Vamos ya con la penúltima entrada del cachitos de este año. Las anteriores, las tenemos en esta y esta otra
El csv con el texto de los rótulos para 2023 lo tenemos en este enlace
Vamos al lío
Aviso:
Esta entrada ejecuta casi sin revisar la entrada de 2023 Lo poco que he cambiado es añadir alguna palabra polémica como amnistía o puigdemont al listado de palabras polémicas o hacer 5 topics en lugar de 7 en algún modelo
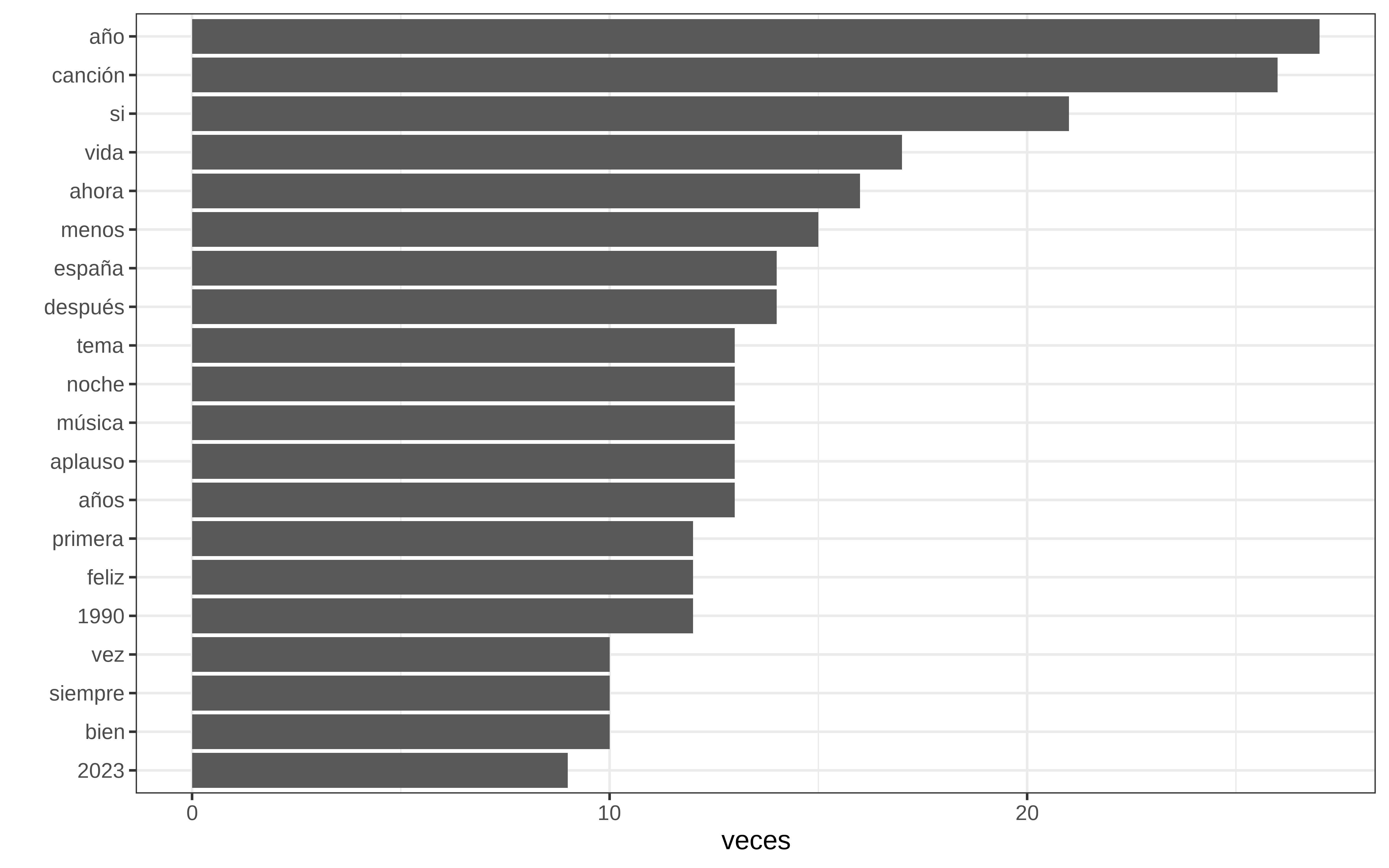
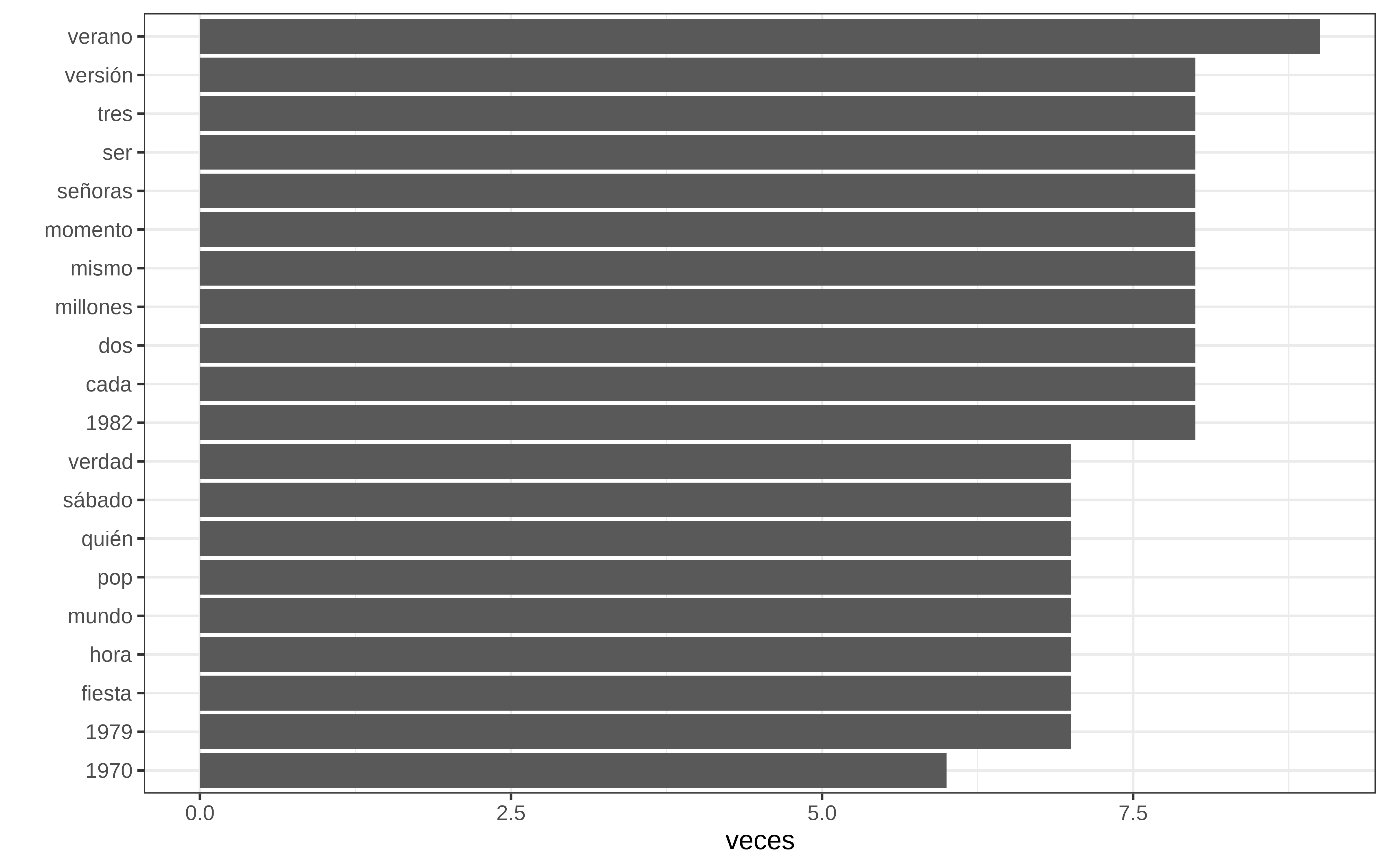
Y como el año pasado una de las palabras más comunes es “canción” . ¿Y si añadimos las 20 palabras como stopword, junto con algunas como [“tan”, “sólo”,“así”, “aquí”, “hoy”] . La tarea de añadir palabras como stopwords requiere trabajo, tampoco nos vamos a parar tanto.
Y podemos ver en el texto original antes de tokenizar qué rótulos hemos considerado polémicos y qué texto
Code
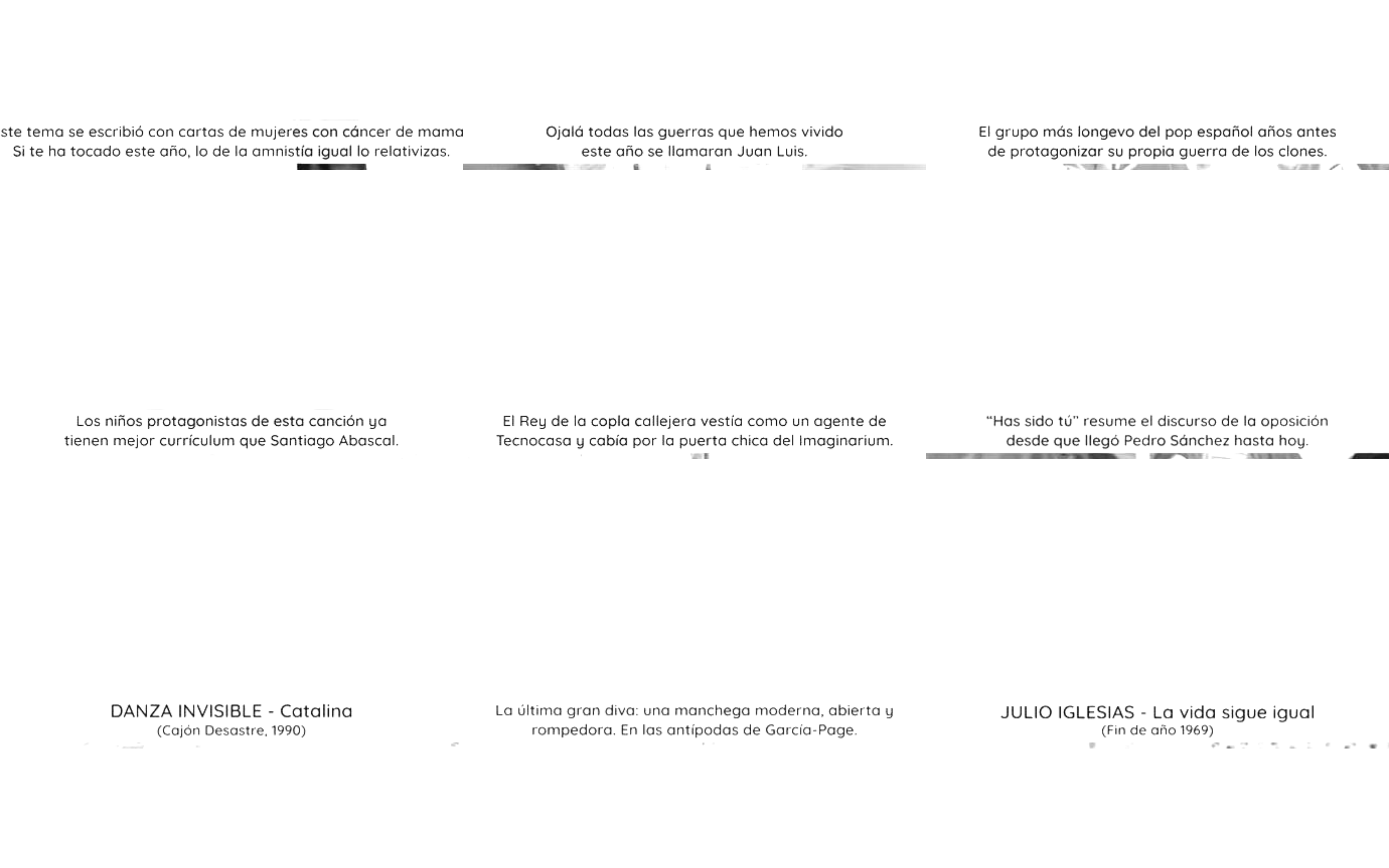
subtitulos_proces %>%filter(n_fichero %in% subtitulos_polemicos) %>%arrange(n_fichero) %>%pull(texto) %>%unique()#> [1] "ste tema se escribió con cartas de mujeres con cáncer de mama si te ha tocado este año lo de la amnistía igual lo relativizas" #> [2] "si no sabéis quién es quién toñi es la de la izquierda y encorna la que le da el chorro de aire acondicionado" #> [3] "el de la izquierda del todo ya no está en la coalición para algunos el chunguito verdadero" #> [4] "la de la izquierda hizo lo que todo padre sueña al mirar su whatsapp abandonar el grupo" #> [5] "quizá por eso se decía que estaba como un tren bueno en extremadura decían como un autobús" #> [6] "ana belén conoció a victor manuel al mismo tiempo que a julio iglesias ésta se la cantó a julio" #> [7] "la versión que habla de la relación de feijóo con el último resultado electoral se titula nosentera" #> [8] "a henry como a los ultras de las protestas contra la amnistía le gusta estar cara al sol" #> [9] "juan luis guerra 4 40 visa para un sueño pero esto qué es esto es lo que hay 1990" #> [10] "ojalá todas las guerras que hemos vivido este año se llamaran juan luis" #> [11] "vicente fernández y massiel el rey palmarés 1976" #> [12] "con todos los respetos a antonio josé esperábamos que el dúo de rufián fuera con junqueras" #> [13] "la pandemia creímos que formaban el dúo más estomagante gonzález y guerra han vuelto para recordarnos que no" #> [14] "el pp usó verano azul para su campaña el plan b era fariña o crematorio pero el resultado fue poco yo" #> [15] "el grupo más longevo del pop español años antes de protagonizar su propia guerra de los clones" #> [16] "en este año de crispación política la propuesta no de ley sobre alud mental logró 340 votos aún así seguimos sin una ley naciona"#> [17] "los niños protagonistas de esta canción ya tienen mejor currículum que santiago abascal" #> [18] "el rey de la copla callejera vestía como un agente de tecnocaso y cobía por la puerta chica del imaginarium" #> [19] "alejandro sanz viviendo deprisa ay vida mia 1992" #> [20] "lleva la camisa más abierta que las barreras de sánchez en una negociación de investidura" #> [21] "si puigdemont la hubiera pedido así la amnistía no sería tan impopular" #> [22] "9 de cada 10 españoles son como la cantudo odian planchar la otra es yolanda díaz" #> [23] "hablando de volcanes los afectados de la palma siguen intentando sacar adelante una ley nacional de volcanes" #> [24] "has sido tú resume el discurso de la oposición desde que llegó pedro sánchez hasta hoy" #> [25] "danza invisible catalina cajón desastre 1990" #> [26] "la última gran diva una manchega moderna abierta y rompedora en las antípodas de garcia page" #> [27] "este programa era como canal red con iglesias y montero siempre vigilantes" #> [28] "los reyes del eurodisco alemán también triunfaron en españa y eso que aquí competían con el tigretón y la pantera rosa" #> [29] "recordáis la corona del roscón que llevaba bobby farrell pues aqui tenéis el abba" #> [30] "ha sido la canción más enviada entre pp y psoe estos años aunque la versión definitiva ha sido para irene montero" #> [31] "alvaro benito jugaba en el real madrid se lesionó y se dedicó a la música como julio iglesias pero no" #> [32] "a compusieron en pandemia pensando que igual todo acababa no tendríamos que escucharla en bucle durante tres años" #> [33] "una mezcla entre un maniquí de una tienda de segunda mano y puigdemont después de sobrevivir a una pelea con junqueras" #> [34] "un homenaje a antonio gonzález el pescailla padre de la rumba catalana y de todos los hijos de lola flores" #> [35] "la canción habla de la margen izquierda del nervión el rio en el que desembocan los cinco océanos" #> [36] "un catalán puso de moda los campos de castilla y reivindicó que españa puede avanzar a golpes sin romperse" #> [37] "julio iglesias la vida sigue igual fin de año 1969"
Escribimos en un fichero los subtítulos polémicos , por si hago lo que estoy pensando hacer .
# identificamos nombre del archivo jpg con los rótulos polémicospolemica_1_fotogramas <-unique(substr(subtitulos_polemicos, 1,9))head(polemica_1_fotogramas)#> [1] "00000035." "00000059." "00000091." "00000114." "00000121." "00000222."# creamos la ruta completa donde estánpolemica_1_fotogramas_full <-paste0(str_glue("{root_directory}video/{anno}_jpg/"), polemica_1_fotogramas, "jpg")# añadimos sufijo subtitulo.tif para tenr localizado la imagen que tiene solo los rótulossubtitulos_polemicos_1_full <-paste0(polemica_1_fotogramas_full,".subtitulo.tif")
Con la función image_read del paquete magick leemos las imágenes polémicas y los rótulos
Ahora convertimos este data.frame a un DocumentTermMatrix
Code
# usamos como peso la TermFrequency de la palabrarotulos_dtm <- word_counts %>%cast_dtm(name, word, n, weighting = tm::weightTf)rotulos_dtm#> <<DocumentTermMatrix (documents: 583, terms: 2662)>>#> Non-/sparse entries: 3780/1548166#> Sparsity : 100%#> Maximal term length: 18#> Weighting : term frequency (tf)
Podríamos haberlo visto en forma de filas = palabras y columnas = rótulo
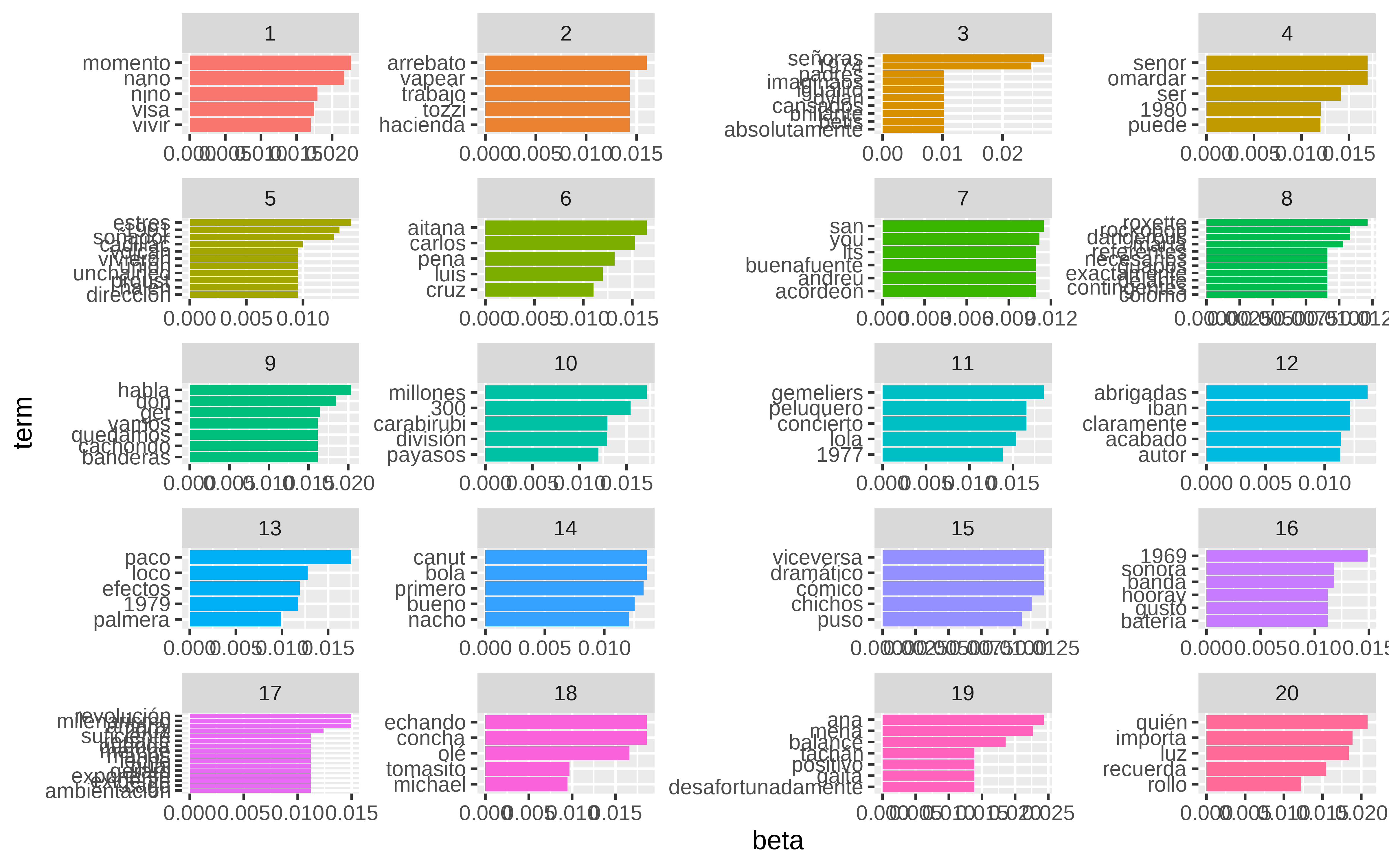
Como la función LDA no permite usar un DocumentTermMatrix que se haya construido con cast_dtm y usando como parámetro de weighting el peso tm::weightTfIdf nos construimos los datos de otra forma.
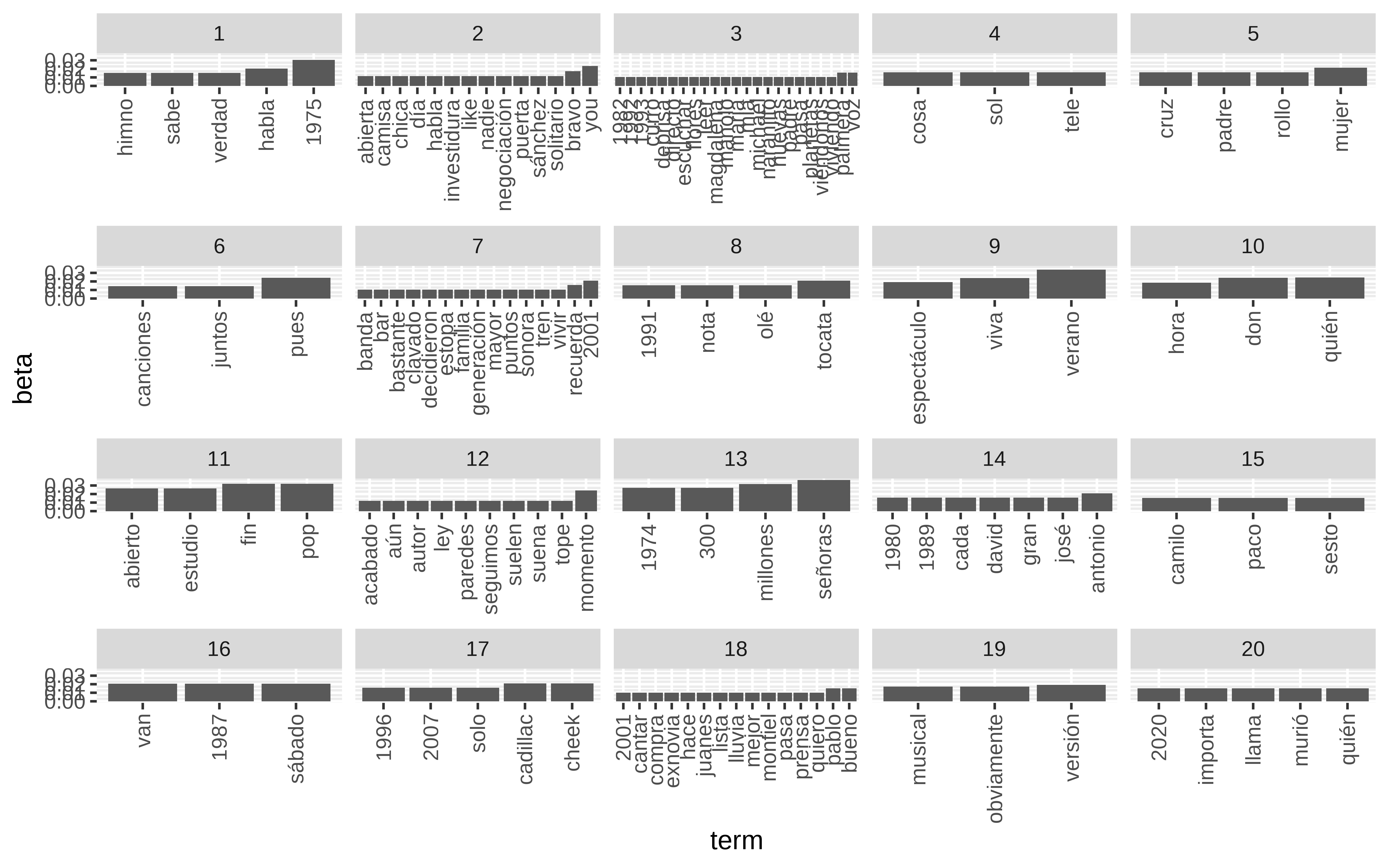
Y claramente , yo sigo sin ver nada claro. Aunque me daría pistas para añadir más palabras a las stopwords y para aceptar que para el tamaño de los documentos (unas pocas palabras por rótulo), quizá no valga el LDA.
Esta es la vida del analista de datos, prueba y error y sólo de vez en cuándo algún éxito.
Sólo con los rótulos polémicos
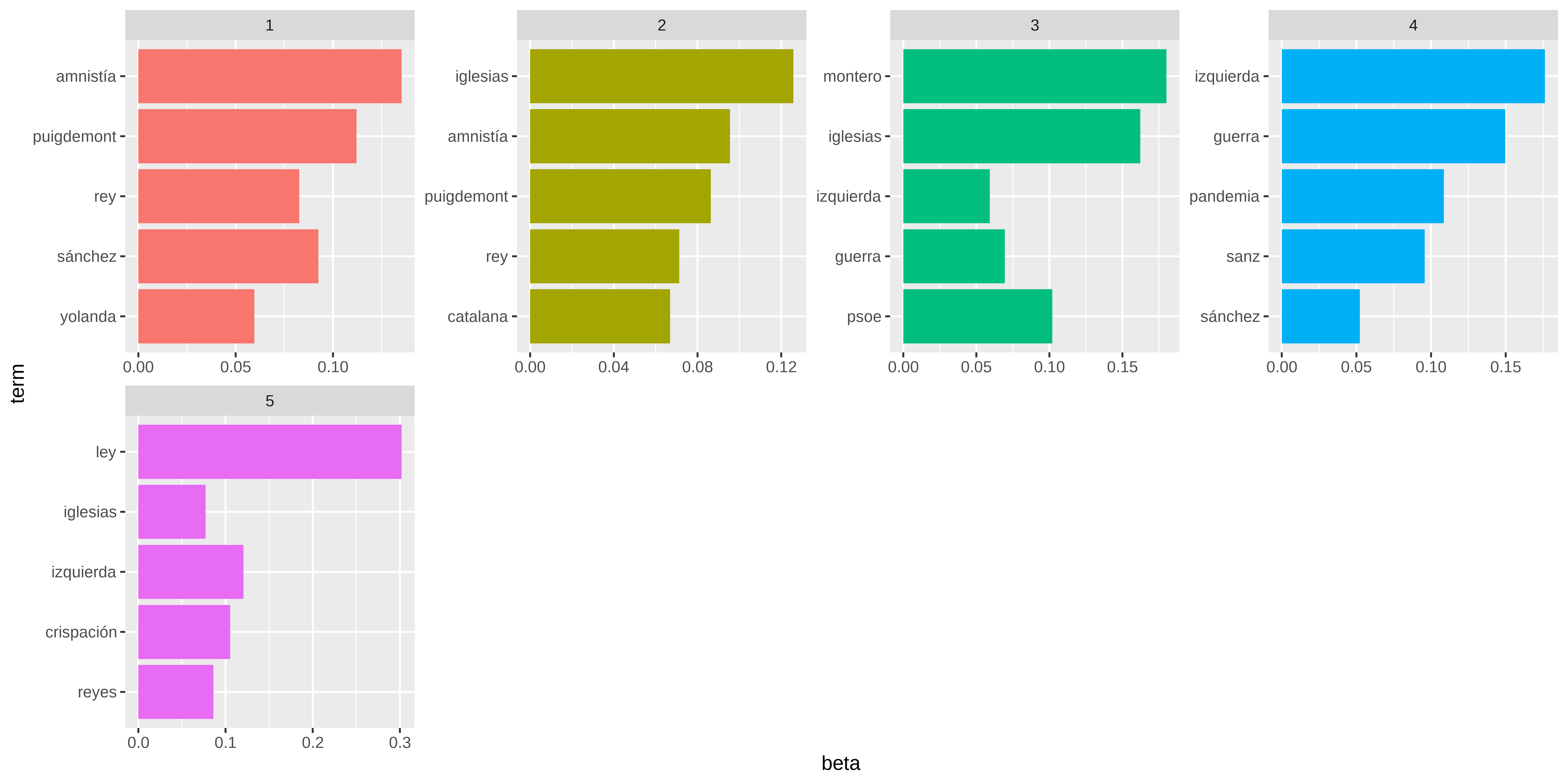
Asumiendo que parece que no tiene sentido hacer topicmodelling sobre estos datos, me picó la curiosidad de ver qué pasaba si sólo usaba los rótulos polémicos.
subtitulos_proces %>%filter(name %in%c(175, 385, 334, 598, 321, 13, 408)) %>%pull(texto)#> [1] "ste tema se escribió con cartas de mujeres con cáncer de mama si te ha tocado este año lo de la amnistía igual lo relativizas"#> [2] "a henry como a los ultras de las protestas contra la amnistía le gusta estar cara al sol" #> [3] "lleva la camisa más abierta que las barreras de sánchez en una negociación de investidura" #> [4] "si puigdemont la hubiera pedido así la amnistía no sería tan impopular" #> [5] "9 de cada 10 españoles son como la cantudo odian planchar la otra es yolanda díaz" #> [6] "has sido tú resume el discurso de la oposición desde que llegó pedro sánchez hasta hoy" #> [7] "una mezcla entre un maniquí de una tienda de segunda mano y puigdemont después de sobrevivir a una pelea con junqueras"
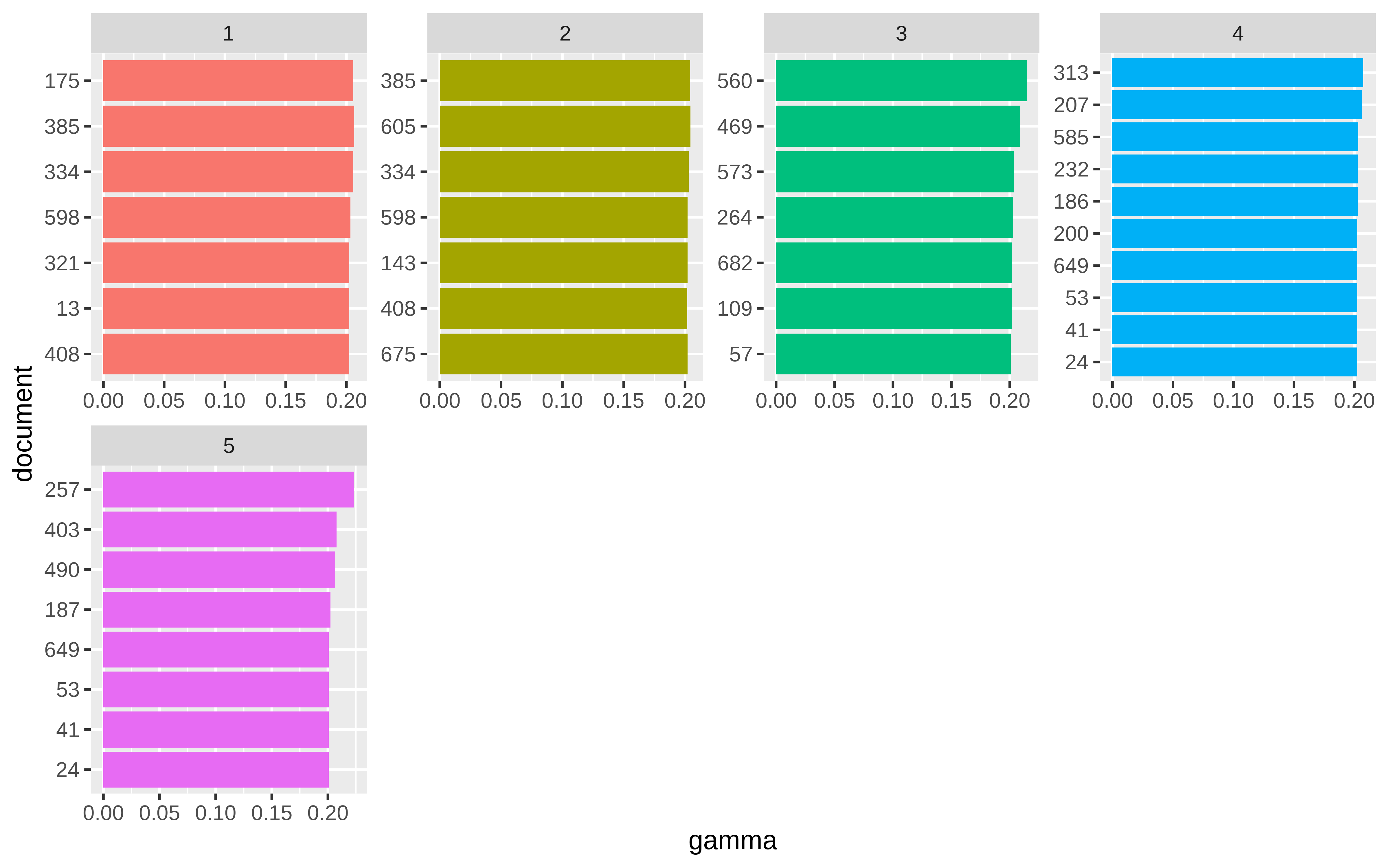
Veamos más documentos relacionados con este tópico
Code
top_10_topic3 <- result_documento_polem %>%group_by(topic) %>%top_n(12, gamma) %>%filter(topic==1) %>%pull(document)subtitulos_proces %>%filter(name %in% top_10_topic3) %>%pull(texto)#> [1] "ste tema se escribió con cartas de mujeres con cáncer de mama si te ha tocado este año lo de la amnistía igual lo relativizas"#> [2] "a henry como a los ultras de las protestas contra la amnistía le gusta estar cara al sol" #> [3] "ojalá todas las guerras que hemos vivido este año se llamaran juan luis" #> [4] "vicente fernández y massiel el rey palmarés 1976" #> [5] "con todos los respetos a antonio josé esperábamos que el dúo de rufián fuera con junqueras" #> [6] "el rey de la copla callejera vestía como un agente de tecnocaso y cobía por la puerta chica del imaginarium" #> [7] "lleva la camisa más abierta que las barreras de sánchez en una negociación de investidura" #> [8] "si puigdemont la hubiera pedido así la amnistía no sería tan impopular" #> [9] "9 de cada 10 españoles son como la cantudo odian planchar la otra es yolanda díaz" #> [10] "has sido tú resume el discurso de la oposición desde que llegó pedro sánchez hasta hoy" #> [11] "recordáis la corona del roscón que llevaba bobby farrell pues aqui tenéis el abba" #> [12] "una mezcla entre un maniquí de una tienda de segunda mano y puigdemont después de sobrevivir a una pelea con junqueras"
Y bueno si que parece que ha agrupado algunos rótulos relacionados con la amnistía
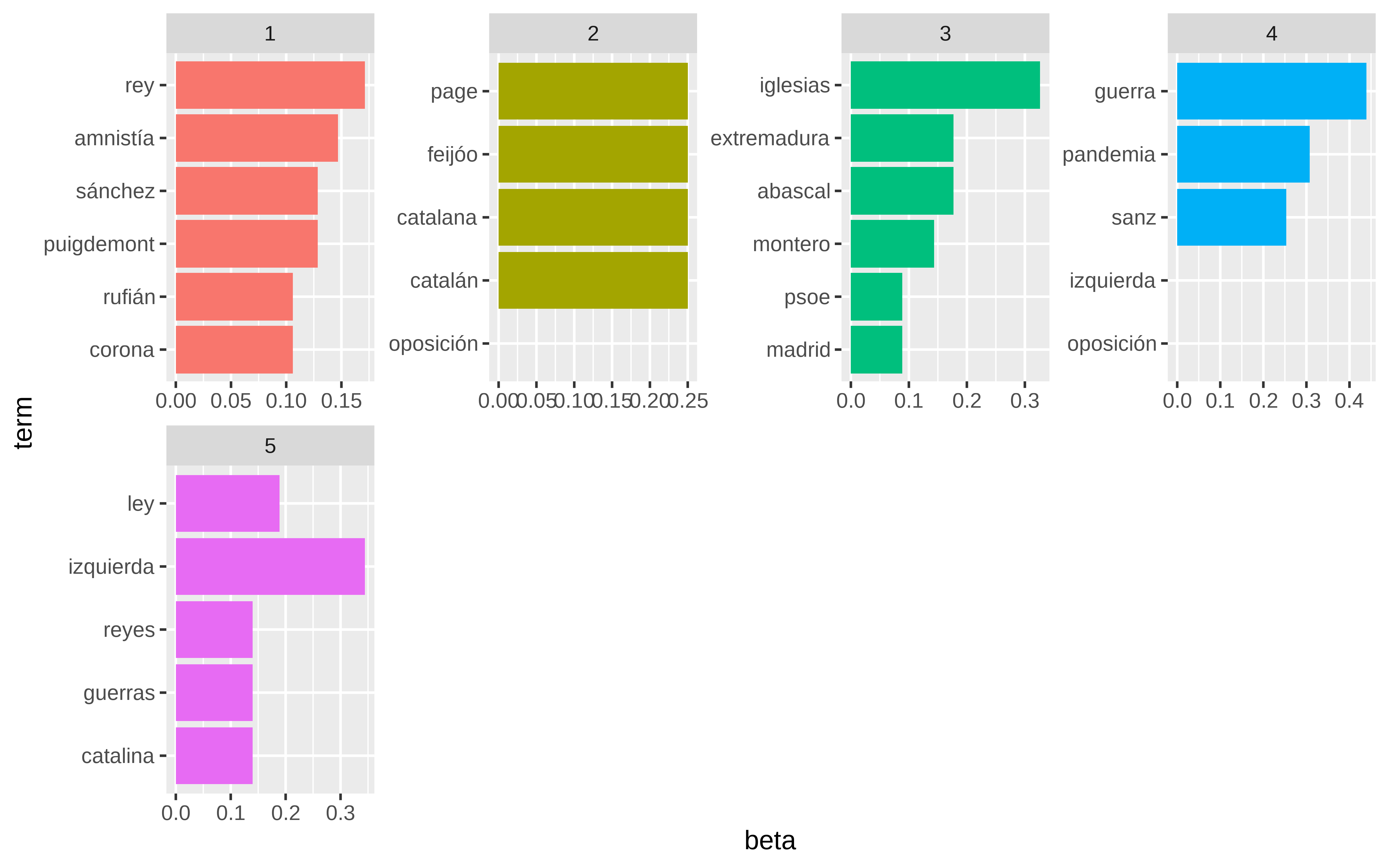
Topic modelling usando tf_idf
Code
dtm_long_polem_tf_idf <- tf_idf_data_polem %>%mutate(tf_idf_integer =round(100* tf_idf)) %>%cast_dfm(name, word, tf_idf_integer)lda_model_long_polem_tf_idf <-LDA(dtm_long_polem_tf_idf, k =5, control =list(seed =1234))result_polem_tf_idf <-tidy(lda_model_long_polem_tf_idf, 'beta')
En vez de considerar que cada rótulo es un documento, consideré los rótulos correspondientes a la primera parte del programa, a la segunda, y así hasta 10. pero no se obtuvo nada consistente
Y bueno aquí acaba el análisis del cachitos de este año, salvo que alguien tenga interés en que haga alguna prueba o mejore algo.
IA’s
Probando que me decía ChatGPT 3.5, (no tengo versión de pago). le he pasado la mitad de los rótulos de este año y le digo que me saque los 7 puntos más importantes y me devuelve esto.
Aquí están los 7 puntos más importantes del texto proporcionado:
Variedad de Temas y Artistas: El texto aborda una amplia variedad de temas y artistas de la música, tocando géneros y décadas diferentes.
Anécdotas y Curiosidades: Se presentan anécdotas y curiosidades sobre algunos artistas, como detalles sobre sus canciones, momentos destacados de sus carreras y datos interesantes.
Comentarios Irónicos y Humor: El texto utiliza un tono irónico y humorístico para comentar sobre diversos aspectos de la música y los artistas, proporcionando un enfoque entretenido.
Referencias Históricas y Culturales: Se realizan referencias a eventos históricos, políticos y culturales, situando a los artistas y sus obras en un contexto más amplio.
Comentarios Socio-políticos: Se incluyen comentarios que tocan temas sociales y políticos, como la referencia a la amnistía y menciones a personajes políticos.
Observaciones sobre la Industria Musical: El texto realiza observaciones sobre la industria musical, como la evolución de los formatos de música, la viralidad en las redes sociales y la temática de algunas canciones.
Diversidad de Géneros Musicales: Se abordan diversos géneros musicales, desde el pop y la música urbana hasta el rock y el flamenco, mostrando la diversidad en la escena musical española.
Luego he probado lo mismo usando Chat Arena que lo acabo de leer en el blog de Carlos Gil Bellosta y le he podido pasar todos los rótulos y el resultado de ChatGpt 4 y demás, me ha decepcionado bastante. Os animo a probarlo
Si hago una próxima entrada exploraré a ver si puedo conectarme a algún modelo de huggin face y ver qué tal lo hace.
Coda
En esta serie de post he dejado reflejado como bajar el video, extraer fotogramas, recortar rótulos, hacer ocrs y un pequeño análisis de los rótulos. Queda para cada cual discernir si los rótulos de este año se meten más con el gobierno, la oposición , los nacionalistas o con otros personajes. Sea como fuere en la serie de post se dan herramientas para que el que quiera realice su propio análisis y se forme una opinión propia.
Sin más, os deseo un Feliz 2024 a todos y espero el año que viene seguir cumpliendo con la ya casi tradición del análisis de Nochevieja a Cachitos