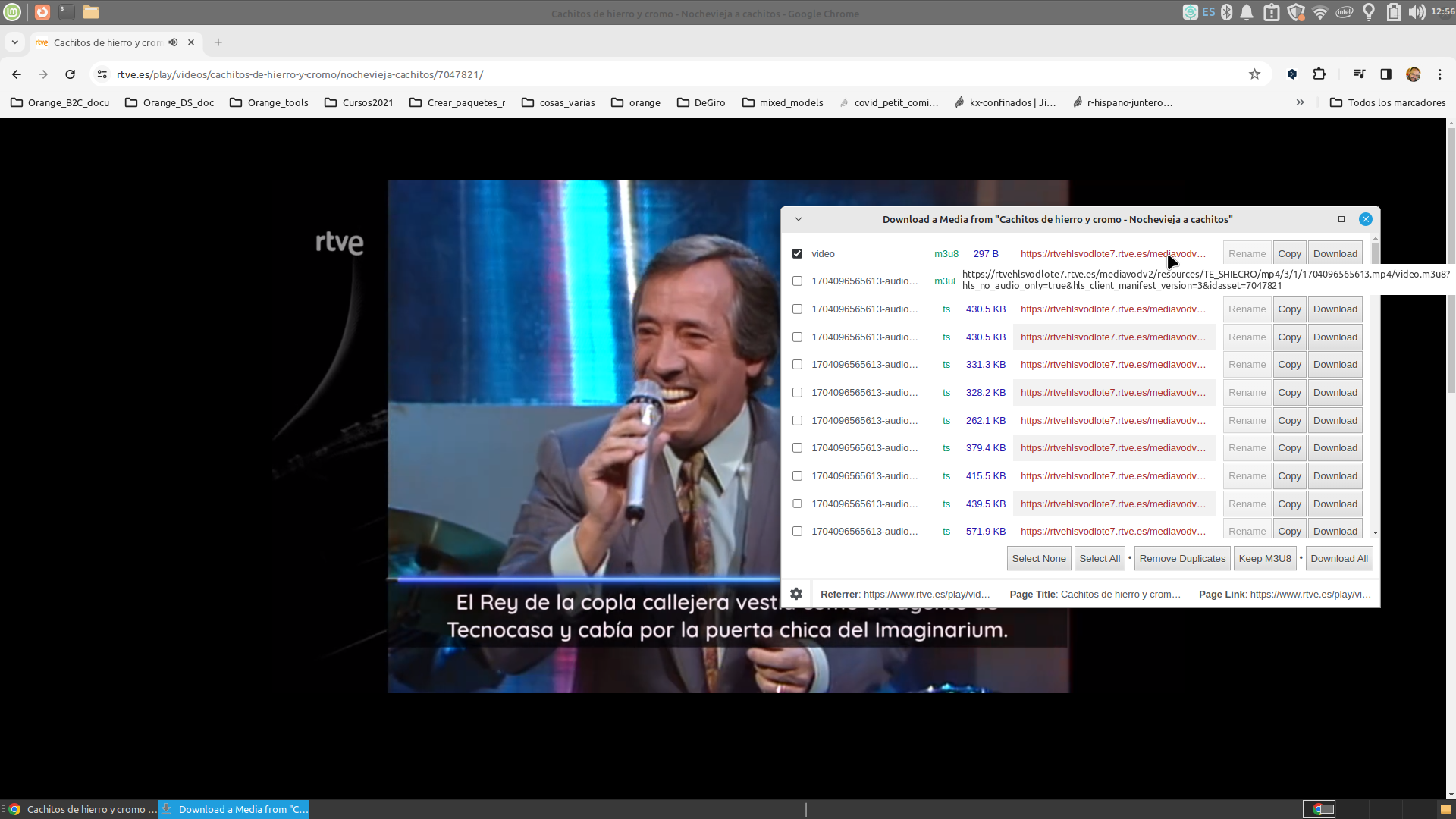
La info que nos da es algo como esto
https://rtvehlsvodlote7.rtve.es/mediavodv2/resources/TE_SHIECRO/mp4/3/1/1704096565613.mp4/1704096565613-audio=192755-video=2752986-3331.ts?idasset=7047821
En años anteriores me podía bajar directamente el archivo mp4 usando wget, pero este año nuestros amigos de rtve han decidido que no se puede.
Esto es lo que me sale al intentarlo
wget https://rtvehlsvodlote7.rtve.es/mediavodv2/resources/TE_SHIECRO/mp4/3/1/1704096565613.mp4
--2024-01-02 13:15:27-- https://rtvehlsvodlote7.rtve.es/mediavodv2/resources/TE_SHIECRO/mp4/3/1/1704096565613.mp4
Resolviendo rtvehlsvodlote7.rtve.es (rtvehlsvodlote7.rtve.es)... 151.101.134.137, 2a04:4e42:1f::649
Conectando con rtvehlsvodlote7.rtve.es (rtvehlsvodlote7.rtve.es)[151.101.134.137]:443... conectado.
Petición HTTP enviada, esperando respuesta... 403 Forbidden
2024-01-02 13:15:27 ERROR 403: Forbidden.Volviendo a la info que hemos obtenido usando el plugin, es importante identificar el idasset, en este caso el 7047821. Una vez sabemos eso, justo después de la parte dónde viene indicado el mp4, la cambiamos por esto
video.m3u8?hls_no_audio_only=true&hls_client_manifest_version=3&idasset=7047821 y ya podemos usar ffmpeg para guardar el archivo.
Son casi unos 4gb de video.
ffmpeg -i "https://rtvehlsvodlote7.rtve.es/mediavodv2/resources/TE_SHIECRO/mp4/3/1/1704096565613.mp4/video.m3u8?hls_no_audio_only=true&hls_client_manifest_version=3&idasset=7047821" -c copy video.mp4
Script de bash
El script es extract_subtitles.sh , se ejecutaría con extract_subtitles.sh 2023 .
Vamos a ir comentando el script poco a poco
Bajar video
Indicamos el nombre del directorio donde queremos trabajar, lo creamos y también creamos un subdirectorio llamado video , nos situamos en él y creamos algunas variables como el nombre del video cuando nos lo bajemos o como se van a llamar los directorios dónde vamos a ir guardando los fotogramas o el texto, típicamente 2023_jpg y 2023_txt. El script está puesto para que se le pase el año y se construya el
root_directory=/home/jose/proyecto_cachitos
mkdir -p $root_directory
cd $root_directory
echo "First arg: $1"
mkdir -p video
cd video
ANNO=$1
echo $ANNO
suffix_video="_cachitos.mp4"
suffix_jpg_dir="_jpg"
suffix_txt_dir="_txt"
video_file=$ANNO$suffix_video
echo $video_file
if [ "$ANNO" == "2023" ] ;
then
ffmpeg -i "https://rtvehlsvodlote7.rtve.es/mediavodv2/resources/TE_SHIECRO/mp4/3/1/1704096565613.mp4/video.m3u8?hls_no_audio_only=true&hls_client_manifest_version=3&idasset=7047821" -c copy $video_file
fiExtracción de fotogramas
Usando mplayer que sirve para reproducir el vídeo, podemos indicar además que nos extraiga una imagen cada 200 fotogramas framestep=200, también le decimos que lo reproduzca sin sonido y a velocidad alta y que guarde esos fotogramas como archivos jpeg en la ruta relativa `2023_jpg dentro de nuestro directorio principal.
Este es el comando que hace todo eso
mplayer -vf framestep=200 -framedrop -nosound $video_file -speed 100 -vo jpeg:outdir=$ANNO$suffix_jpg_dir Recorte de la zona de dónde está el rótulo
De años anteriores sé que si “achico” cada imagen anterior me vale de igual forma y por prueba y error vi en que parte de la imagen suelen colocar los rótulos. Así que con herramientas de imagemagick puedo manipular esas imágenes y extraer solo la zona del rótulo.
Reducción de la imagen
Cambiamos al directorio dónde hemos dejado las imágenes, y usando el comando find seleccionamos todos los archivos con extensión jpg y los reducimos a formato de 642x480.
Para eso usamos mogrify que forma parte de imagemagick y la parte de usar parallel es para que se ejecute en paralelo usando 8 hilos de cpu.
cd $ANNO$suffix_jpg_dir
# Convertir a formato más pequño
find . -name '*.jpg' | parallel -j 8 mogrify -resize 642x480 {}Seleccionar la zona dónde están los rótulos
Ahora usamos otras funciones de imagemagick que son convert y crop . Lo que hacemos es convertir a formato tif y recortamos justo la zona dónde están los rótulos.
Así, para cada imagen jpg creamos un archivo con nombre nombre_imagen.jpg.subtitulo.tif
# Seleccionar cacho dond están subtitulos
find . -name '*.jpg' | parallel -j 8 convert {} -crop 460x50+90+285 +repage -compress none -depth 8 {}.subtitulo.tifHacer el negativo de las imágenes
Para ayudar al software de reconocimiento óptico de caractereres obtenemos el negativo de cada tif. Para eso usamos de nuevo convert pero con la opción negate
# Poner en negativo para que el ocr funcione mejor
find . -name '*.tif' | parallel -j 8 convert {} -negate -fx '.8*r+.8*g+0*b' -compress none -depth 8 {}
Reconocimiento óptico de caracteres
Nosotros lo que queremos es tener el texto, no una imagen. Para eso utilizamos tesseract. Le pasamos cada una de las imágenes anteriores en formato tif y nos devolverá el texto que contienen. No siempre lo hará bien, pero el resultado es aceptable. También creamos directorio dónde vamos a mover todos los ficheros de texto creados y eliminamos los ficheros con menos de 10 bytes.
# Pasar el ocr con idioma en español
find . -name '*.tif' | parallel -j 8 tesseract -l spa {} {}
# mover a directorio texto
mkdir -p $root_directory/$ANNO$suffix_txt_dir
mv *.txt $root_directory/$ANNO$suffix_txt_dir
cd $root_directory/$ANNO$suffix_txt_dir
# Borrar archivos de 10 bytes , subtítulos vacíos, bytes se indican con la letra c, cosas de linux
find . -size -10c -exec rm -f {} \;Y podemos ver cómo ha convertido por ejemplo el rótulo asociado al fotograma 35.
Como vemos, la lógica de la creación de los ficheros de texto ha sido la de ir guardando el nombre original del fotograma e ir añadiendo extensiones, (.jpg, .subtitulo.tif, .txt).
Y sin más, os dejo también aquí el script entero
#!/bin/bash
root_directory=/home/jose/proyecto_cachitos
mkdir -p $root_directory
cd $root_directory
echo "First arg: $1"
mkdir -p video
cd video
ANNO=$1
echo $ANNO
suffix_video="_cachitos.mp4"
suffix_jpg_dir="_jpg"
suffix_txt_dir="_txt"
video_file=$ANNO$suffix_video
echo $video_file
if [ "$ANNO" == "2023" ] ;
then
ffmpeg -i "https://rtvehlsvodlote7.rtve.es/mediavodv2/resources/TE_SHIECRO/mp4/3/1/1704096565613.mp4/video.m3u8?hls_no_audio_only=true&hls_client_manifest_version=3&idasset=7047821" -c copy $video_file
fi
if [ "$ANNO" == "2022" ] ;
then
ffmpeg -i "https://rtvehlsvodlote7.rtve.es/mediavodv2/resources/TE_SHIECRO/mp4/1/5/1672556504451.mp4/video.m3u8?hls_no_audio_only=true&hls_client_manifest_version=3&idasset=6767615" -c copy $video_file
fi
# Pasar a jpg uno de cada 200 fotogramas
mplayer -vf framestep=200 -framedrop -nosound $video_file -speed 100 -vo jpeg:outdir=$ANNO$suffix_jpg_dir
cd $ANNO$suffix_jpg_dir
# Convertir a formato más pequño
find . -name '*.jpg' | parallel -j 8 mogrify -resize 642x480 {}
# Seleccionar cacho dond están subtitulos
find . -name '*.jpg' | parallel -j 8 convert {} -crop 460x50+90+285 +repage -compress none -depth 8 {}.subtitulo.tif
# Poner en negativo para que el ocr funcione mejor
find . -name '*.tif' | parallel -j 8 convert {} -negate -fx '.8*r+.8*g+0*b' -compress none -depth 8 {}
# Pasar el ocr con idioma en español
find . -name '*.tif' | parallel -j 8 tesseract -l spa {} {}
# mover a directorio texto
mkdir -p $root_directory/$ANNO$suffix_txt_dir
mv *.txt $root_directory/$ANNO$suffix_txt_dir
cd $root_directory/$ANNO$suffix_txt_dir
# Borrar archivos de 10 bytes , subtítulos vacíos
find . -size -10c -exec rm -f {} \;
cd $root_directoryAlgún ejemplo
library(tidyverse)
root_directory = "~/proyecto_cachitos/"
anno <- "2023"
library(magick)
(directorio_imagenes <- str_glue("{root_directory}video/{anno}_jpg/"))
#> ~/proyecto_cachitos/video/2023_jpg/
image_read(str_glue("{directorio_imagenes}00001297.jpg"))
image_read(str_glue("{directorio_imagenes}00001297.jpg.subtitulo.tif"))
(directorio_texto <- str_glue("{root_directory}{anno}_txt/"))
#> ~/proyecto_cachitos/2023_txt/
system(str_glue("cat {directorio_texto}00001297.jpg.subtitulo.tif.txt"), intern = TRUE)
#> [1] "Con el tiempo descubrimos que todas las letras de este"
#> [2] "exprofesor de Primaria tenian referencias sexuales."
#> [3] "\f"Y poco más, mañana intentaré tener elpost similar al del año pasado dónde veíamos distancias de texto entre rótulos y demás.